Evaluating the Elementary Multilingual Capabilities of Large Language Models with MultiQ

0

Sign in to get full access
Overview
- The paper describes the creation and evaluation of the MultiQ dataset, a multilingual question-answering benchmark designed to assess the capabilities of large language models in elementary-level tasks across 103 languages.
- The dataset covers a wide range of subjects, including math, science, history, and general knowledge, with questions translated from English to other languages.
- The researchers used MultiQ to evaluate the performance of several prominent multilingual language models, providing insights into their multilingual abilities and limitations.
Plain English Explanation
The researchers behind this study have created a new dataset called MultiQ that is designed to test the language abilities of large AI models across 103 different languages. The dataset contains a variety of simple questions covering topics like math, science, history, and general knowledge, with the questions translated from English into all these other languages.
By using this MultiQ dataset to evaluate several well-known multilingual language models, the researchers were able to gain a better understanding of how well these models can handle elementary-level tasks in a wide range of languages. This provides valuable insights into the current capabilities and limitations of these models when it comes to operating in a truly multilingual environment. Link to "Quantifying Multilingual Performance of Large Language Models Across"
Technical Explanation
The researchers developed the MultiQ dataset to serve as a comprehensive benchmark for evaluating the multilingual capabilities of large language models. The dataset contains over 100,000 questions across 103 languages, covering a broad range of subjects including math, science, history, and general knowledge. These questions were originally written in English and then professionally translated into the other languages.
To assess the performance of various multilingual language models on MultiQ, the researchers conducted extensive experiments, evaluating factors such as zero-shot and few-shot learning abilities, as well as how model performance varies across different language families and levels of language proficiency. They compared the results of several prominent models, including Link to "Calibration of Multilingual Question Answering LLMs", Link to "Is Translation All You Need? A Study of Solving", and Link to "A Survey of Large Language Models for Multilingualism and Recent Advances".
Critical Analysis
The researchers acknowledge several limitations of their study, including the fact that the MultiQ dataset, while comprehensive, may not fully capture the nuances and complexities of real-world multilingual communication. Additionally, the performance of language models on this benchmark may not directly translate to their abilities in more practical, task-oriented applications. Link to "MedExpQA: A Multilingual Benchmarking of Large Language Models for Medical Question Answering"
Furthermore, the researchers note that the multilingual capabilities of language models are rapidly evolving, and the results presented in this paper may not fully reflect the current state of the art. Continued research and development in this area will be necessary to further push the boundaries of what these models can achieve.
Conclusion
The MultiQ dataset and the associated evaluation of prominent multilingual language models provide valuable insights into the current state of multilingual capabilities in large language models. The findings highlight both the strengths and limitations of these models, and underscore the importance of continued research and development to improve their performance across a wide range of languages and tasks. As the field of natural language processing continues to advance, tools like MultiQ will be crucial for tracking and driving progress in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating the Elementary Multilingual Capabilities of Large Language Models with MultiQ
Carolin Holtermann, Paul Rottger, Timm Dill, Anne Lauscher
Large language models (LLMs) need to serve everyone, including a global majority of non-English speakers. However, most LLMs today, and open LLMs in particular, are often intended for use in just English (e.g. Llama2, Mistral) or a small handful of high-resource languages (e.g. Mixtral, Qwen). Recent research shows that, despite limits in their intended use, people prompt LLMs in many different languages. Therefore, in this paper, we investigate the basic multilingual capabilities of state-of-the-art open LLMs beyond their intended use. For this purpose, we introduce MultiQ, a new silver standard benchmark for basic open-ended question answering with 27.4k test questions across a typologically diverse set of 137 languages. With MultiQ, we evaluate language fidelity, i.e. whether models respond in the prompted language, and question answering accuracy. All LLMs we test respond faithfully and/or accurately for at least some languages beyond their intended use. Most models are more accurate when they respond faithfully. However, differences across models are large, and there is a long tail of languages where models are neither accurate nor faithful. We explore differences in tokenization as a potential explanation for our findings, identifying possible correlations that warrant further investigation.
Read more7/19/2024
🔮
0
On the Calibration of Multilingual Question Answering LLMs
Yahan Yang, Soham Dan, Dan Roth, Insup Lee
Multilingual pre-trained Large Language Models (LLMs) are incredibly effective at Question Answering (QA), a core task in Natural Language Understanding, achieving high accuracies on several multilingual benchmarks. However, little is known about how well their confidences are calibrated. In this paper, we comprehensively benchmark the calibration of several multilingual LLMs (MLLMs) on a variety of QA tasks. We perform extensive experiments, spanning encoder-only, encoder-decoder, and decoder-only QA models (size varying from 110M to 7B parameters) and diverse languages, including both high- and low-resource ones. We study different dimensions of calibration in in-distribution, out-of-distribution, and cross-lingual transfer settings, and investigate strategies to improve it, including post-hoc methods and regularized fine-tuning. For decoder-only LLMs such as LlaMa2, we additionally find that in-context learning improves confidence calibration on multilingual data. We also conduct several ablation experiments to study the effect of language distances, language corpus size, and model size on calibration, and how multilingual models compare with their monolingual counterparts for diverse tasks and languages. Our experiments suggest that the multilingual QA models are poorly calibrated for languages other than English and incorporating a small set of cheaply translated multilingual samples during fine-tuning/calibration effectively enhances the calibration performance.
Read more4/16/2024
💬
0
A Study on Large Language Models' Limitations in Multiple-Choice Question Answering
Aisha Khatun, Daniel G. Brown
The widespread adoption of Large Language Models (LLMs) has become commonplace, particularly with the emergence of open-source models. More importantly, smaller models are well-suited for integration into consumer devices and are frequently employed either as standalone solutions or as subroutines in various AI tasks. Despite their ubiquitous use, there is no systematic analysis of their specific capabilities and limitations. In this study, we tackle one of the most widely used tasks - answering Multiple Choice Question (MCQ). We analyze 26 small open-source models and find that 65% of the models do not understand the task, only 4 models properly select an answer from the given choices, and only 5 of these models are choice order independent. These results are rather alarming given the extensive use of MCQ tests with these models. We recommend exercising caution and testing task understanding before using MCQ to evaluate LLMs in any field whatsoever.
Read more8/16/2024
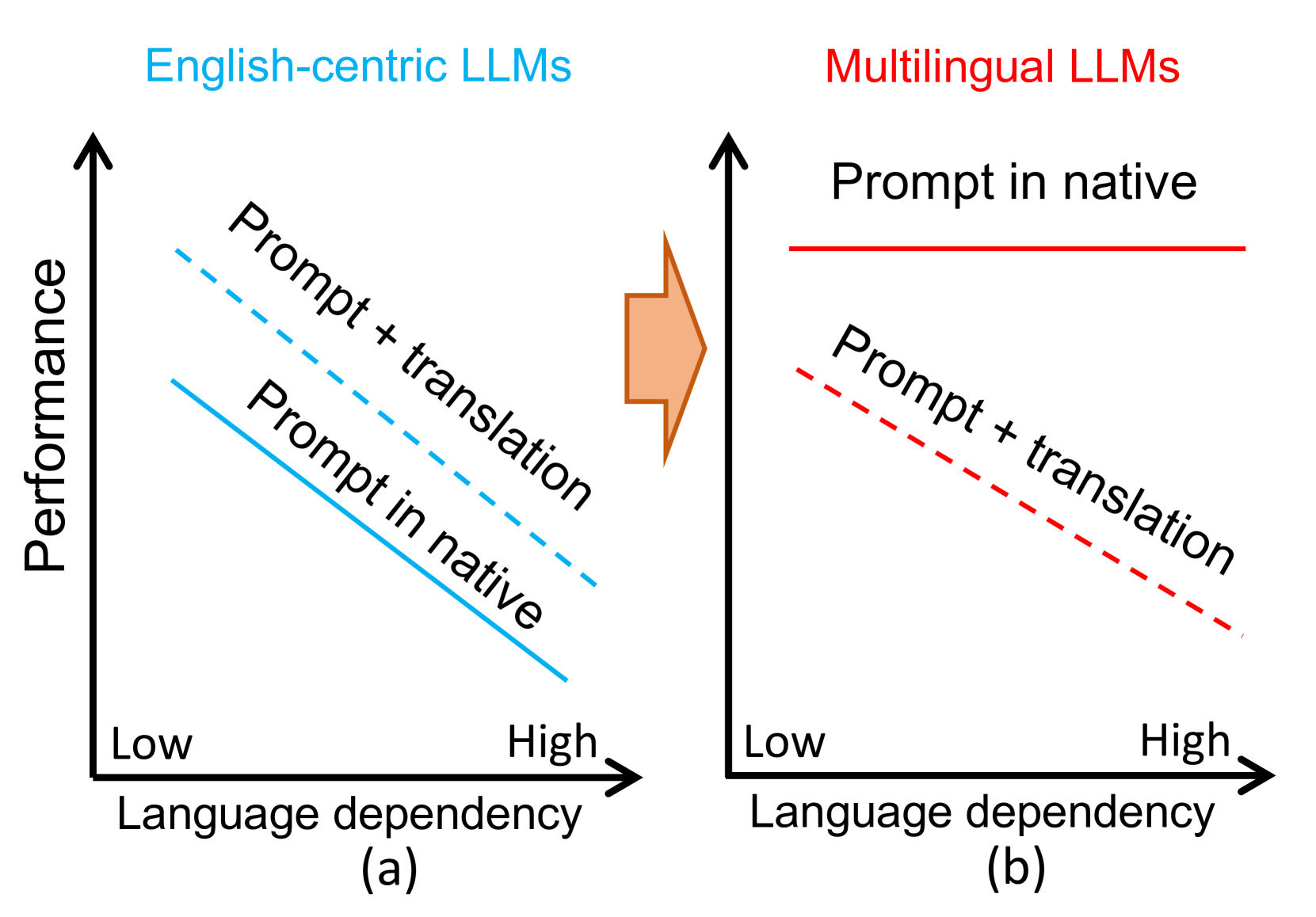
0
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, Lidong Bing
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
Read more6/21/2024