Evaluating the Performance of ChatGPT for Spam Email Detection
2402.15537
1
0
Abstract
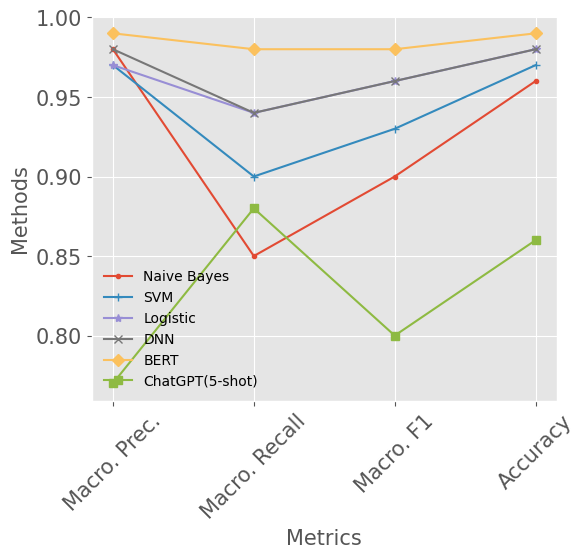
Email continues to be a pivotal and extensively utilized communication medium within professional and commercial domains. Nonetheless, the prevalence of spam emails poses a significant challenge for users, disrupting their daily routines and diminishing productivity. Consequently, accurately identifying and filtering spam based on content has become crucial for cybersecurity. Recent advancements in natural language processing, particularly with large language models like ChatGPT, have shown remarkable performance in tasks such as question answering and text generation. However, its potential in spam identification remains underexplored. To fill in the gap, this study attempts to evaluate ChatGPT's capabilities for spam identification in both English and Chinese email datasets. We employ ChatGPT for spam email detection using in-context learning, which requires a prompt instruction and a few demonstrations. We also investigate how the number of demonstrations in the prompt affects the performance of ChatGPT. For comparison, we also implement five popular benchmark methods, including naive Bayes, support vector machines (SVM), logistic regression (LR), feedforward dense neural networks (DNN), and BERT classifiers. Through extensive experiments, the performance of ChatGPT is significantly worse than deep supervised learning methods in the large English dataset, while it presents superior performance on the low-resourced Chinese dataset.
Create account to get full access
Overview
- This paper evaluates the performance of the large language model ChatGPT for the task of spam email detection.
- The researchers investigate ChatGPT's ability to accurately classify emails as spam or not, and compare its performance to traditional machine learning models.
- The study aims to assess the potential of using large language models like ChatGPT for cybersecurity applications, specifically in the context of email-based threats.
Plain English Explanation
This research paper looks at how well the AI system called ChatGPT can detect spam emails. Spam emails are messages that are unwanted or try to scam people, and being able to identify them is important for cybersecurity.
The researchers wanted to see if ChatGPT, a powerful language model that can understand and generate human-like text, could accurately classify emails as spam or not. They compared ChatGPT's performance to traditional machine learning models that are commonly used for spam detection.
The goal was to understand if large language models like ChatGPT could be useful for protecting against email-based threats and cyberattacks. If ChatGPT can reliably identify spam emails, it could be a valuable tool for improving email security and protecting people from scams and other online dangers.
Technical Explanation
The researchers designed experiments to evaluate ChatGPT's spam email detection capabilities. They used a benchmark dataset of spam and non-spam emails to test ChatGPT's classification performance.
They prompted ChatGPT to analyze each email and determine if it was spam or not. ChatGPT's predictions were then compared to the ground truth labels in the dataset. The researchers also tested traditional machine learning models like Support Vector Machines and Naive Bayes on the same dataset to provide a baseline for comparison.
The results showed that ChatGPT was able to achieve competitive accuracy in distinguishing spam from non-spam emails, performing on par with or better than the traditional models. This suggests that large language models like ChatGPT have the potential to be effective for spam detection tasks.
Critical Analysis
The paper acknowledges some limitations of the study, such as the use of a single dataset and the lack of testing on real-world, dynamic email streams. There are also concerns about the interpretability and transparency of ChatGPT's decision-making process, which could be important for security applications.
Additionally, the researchers note that further research is needed to understand the generalization capabilities of large language models like ChatGPT and their robustness to evolving spam tactics. Incorporating adversarial examples or out-of-distribution data into the evaluation could provide a more comprehensive assessment of their spam detection capabilities.
Conclusion
This study demonstrates that the large language model ChatGPT can be a promising tool for spam email detection, potentially outperforming traditional machine learning approaches. The findings suggest that further research into the use of large language models for cybersecurity applications could be valuable.
However, the limitations and open questions identified in the paper highlight the need for continued exploration and careful consideration of the practical deployment of these models in real-world security scenarios. Ongoing research and development in this area could lead to more effective and robust email protection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Zero-Shot Spam Email Classification Using Pre-trained Large Language Models
Sergio Rojas-Galeano
0
0
This paper investigates the application of pre-trained large language models (LLMs) for spam email classification using zero-shot prompting. We evaluate the performance of both open-source (Flan-T5) and proprietary LLMs (ChatGPT, GPT-4) on the well-known SpamAssassin dataset. Two classification approaches are explored: (1) truncated raw content from email subject and body, and (2) classification based on summaries generated by ChatGPT. Our empirical analysis, leveraging the entire dataset for evaluation without further training, reveals promising results. Flan-T5 achieves a 90% F1-score on the truncated content approach, while GPT-4 reaches a 95% F1-score using summaries. While these initial findings on a single dataset suggest the potential for classification pipelines of LLM-based subtasks (e.g., summarisation and classification), further validation on diverse datasets is necessary. The high operational costs of proprietary models, coupled with the general inference costs of LLMs, could significantly hinder real-world deployment for spam filtering.
5/28/2024
🔎
FakeGPT: Fake News Generation, Explanation and Detection of Large Language Models
Yue Huang, Lichao Sun
0
0
The rampant spread of fake news has adversely affected society, resulting in extensive research on curbing its spread. As a notable milestone in large language models (LLMs), ChatGPT has gained significant attention due to its exceptional natural language processing capabilities. In this study, we present a thorough exploration of ChatGPT's proficiency in generating, explaining, and detecting fake news as follows. Generation -- We employ four prompt methods to generate fake news samples and prove the high quality of these samples through both self-assessment and human evaluation. Explanation -- We obtain nine features to characterize fake news based on ChatGPT's explanations and analyze the distribution of these factors across multiple public datasets. Detection -- We examine ChatGPT's capacity to identify fake news. We explore its detection consistency and then propose a reason-aware prompt method to improve its performance. Although our experiments demonstrate that ChatGPT shows commendable performance in detecting fake news, there is still room for its improvement. Consequently, we further probe into the potential extra information that could bolster its effectiveness in detecting fake news.
4/9/2024
💬
ChatGPT v.s. Media Bias: A Comparative Study of GPT-3.5 and Fine-tuned Language Models
Zehao Wen, Rabih Younes
0
0
In our rapidly evolving digital sphere, the ability to discern media bias becomes crucial as it can shape public sentiment and influence pivotal decisions. The advent of large language models (LLMs), such as ChatGPT, noted for their broad utility in various natural language processing (NLP) tasks, invites exploration of their efficacy in media bias detection. Can ChatGPT detect media bias? This study seeks to answer this question by leveraging the Media Bias Identification Benchmark (MBIB) to assess ChatGPT's competency in distinguishing six categories of media bias, juxtaposed against fine-tuned models such as BART, ConvBERT, and GPT-2. The findings present a dichotomy: ChatGPT performs at par with fine-tuned models in detecting hate speech and text-level context bias, yet faces difficulties with subtler elements of other bias detections, namely, fake news, racial, gender, and cognitive biases.
4/1/2024
📊
Unmasking the giant: A comprehensive evaluation of ChatGPT's proficiency in coding algorithms and data structures
Sayed Erfan Arefin, Tasnia Ashrafi Heya, Hasan Al-Qudah, Ynes Ineza, Abdul Serwadda
0
0
The transformative influence of Large Language Models (LLMs) is profoundly reshaping the Artificial Intelligence (AI) technology domain. Notably, ChatGPT distinguishes itself within these models, demonstrating remarkable performance in multi-turn conversations and exhibiting code proficiency across an array of languages. In this paper, we carry out a comprehensive evaluation of ChatGPT's coding capabilities based on what is to date the largest catalog of coding challenges. Our focus is on the python programming language and problems centered on data structures and algorithms, two topics at the very foundations of Computer Science. We evaluate ChatGPT for its ability to generate correct solutions to the problems fed to it, its code quality, and nature of run-time errors thrown by its code. Where ChatGPT code successfully executes, but fails to solve the problem at hand, we look into patterns in the test cases passed in order to gain some insights into how wrong ChatGPT code is in these kinds of situations. To infer whether ChatGPT might have directly memorized some of the data that was used to train it, we methodically design an experiment to investigate this phenomena. Making comparisons with human performance whenever feasible, we investigate all the above questions from the context of both its underlying learning models (GPT-3.5 and GPT-4), on a vast array sub-topics within the main topics, and on problems having varying degrees of difficulty.
5/28/2024