EconLogicQA: A Question-Answering Benchmark for Evaluating Large Language Models in Economic Sequential Reasoning

0
💬
Sign in to get full access
Overview
- Introduces EconLogicQA, a benchmark to assess the sequential reasoning capabilities of large language models in economics, business, and supply chain management
- Designed to be more challenging than traditional benchmarks by requiring models to discern and sequence multiple interconnected events
- Evaluations show EconLogicQA effectively measures a model's proficiency in navigating the sequential complexities of economic contexts
Plain English Explanation
The paper introduces a new benchmark called EconLogicQA, which is designed to test the ability of large language models (LLMs) to reason about sequential events in the realms of economics, business, and supply chain management. Unlike traditional benchmarks that focus on predicting individual events, EconLogicQA poses a more complex challenge: it requires models to understand the relationships between multiple interconnected events and put them in the correct order.
The benchmark consists of a variety of scenarios derived from economic articles, which demand an in-depth understanding of both the temporal and logical connections between different events. By thoroughly evaluating various leading-edge LLMs on this benchmark, the researchers aim to gain insights into the models' capabilities in handling the sequential complexities inherent in economic contexts.
The key idea behind EconLogicQA is to move beyond simple event prediction and instead assess a model's ability to navigate the intricacies of economic reasoning. This type of sequential reasoning is essential for understanding and anticipating the ripple effects of economic decisions and events, which is crucial for making informed business and policy decisions.
Technical Explanation
The paper introduces a novel benchmark called EconLogicQA, which is designed to evaluate the sequential reasoning capabilities of large language models (LLMs) in the domains of economics, business, and supply chain management. Unlike traditional benchmarks that focus on predicting individual events, EconLogicQA requires models to discern and sequence multiple interconnected events, capturing the inherent complexity of economic logics.
The benchmark comprises a diverse set of multi-event scenarios derived from economic articles, which necessitate a deep understanding of both temporal and logical relationships between events. Through comprehensive evaluations of various leading-edge LLMs, the researchers demonstrate that EconLogicQA effectively measures a model's proficiency in navigating the sequential complexities inherent in economic contexts.
The key distinction of EconLogicQA from other benchmarks is its emphasis on sequential reasoning, rather than individual event prediction. This shift in focus allows for a more nuanced assessment of a model's capabilities in understanding and anticipating the cascading effects of economic decisions and events, which is crucial for informed decision-making in business and policy domains.
The paper provides a detailed description of the EconLogicQA dataset and the outcomes of evaluating the benchmark across multiple state-of-the-art LLMs. This thorough analysis offers a comprehensive perspective on the sequential reasoning potential of these models in economic contexts.
Critical Analysis
The paper presents a well-designed and rigorous benchmark for assessing the sequential reasoning capabilities of large language models in economic, business, and supply chain management domains. The key strength of EconLogicQA is its focus on capturing the inherent complexity of economic logics, which goes beyond simple event prediction and requires a deeper understanding of the relationships between interconnected events.
One potential limitation of the benchmark, as acknowledged by the authors, is the relatively narrow scope of the scenarios, which are derived from economic articles. While this approach allows for a focused evaluation of economic reasoning, it may not fully capture the breadth of real-world economic and business decision-making, which can involve a wide range of factors and considerations.
Additionally, the paper does not delve into the potential biases or limitations of the large language models evaluated on the EconLogicQA benchmark. As these models are known to exhibit biases and inconsistencies in their reasoning [1, 2, 3], it would be valuable to explore how these issues manifest in the context of economic and business decision-making.
Further research could investigate the applicability of EconLogicQA to other domains, such as financial modeling or supply chain optimization, to broaden the benchmark's scope and relevance. Additionally, exploring ways to incorporate more diverse data sources and real-world economic scenarios could enhance the benchmark's ability to capture the full complexity of economic reasoning.
Conclusion
The introduction of EconLogicQA represents a significant step forward in the assessment of large language models' capabilities in the intricate realms of economics, business, and supply chain management. By shifting the focus from individual event prediction to sequential reasoning, the benchmark provides a more nuanced and comprehensive evaluation of a model's understanding of the interconnected nature of economic phenomena.
The findings from the evaluations conducted in this paper offer valuable insights into the current state of large language models' sequential reasoning potential in economic contexts. As these models continue to advance, the EconLogicQA benchmark can serve as a valuable tool for researchers and practitioners to monitor and improve the models' ability to navigate the complexities of economic decision-making, ultimately contributing to more informed and effective business and policy decisions.
[1] Evaluating Consistency and Reasoning Capabilities of Large Language Models [2] InflCoder: Systematically Evaluating the Capabilities of Large Language Models [3] DesignQA: A Multimodal Benchmark for Evaluating Large Language Models
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
EconLogicQA: A Question-Answering Benchmark for Evaluating Large Language Models in Economic Sequential Reasoning
Yinzhu Quan, Zefang Liu
In this paper, we introduce EconLogicQA, a rigorous benchmark designed to assess the sequential reasoning capabilities of large language models (LLMs) within the intricate realms of economics, business, and supply chain management. Diverging from traditional benchmarks that predict subsequent events individually, EconLogicQA poses a more challenging task: it requires models to discern and sequence multiple interconnected events, capturing the complexity of economic logics. EconLogicQA comprises an array of multi-event scenarios derived from economic articles, which necessitate an insightful understanding of both temporal and logical event relationships. Through comprehensive evaluations, we exhibit that EconLogicQA effectively gauges a LLM's proficiency in navigating the sequential complexities inherent in economic contexts. We provide a detailed description of EconLogicQA dataset and shows the outcomes from evaluating the benchmark across various leading-edge LLMs, thereby offering a thorough perspective on their sequential reasoning potential in economic contexts. Our benchmark dataset is available at https://huggingface.co/datasets/yinzhu-quan/econ_logic_qa.
Read more5/14/2024

0
EconNLI: Evaluating Large Language Models on Economics Reasoning
Yue Guo, Yi Yang
Large Language Models (LLMs) are widely used for writing economic analysis reports or providing financial advice, but their ability to understand economic knowledge and reason about potential results of specific economic events lacks systematic evaluation. To address this gap, we propose a new dataset, natural language inference on economic events (EconNLI), to evaluate LLMs' knowledge and reasoning abilities in the economic domain. We evaluate LLMs on (1) their ability to correctly classify whether a premise event will cause a hypothesis event and (2) their ability to generate reasonable events resulting from a given premise. Our experiments reveal that LLMs are not sophisticated in economic reasoning and may generate wrong or hallucinated answers. Our study raises awareness of the limitations of using LLMs for critical decision-making involving economic reasoning and analysis. The dataset and codes are available at https://github.com/Irenehere/EconNLI.
Read more7/2/2024
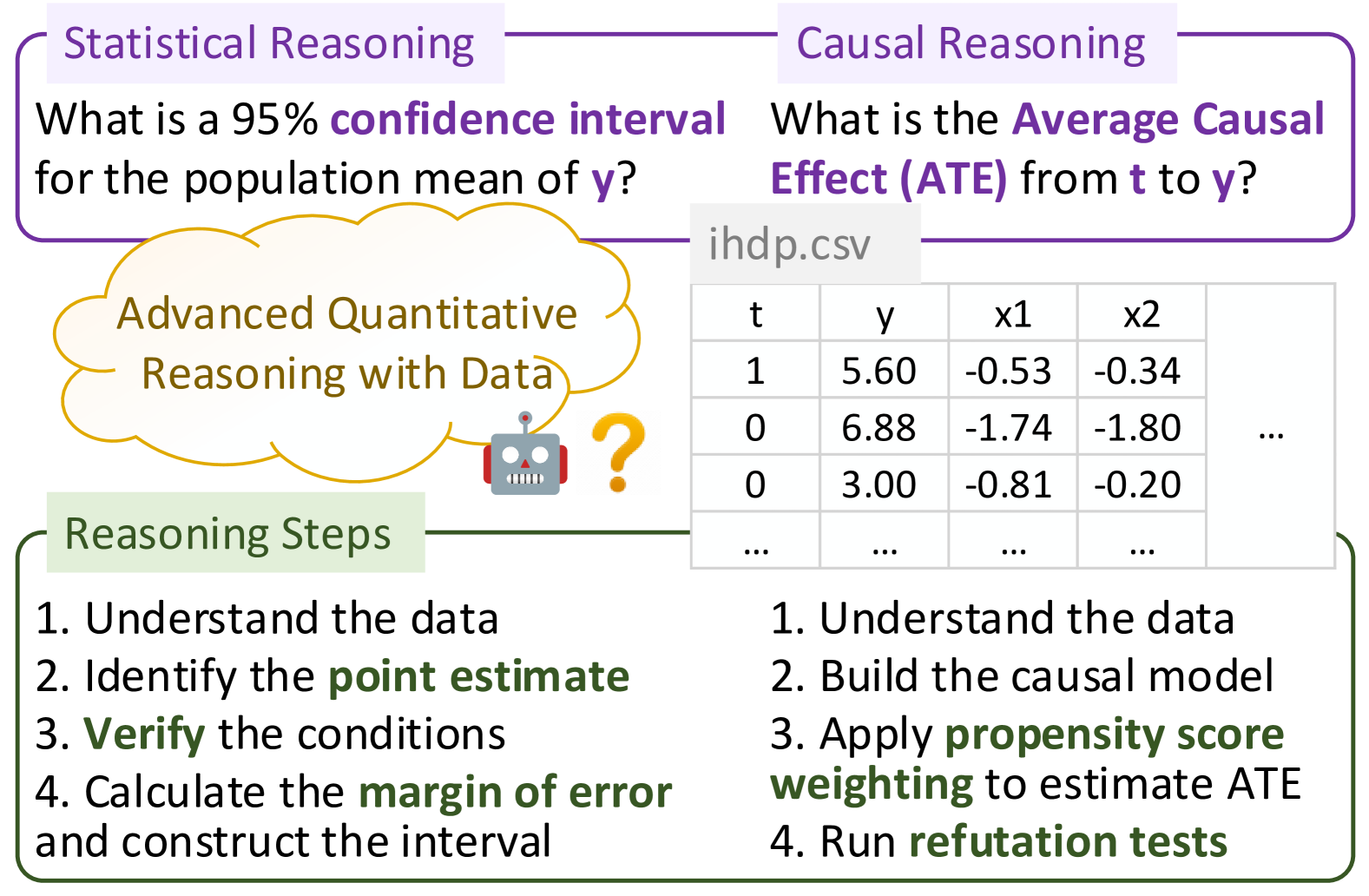
0
Are LLMs Capable of Data-based Statistical and Causal Reasoning? Benchmarking Advanced Quantitative Reasoning with Data
Xiao Liu, Zirui Wu, Xueqing Wu, Pan Lu, Kai-Wei Chang, Yansong Feng
Quantitative reasoning is a critical skill to analyze data, yet the assessment of such ability remains limited. To address this gap, we introduce the Quantitative Reasoning with Data (QRData) benchmark, aiming to evaluate Large Language Models' capability in statistical and causal reasoning with real-world data. The benchmark comprises a carefully constructed dataset of 411 questions accompanied by data sheets from textbooks, online learning materials, and academic papers. To compare models' quantitative reasoning abilities on data and text, we enrich the benchmark with an auxiliary set of 290 text-only questions, namely QRText. We evaluate natural language reasoning, program-based reasoning, and agent reasoning methods including Chain-of-Thought, Program-of-Thoughts, ReAct, and code interpreter assistants on diverse models. The strongest model GPT-4 achieves an accuracy of 58%, which has much room for improvement. Among open-source models, Deepseek-coder-instruct, a code LLM pretrained on 2T tokens, gets the highest accuracy of 37%. Analysis reveals that models encounter difficulties in data analysis and causal reasoning, and struggle in using causal knowledge and provided data simultaneously. Code and data are in https://github.com/xxxiaol/QRData.
Read more6/11/2024
0
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
Read more6/7/2024