Can LLMs Reason in the Wild with Programs?
2406.13764
0
0

Abstract
Large Language Models (LLMs) have shown superior capability to solve reasoning problems with programs. While being a promising direction, most of such frameworks are trained and evaluated in settings with a prior knowledge of task requirements. However, as LLMs become more capable, it is necessary to assess their reasoning abilities in more realistic scenarios where many real-world problems are open-ended with ambiguous scope, and often require multiple formalisms to solve. To investigate this, we introduce the task of reasoning in the wild, where an LLM is tasked to solve a reasoning problem of unknown type by identifying the subproblems and their corresponding formalisms, and writing a program to solve each subproblem, guided by a tactic. We create a large tactic-guided trajectory dataset containing detailed solutions to a diverse set of reasoning problems, ranging from well-defined single-form reasoning (e.g., math, logic), to ambiguous and hybrid ones (e.g., commonsense, combined math and logic). This allows us to test various aspects of LLMs reasoning at the fine-grained level such as the selection and execution of tactics, and the tendency to take undesired shortcuts. In experiments, we highlight that existing LLMs fail significantly on problems with ambiguous and mixed scope, revealing critical limitations and overfitting issues (e.g. accuracy on GSM8K drops by at least 50%). We further show the potential of finetuning a local LLM on the tactic-guided trajectories in achieving better performance. Project repo is available at github.com/gblackout/Reason-in-the-Wild
Create account to get full access
Overview
- Explores whether large language models (LLMs) can reason in the "wild" - i.e., outside of curated test sets and in more open-ended, real-world scenarios
- Focuses on evaluating LLMs' ability to reason with programs, which are a common form of real-world knowledge representation
- Introduces a new benchmark called GTBench to assess LLMs' program reasoning capabilities
Plain English Explanation
This paper investigates whether large language models (LLMs) - the powerful AI systems behind many of today's chatbots and digital assistants - can actually reason about programs in the same way humans do. Programs are a common way to represent knowledge and problem-solving approaches in the real world, so the researchers wanted to see if LLMs could handle this type of reasoning "in the wild," rather than just on curated test sets.
To do this, they created a new benchmark called GTBench that challenges LLMs to reason about programs - for example, understanding how a piece of code works, finding bugs, or modifying the code to achieve a certain goal. This goes beyond simply answering questions about programs, and requires the models to actively engage with the program logic.
The researchers found that while LLMs can sometimes perform basic program reasoning tasks, they struggle with more complex, open-ended scenarios. This suggests that current LLMs may have fundamental limitations when it comes to the type of strategic, structured reasoning required to work with programs in the real world. The paper highlights the need for further advancements in AI to bridge this gap.
Technical Explanation
The paper introduces a new benchmark called GTBench that evaluates LLMs' ability to reason about programs. GTBench consists of a diverse set of programming tasks, such as understanding code, finding bugs, and modifying programs to achieve specific goals.
Unlike previous work that focused on question-answering about programs, GTBench requires LLMs to engage in more open-ended, strategic reasoning with the program logic. The researchers used this benchmark to test several state-of-the-art LLMs, including GPT-3, InstructGPT, and Chinchilla.
The results showed that while LLMs can handle some basic program reasoning tasks, they struggle with more complex, open-ended scenarios. The models often failed to fully comprehend the program logic or develop effective strategies to solve the tasks. This suggests that current LLMs may have fundamental limitations when it comes to the type of structured, strategic reasoning required to work with programs in the real world.
The paper also discusses the implications of these findings for the field of AI and highlights the need for further advancements to bridge the gap between LLMs' capabilities and the human-level reasoning required for real-world program understanding and manipulation.
Critical Analysis
The paper raises important questions about the limitations of current LLMs when it comes to reasoning with programs, which are a common form of knowledge representation in the real world. By introducing the GTBench benchmark, the researchers have provided a valuable tool for evaluating LLMs' program reasoning abilities in a more open-ended and challenging setting.
However, the paper also acknowledges several caveats and areas for further research. For example, the tasks in GTBench may not fully capture the breadth of program reasoning skills required in practice, and the performance of LLMs may improve with further fine-tuning or architectural changes.
Additionally, the paper does not address the potential for LLMs to be combined with other AI techniques, such as structured graph reasoning or logical reasoning, which could help to overcome the observed limitations. The researchers also do not explore whether smaller, more specialized models might be better suited for program reasoning tasks than large, general-purpose LLMs.
Overall, the paper provides a thought-provoking analysis of the current state of LLMs and highlights the need for continued research to develop AI systems that can truly reason about programs and other forms of structured knowledge in the wild.
Conclusion
This paper presents a novel benchmark, GTBench, for evaluating the ability of large language models (LLMs) to reason about programs in open-ended, real-world scenarios. The results suggest that while LLMs can handle some basic program reasoning tasks, they struggle with more complex, strategic reasoning required to fully comprehend and manipulate programs.
These findings highlight the limitations of current LLMs and the need for further advancements in AI to bridge the gap between machine and human-level program reasoning capabilities. The paper encourages the research community to continue exploring ways to enhance LLMs' structured reasoning abilities, potentially by combining them with other AI techniques like structured graph reasoning or logical reasoning, or by developing more specialized models for program-related tasks.
As AI systems become increasingly integrated into our daily lives, understanding their strengths and limitations in reasoning about real-world knowledge representations like programs will be crucial for ensuring their safe and effective deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
0
0
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
6/28/2024
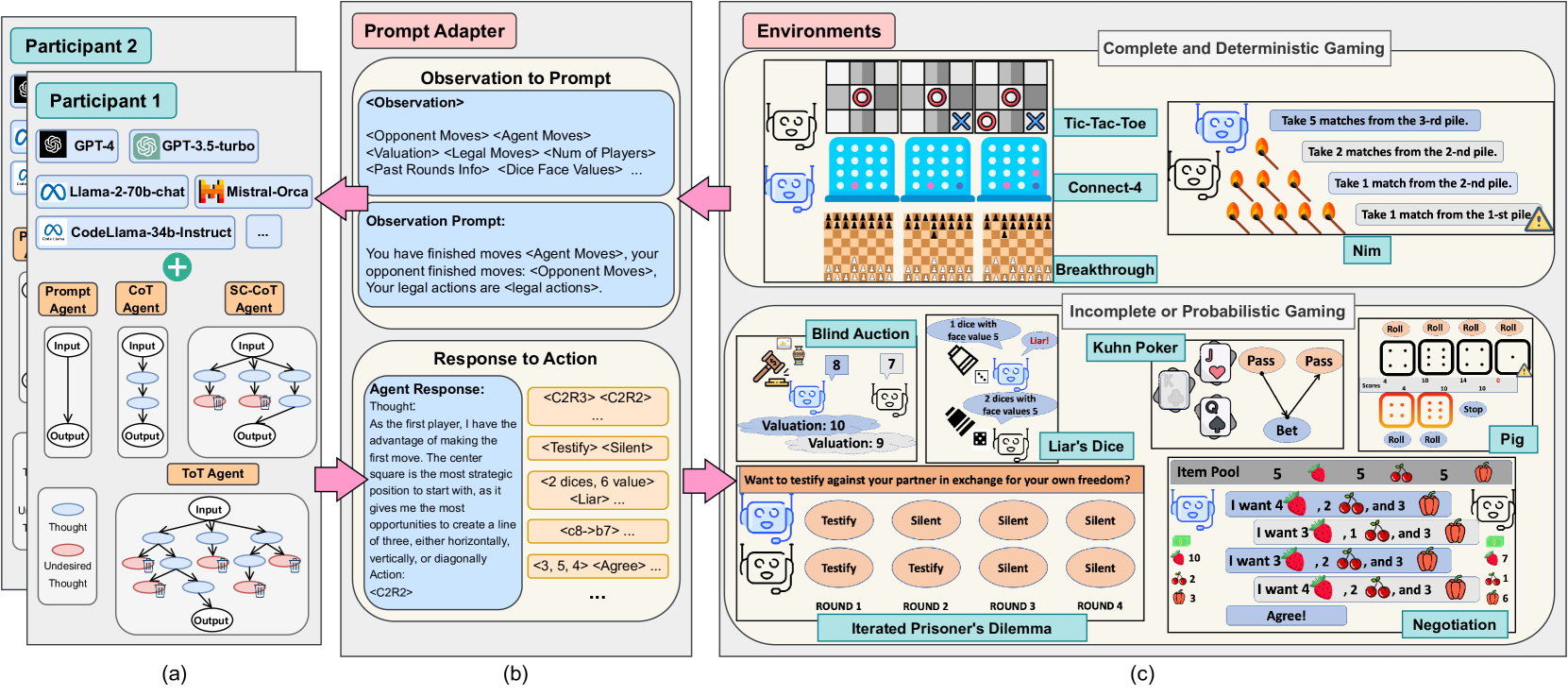
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, Kaidi Xu
0
0
As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we (1) Characterize the game-theoretic reasoning of LLMs; and (2) Perform LLM-vs.-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Most open-source LLMs, e.g., CodeLlama-34b-Instruct and Llama-2-70b-chat, are less competitive than commercial LLMs, e.g., GPT-4, in complex games, yet the recently released Llama-3-70b-Instruct makes up for this shortcoming. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. We further characterize the game-theoretic properties of LLMs, such as equilibrium and Pareto Efficiency in repeated games. Detailed error profiles are provided for a better understanding of LLMs' behavior. We hope our research provides standardized protocols and serves as a foundation to spur further explorations in the strategic reasoning of LLMs.
6/11/2024

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024
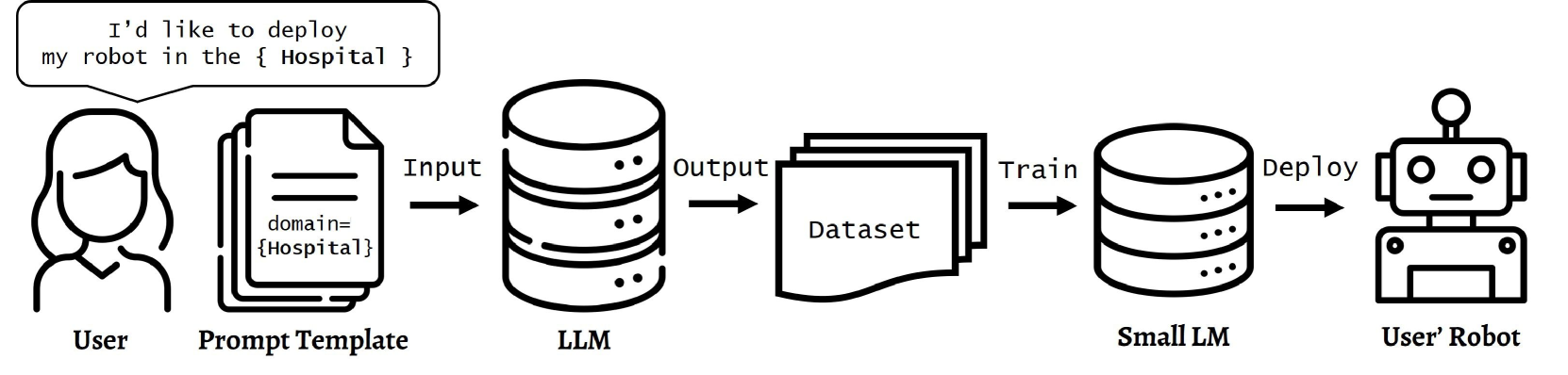
Can only LLMs do Reasoning?: Potential of Small Language Models in Task Planning
Gawon Choi, Hyemin Ahn
0
0
In robotics, the use of Large Language Models (LLMs) is becoming prevalent, especially for understanding human commands. In particular, LLMs are utilized as domain-agnostic task planners for high-level human commands. LLMs are capable of Chain-of-Thought (CoT) reasoning, and this allows LLMs to be task planners. However, we need to consider that modern robots still struggle to perform complex actions, and the domains where robots can be deployed are limited in practice. This leads us to pose a question: If small LMs can be trained to reason in chains within a single domain, would even small LMs be good task planners for the robots? To train smaller LMs to reason in chains, we build `COmmand-STeps datasets' (COST) consisting of high-level commands along with corresponding actionable low-level steps, via LLMs. We release not only our datasets but also the prompt templates used to generate them, to allow anyone to build datasets for their domain. We compare GPT3.5 and GPT4 with the finetuned GPT2 for task domains, in tabletop and kitchen environments, and the result shows that GPT2-medium is comparable to GPT3.5 for task planning in a specific domain. Our dataset, code, and more output samples can be found in https://github.com/Gawon-Choi/small-LMs-Task-Planning
4/8/2024