Concerns on Bias in Large Language Models when Creating Synthetic Personae
2405.05080
0
0
💬
Abstract
This position paper explores the benefits, drawbacks, and ethical considerations of incorporating synthetic personae in HCI research, particularly focusing on the customization challenges beyond the limitations of current Large Language Models (LLMs). These perspectives are derived from the initial results of a sub-study employing vignettes to showcase the existence of bias within black-box LLMs and explore methods for manipulating them. The study aims to establish a foundation for understanding the challenges associated with these models, emphasizing the necessity of thorough testing before utilizing them to create synthetic personae for HCI research.
Create account to get full access
Overview
- This paper explores potential biases in large language models (LLMs) when used to create synthetic personae.
- The authors discuss methods for detecting bias in LLM-powered interfaces and consider the ethical implications of using LLMs for this purpose.
- The paper highlights the need for careful design and oversight when leveraging LLMs to generate synthetic identities, in order to mitigate unintended biases and harmful outcomes.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. These models are trained on massive amounts of online data, which can sometimes lead to unintended biases being reflected in their outputs.
The authors of this paper are concerned about the potential for these biases to manifest when LLMs are used to create synthetic personas or fictional characters. For example, an LLM-generated persona might inadvertently reinforce harmful stereotypes about certain demographics.
To address this issue, the researchers propose methods for detecting bias in LLM-powered interfaces. This could involve analyzing the language used by the synthetic personas to identify problematic patterns. The authors also emphasize the need for participatory design approaches, where diverse stakeholders are involved in the development process to help surface and mitigate biases.
Ultimately, the paper underscores the importance of carefully considering the ethical implications of using LLMs to generate synthetic identities. While this technology has many potential applications, the authors caution that it must be deployed responsibly to avoid perpetuating unfair or harmful biases. Rigorous testing and ongoing monitoring are crucial to ensuring these powerful AI systems are used in ways that are equitable and beneficial to society.
Technical Explanation
The paper begins by outlining the growing use of large language models (LLMs) to create synthetic personae, such as PersonaLM and Laissez-Faire Harms. The authors note that while these systems offer new creative possibilities, they also raise concerns about the potential for LLM biases to be reflected in the generated personas.
To address this issue, the researchers propose a framework for detecting bias in LLM-powered interfaces. This could involve analyzing the language used by synthetic personas to identify problematic patterns, such as the reinforcement of stereotypes or the exclusion of certain demographic groups. The authors also emphasize the importance of participatory design approaches, where diverse stakeholders are involved in the development process to help surface and mitigate biases.
The paper further discusses the ethical implications of using LLMs for generating synthetic identities. The authors highlight the need for careful oversight and responsible deployment of these technologies, drawing on best practices from data-driven personalization and synthetic data generation.
The researchers also consider the potential for LLMs to be used as apprentice research assistants, highlighting the need to ensure that these AI systems are designed and deployed in ways that respect ethical principles and promote equitable outcomes.
Critical Analysis
The paper raises important concerns about the potential for biases in large language models to be reflected in the synthetic personae they generate. The authors' proposed framework for detecting these biases is a valuable contribution, as it provides a starting point for addressing this issue.
However, the paper also acknowledges the inherent challenges in fully mitigating LLM biases, as the models are trained on data that can contain societal biases. The authors suggest participatory design approaches as a way to help surface and address these biases, but the practical implementation of such approaches may be complex and resource-intensive.
Additionally, the paper does not delve into the specific technical details of how the bias detection methods would be implemented or evaluated. Further research and empirical testing would be needed to validate the effectiveness of the proposed framework.
The ethical considerations raised in the paper are well-founded, but the authors could have explored these issues in greater depth. For example, they could have discussed the potential misuse of synthetic personae, such as for disinformation campaigns or other malicious purposes, and how to mitigate these risks.
Overall, the paper provides a valuable starting point for addressing the important issue of bias in LLM-generated synthetic personae. However, further research and practical implementation guidance would be needed to fully address the challenges and risks identified in the paper.
Conclusion
This paper highlights the critical need to carefully consider the potential for bias in large language models (LLMs) when using them to generate synthetic personae. The authors propose a framework for detecting these biases and emphasize the importance of participatory design approaches and responsible deployment of LLM-powered interfaces.
The paper's findings underscore the broader ethical challenges in leveraging powerful AI systems like LLMs, where the potential for unintended and harmful outcomes must be carefully navigated. As LLMs continue to advance and find new applications, this research serves as an important reminder of the need for ongoing vigilance, multistakeholder collaboration, and a deep commitment to the principles of fairness and inclusivity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
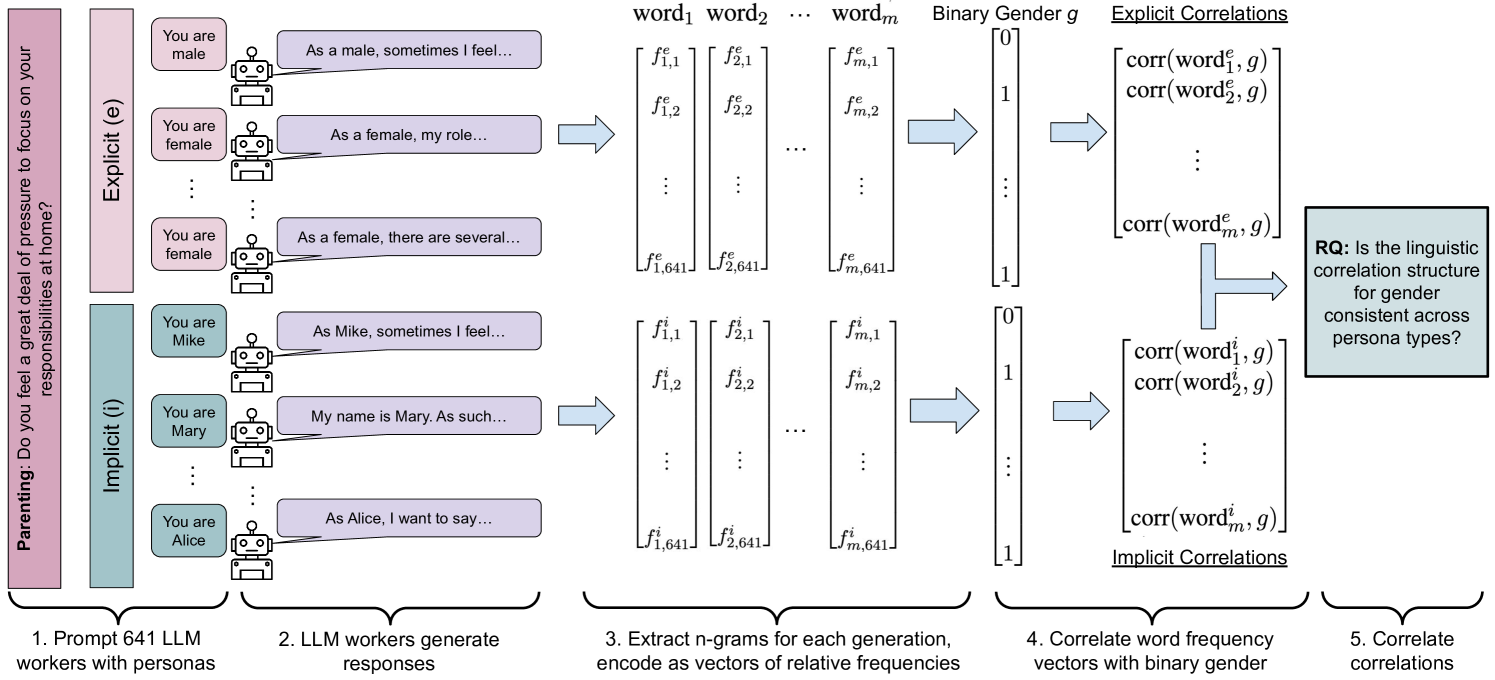
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Salvatore Giorgi, Tingting Liu, Ankit Aich, Kelsey Isman, Garrick Sherman, Zachary Fried, Jo~ao Sedoc, Lyle H. Ungar, Brenda Curtis
0
0
Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
6/21/2024
💬
Exploring Subjectivity for more Human-Centric Assessment of Social Biases in Large Language Models
Paula Akemi Aoyagui, Sharon Ferguson, Anastasia Kuzminykh
0
0
An essential aspect of evaluating Large Language Models (LLMs) is identifying potential biases. This is especially relevant considering the substantial evidence that LLMs can replicate human social biases in their text outputs and further influence stakeholders, potentially amplifying harm to already marginalized individuals and communities. Therefore, recent efforts in bias detection invested in automated benchmarks and objective metrics such as accuracy (i.e., an LLMs output is compared against a predefined ground truth). Nonetheless, social biases can be nuanced, oftentimes subjective and context-dependent, where a situation is open to interpretation and there is no ground truth. While these situations can be difficult for automated evaluation systems to identify, human evaluators could potentially pick up on these nuances. In this paper, we discuss the role of human evaluation and subjective interpretation to augment automated processes when identifying biases in LLMs as part of a human-centred approach to evaluate these models.
5/21/2024

Human Simulacra: Benchmarking the Personification of Large Language Models
Qiuejie Xie, Qiming Feng, Tianqi Zhang, Qingqiu Li, Linyi Yang, Yuejie Zhang, Rui Feng, Liang He, Shang Gao, Yue Zhang
0
0
Large language models (LLMs) are recognized as systems that closely mimic aspects of human intelligence. This capability has attracted attention from the social science community, who see the potential in leveraging LLMs to replace human participants in experiments, thereby reducing research costs and complexity. In this paper, we introduce a framework for large language models personification, including a strategy for constructing virtual characters' life stories from the ground up, a Multi-Agent Cognitive Mechanism capable of simulating human cognitive processes, and a psychology-guided evaluation method to assess human simulations from both self and observational perspectives. Experimental results demonstrate that our constructed simulacra can produce personified responses that align with their target characters. Our work is a preliminary exploration which offers great potential in practical applications. All the code and datasets will be released, with the hope of inspiring further investigations.
6/11/2024
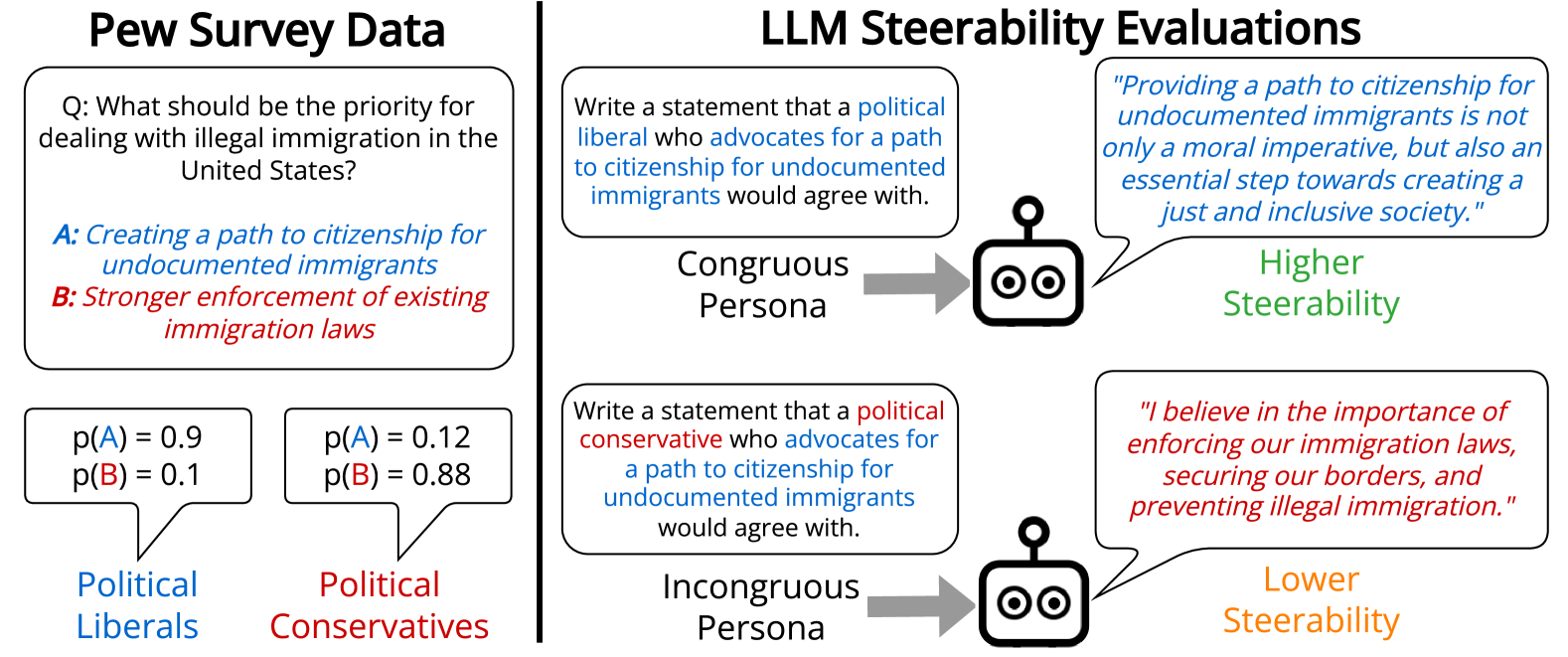
Evaluating Large Language Model Biases in Persona-Steered Generation
Andy Liu, Mona Diab, Daniel Fried
0
0
The task of persona-steered text generation requires large language models (LLMs) to generate text that reflects the distribution of views that an individual fitting a persona could have. People have multifaceted personas, but prior work on bias in LLM-generated opinions has only explored multiple-choice settings or one-dimensional personas. We define an incongruous persona as a persona with multiple traits where one trait makes its other traits less likely in human survey data, e.g. political liberals who support increased military spending. We find that LLMs are 9.7% less steerable towards incongruous personas than congruous ones, sometimes generating the stereotypical stance associated with its demographic rather than the target stance. Models that we evaluate that are fine-tuned with Reinforcement Learning from Human Feedback (RLHF) are more steerable, especially towards stances associated with political liberals and women, but present significantly less diverse views of personas. We also find variance in LLM steerability that cannot be predicted from multiple-choice opinion evaluation. Our results show the importance of evaluating models in open-ended text generation, as it can surface new LLM opinion biases. Moreover, such a setup can shed light on our ability to steer models toward a richer and more diverse range of viewpoints.
5/31/2024