Evaluating the Explainability of Attributes and Prototypes for a Medical Classification Model

0
Sign in to get full access
Overview
• This paper evaluates the explainability of visual attributes and prototypes for a medical classification model.
• The researchers investigate how well these techniques can help users understand the model's decision-making process.
Plain English Explanation
This paper looks at ways to make a medical classification model more
The researchers tested two approaches: visual attributes and prototypes. Visual attributes are specific visual features the model uses, like the shape or texture of an X-ray image. Prototypes are examples that are representative of each class the model is trying to predict, like typical examples of different medical conditions.
The goal was to see how well these techniques could help users understand the model's reasoning, compared to just looking at the final predictions. This is important for medical applications, where being able to trust and interpret a model's decisions is crucial.
Technical Explanation
The researchers conducted experiments to evaluate the explainability of visual attributes and prototypes for a medical image classification model. They used a model trained to predict the presence of pneumonia from chest X-ray images.
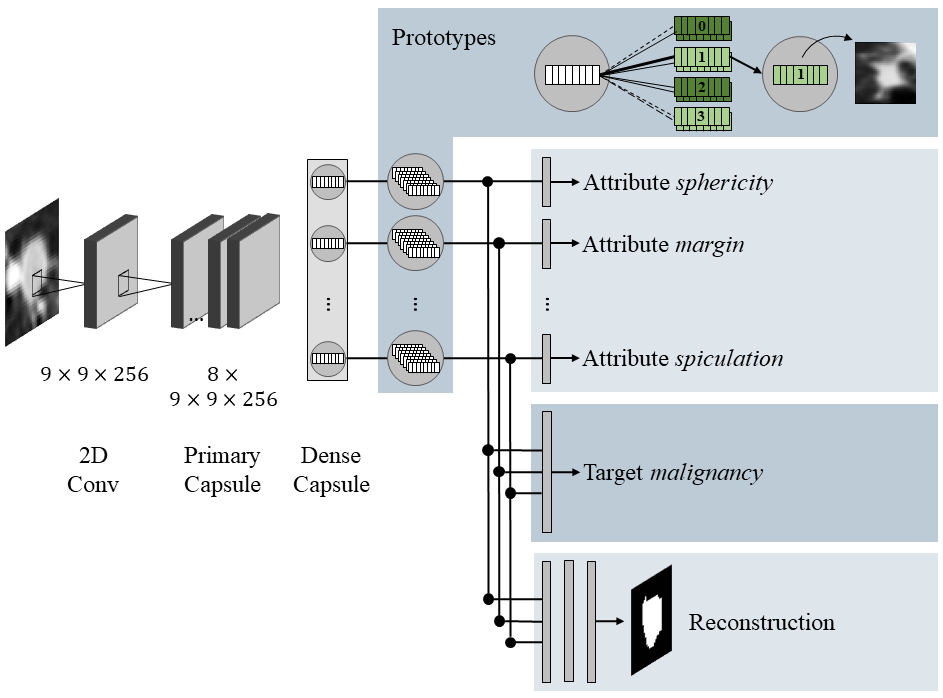
For the visual attributes approach, the model was trained to not only predict the pneumonia class, but also identify specific visual features that were important for that prediction. These included things like the shape and texture of lung regions, the presence of fluid, etc.
The prototype-based approach involved training the model to select representative examples (prototypes) for each class. When making a prediction, the model would also output the most similar prototype, providing a tangible example for the user.
The researchers then had human participants interact with the model and evaluate how well they could understand its decision-making process using the different explainability techniques. This included metrics like how accurately the participants could predict the model's outputs and how much they trusted the model.
Critical Analysis
The paper provides a thoughtful evaluation of two common explainability techniques in the context of a medical image classification task. The experiments are well-designed and the results offer valuable insights.
However, the paper does not deeply address some potential limitations of these approaches. For example, prototype-based models may struggle with rare or atypical cases that don't match the selected prototypes well.
Additionally, the study only looks at a single medical task. More research may be needed to understand how these explainability techniques perform across a wider range of healthcare applications and datasets.
Lastly, the paper does not explore causal relationships between the visual attributes and the model's predictions. Understanding these causal links could further improve the explainability of the system.
Conclusion
This paper provides a valuable empirical evaluation of visual attributes and prototypes as tools for explaining the decision-making of a medical classification model. The results suggest these techniques can indeed help users better understand the model's reasoning, which is crucial for building trust and adoption in sensitive domains like healthcare.
However, the research also highlights the need for continued work on developing more robust and comprehensive explainability methods for AI systems. As these models become more widely deployed, ensuring their decisions are transparent and interpretable will only grow in importance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating the Explainability of Attributes and Prototypes for a Medical Classification Model
Luisa Gall'ee, Catharina Silvia Lisson, Christoph Gerhard Lisson, Daniela Drees, Felix Weig, Daniel Vogele, Meinrad Beer, Michael Gotz
Due to the sensitive nature of medicine, it is particularly important and highly demanded that AI methods are explainable. This need has been recognised and there is great research interest in xAI solutions with medical applications. However, there is a lack of user-centred evaluation regarding the actual impact of the explanations. We evaluate attribute- and prototype-based explanations with the Proto-Caps model. This xAI model reasons the target classification with human-defined visual features of the target object in the form of scores and attribute-specific prototypes. The model thus provides a multimodal explanation that is intuitively understandable to humans thanks to predefined attributes. A user study involving six radiologists shows that the explanations are subjectivly perceived as helpful, as they reflect their decision-making process. The results of the model are considered a second opinion that radiologists can discuss using the model's explanations. However, it was shown that the inclusion and increased magnitude of model explanations objectively can increase confidence in the model's predictions when the model is incorrect. We can conclude that attribute scores and visual prototypes enhance confidence in the model. However, additional development and repeated user studies are needed to tailor the explanation to the respective use case.
Read more4/16/2024
🤔
0
Understanding the (Extra-)Ordinary: Validating Deep Model Decisions with Prototypical Concept-based Explanations
Maximilian Dreyer, Reduan Achtibat, Wojciech Samek, Sebastian Lapuschkin
Ensuring both transparency and safety is critical when deploying Deep Neural Networks (DNNs) in high-risk applications, such as medicine. The field of explainable AI (XAI) has proposed various methods to comprehend the decision-making processes of opaque DNNs. However, only few XAI methods are suitable of ensuring safety in practice as they heavily rely on repeated labor-intensive and possibly biased human assessment. In this work, we present a novel post-hoc concept-based XAI framework that conveys besides instance-wise (local) also class-wise (global) decision-making strategies via prototypes. What sets our approach apart is the combination of local and global strategies, enabling a clearer understanding of the (dis-)similarities in model decisions compared to the expected (prototypical) concept use, ultimately reducing the dependence on human long-term assessment. Quantifying the deviation from prototypical behavior not only allows to associate predictions with specific model sub-strategies but also to detect outlier behavior. As such, our approach constitutes an intuitive and explainable tool for model validation. We demonstrate the effectiveness of our approach in identifying out-of-distribution samples, spurious model behavior and data quality issues across three datasets (ImageNet, CUB-200, and CIFAR-10) utilizing VGG, ResNet, and EfficientNet architectures. Code is available on https://github.com/maxdreyer/pcx.
Read more4/30/2024
🤖
0
Using generative AI to investigate medical imagery models and datasets
Oran Lang, Doron Yaya-Stupp, Ilana Traynis, Heather Cole-Lewis, Chloe R. Bennett, Courtney Lyles, Charles Lau, Michal Irani, Christopher Semturs, Dale R. Webster, Greg S. Corrado, Avinatan Hassidim, Yossi Matias, Yun Liu, Naama Hammel, Boris Babenko
AI models have shown promise in many medical imaging tasks. However, our ability to explain what signals these models have learned is severely lacking. Explanations are needed in order to increase the trust in AI-based models, and could enable novel scientific discovery by uncovering signals in the data that are not yet known to experts. In this paper, we present a method for automatic visual explanations leveraging team-based expertise by generating hypotheses of what visual signals in the images are correlated with the task. We propose the following 4 steps: (i) Train a classifier to perform a given task (ii) Train a classifier guided StyleGAN-based image generator (StylEx) (iii) Automatically detect and visualize the top visual attributes that the classifier is sensitive towards (iv) Formulate hypotheses for the underlying mechanisms, to stimulate future research. Specifically, we present the discovered attributes to an interdisciplinary panel of experts so that hypotheses can account for social and structural determinants of health. We demonstrate results on eight prediction tasks across three medical imaging modalities: retinal fundus photographs, external eye photographs, and chest radiographs. We showcase examples of attributes that capture clinically known features, confounders that arise from factors beyond physiological mechanisms, and reveal a number of physiologically plausible novel attributes. Our approach has the potential to enable researchers to better understand, improve their assessment, and extract new knowledge from AI-based models. Importantly, we highlight that attributes generated by our framework can capture phenomena beyond physiology or pathophysiology, reflecting the real world nature of healthcare delivery and socio-cultural factors. Finally, we intend to release code to enable researchers to train their own StylEx models and analyze their predictive tasks.
Read more7/8/2024
🤖
0
Explainable AI: Definition and attributes of a good explanation for health AI
Evangelia Kyrimi, Scott McLachlan, Jared M Wohlgemut, Zane B Perkins, David A. Lagnado, William Marsh, the ExAIDSS Expert Group
Proposals of artificial intelligence (AI) solutions based on increasingly complex and accurate predictive models are becoming ubiquitous across many disciplines. As the complexity of these models grows, transparency and users' understanding often diminish. This suggests that accurate prediction alone is insufficient for making an AI-based solution truly useful. In the development of healthcare systems, this introduces new issues related to accountability and safety. Understanding how and why an AI system makes a recommendation may require complex explanations of its inner workings and reasoning processes. Although research on explainable AI (XAI) has significantly increased in recent years and there is high demand for XAI in medicine, defining what constitutes a good explanation remains ad hoc, and providing adequate explanations continues to be challenging. To fully realize the potential of AI, it is critical to address two fundamental questions about explanations for safety-critical AI applications, such as health-AI: (1) What is an explanation in health-AI? and (2) What are the attributes of a good explanation in health-AI? In this study, we examined published literature and gathered expert opinions through a two-round Delphi study. The research outputs include (1) a definition of what constitutes an explanation in health-AI and (2) a comprehensive list of attributes that characterize a good explanation in health-AI.
Read more9/25/2024