Evaluating Posterior Probabilities: Decision Theory, Proper Scoring Rules, and Calibration

0
Sign in to get full access
Overview
- The paper discusses the evaluation of posterior probabilities, which are essential for decision-making and probabilistic machine learning models.
- It explores decision theory, proper scoring rules, and calibration as key concepts for assessing the quality of posterior probabilities.
- The paper aims to provide a unifying framework for understanding these concepts and their relationships.
Plain English Explanation
When we make decisions, we often rely on probabilities or likelihoods of different outcomes. These probabilities, known as posterior probabilities, are crucial for decision-making and are commonly used in machine learning models.
The paper examines three important aspects of evaluating posterior probabilities:
-
Decision Theory: This theory helps us understand how to make the best decisions based on the available probabilities. It provides a framework for weighing the potential outcomes and their associated risks and rewards.
-
Proper Scoring Rules: These are mathematical tools that measure how well the predicted probabilities match the actual outcomes. They help us assess the quality and accuracy of the posterior probabilities.
-
Calibration: This concept refers to how well the predicted probabilities align with the real-world frequencies of the outcomes. Well-calibrated models provide posterior probabilities that closely match the true likelihoods of the events.
The paper aims to bring these three concepts together, providing a unified way to understand and evaluate the quality of posterior probabilities. This is important for making informed decisions and developing reliable machine learning models.
Technical Explanation
The paper starts by introducing Bayes decision theory, which provides a framework for making decisions based on posterior probabilities. It explains how to use this theory to choose the optimal action given the available probabilities and the potential consequences of each action.
Next, the paper delves into proper scoring rules, which are mathematical functions that quantify the quality of predicted probabilities. These rules, such as the logarithmic and Brier scoring rules, incentivize the model to provide accurate and well-calibrated probabilities.
The authors then explore the concept of calibration, which measures how well the predicted probabilities match the actual frequencies of the outcomes. Well-calibrated models ensure that the posterior probabilities they provide are reliable and trustworthy.
The paper also discusses the relationship between decision theory, proper scoring rules, and calibration, demonstrating how these concepts are interconnected and can be used together to evaluate the quality of posterior probabilities.
Critical Analysis
The paper provides a comprehensive and well-structured overview of the key concepts in evaluating posterior probabilities. It successfully integrates decision theory, proper scoring rules, and calibration, offering a unified framework for understanding these important topics.
One potential limitation of the paper is that it focuses primarily on the theoretical aspects and does not provide extensive empirical evidence or case studies. While the concepts are well-explained, readers may benefit from seeing how these ideas are applied in real-world scenarios.
Additionally, the paper could have addressed some of the practical challenges and limitations in implementing these techniques, such as the sensitivity of proper scoring rules to outliers or the difficulties in achieving perfect calibration in complex models.
Overall, the paper is a valuable resource for researchers and practitioners interested in understanding the foundations of evaluating posterior probabilities and their importance in decision-making and machine learning.
Conclusion
This paper presents a comprehensive exploration of the key concepts involved in evaluating posterior probabilities, which are crucial for decision-making and the development of reliable machine learning models. By integrating decision theory, proper scoring rules, and calibration, the authors provide a unifying framework for assessing the quality of predicted probabilities.
The insights offered in this paper can help researchers and practitioners better understand the importance of accurate and well-calibrated posterior probabilities, and how to effectively evaluate them. This knowledge can lead to improved decision-making processes and the creation of more trustworthy and robust machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating Posterior Probabilities: Decision Theory, Proper Scoring Rules, and Calibration
Luciana Ferrer, Daniel Ramos
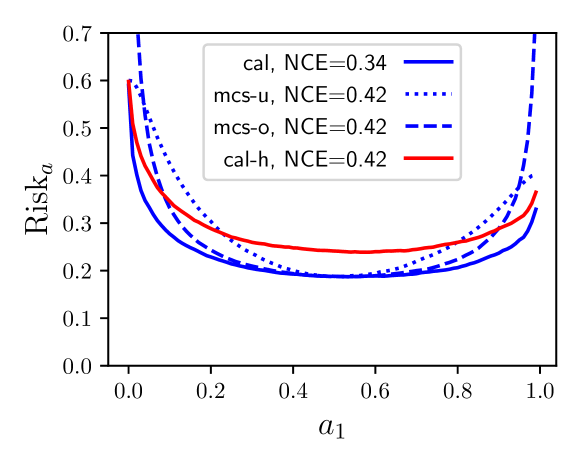
Most machine learning classifiers are designed to output posterior probabilities for the classes given the input sample. These probabilities may be used to make the categorical decision on the class of the sample; provided as input to a downstream system; or provided to a human for interpretation. Evaluating the quality of the posteriors generated by these system is an essential problem which was addressed decades ago with the invention of proper scoring rules (PSRs). Unfortunately, much of the recent machine learning literature uses calibration metrics -- most commonly, the expected calibration error (ECE) -- as a proxy to assess posterior performance. The problem with this approach is that calibration metrics reflect only one aspect of the quality of the posteriors, ignoring the discrimination performance. For this reason, we argue that calibration metrics should play no role in the assessment of posterior quality. Expected PSRs should instead be used for this job, preferably normalized for ease of interpretation. In this work, we first give a brief review of PSRs from a practical perspective, motivating their definition using Bayes decision theory. We discuss why expected PSRs provide a principled measure of the quality of a system's posteriors and why calibration metrics are not the right tool for this job. We argue that calibration metrics, while not useful for performance assessment, may be used as diagnostic tools during system development. With this purpose in mind, we discuss a simple and practical calibration metric, called calibration loss, derived from a decomposition of expected PSRs. We compare this metric with the ECE and with the expected score divergence calibration metric from the PSR literature and argue, using theoretical and empirical evidence, that calibration loss is superior to these two metrics.
Read more8/7/2024

0
Probabilistic Scores of Classifiers, Calibration is not Enough
Agathe Fernandes Machado, Arthur Charpentier, Emmanuel Flachaire, Ewen Gallic, Franc{c}ois Hu
In binary classification tasks, accurate representation of probabilistic predictions is essential for various real-world applications such as predicting payment defaults or assessing medical risks. The model must then be well-calibrated to ensure alignment between predicted probabilities and actual outcomes. However, when score heterogeneity deviates from the underlying data probability distribution, traditional calibration metrics lose reliability, failing to align score distribution with actual probabilities. In this study, we highlight approaches that prioritize optimizing the alignment between predicted scores and true probability distributions over minimizing traditional performance or calibration metrics. When employing tree-based models such as Random Forest and XGBoost, our analysis emphasizes the flexibility these models offer in tuning hyperparameters to minimize the Kullback-Leibler (KL) divergence between predicted and true distributions. Through extensive empirical analysis across 10 UCI datasets and simulations, we demonstrate that optimizing tree-based models based on KL divergence yields superior alignment between predicted scores and actual probabilities without significant performance loss. In real-world scenarios, the reference probability is determined a priori as a Beta distribution estimated through maximum likelihood. Conversely, minimizing traditional calibration metrics may lead to suboptimal results, characterized by notable performance declines and inferior KL values. Our findings reveal limitations in traditional calibration metrics, which could undermine the reliability of predictive models for critical decision-making.
Read more8/9/2024
0
Optimizing Calibration by Gaining Aware of Prediction Correctness
Yuchi Liu, Lei Wang, Yuli Zou, James Zou, Liang Zheng
Model calibration aims to align confidence with prediction correctness. The Cross-Entropy (CE) loss is widely used for calibrator training, which enforces the model to increase confidence on the ground truth class. However, we find the CE loss has intrinsic limitations. For example, for a narrow misclassification, a calibrator trained by the CE loss often produces high confidence on the wrongly predicted class (e.g., a test sample is wrongly classified and its softmax score on the ground truth class is around 0.4), which is undesirable. In this paper, we propose a new post-hoc calibration objective derived from the aim of calibration. Intuitively, the proposed objective function asks that the calibrator decrease model confidence on wrongly predicted samples and increase confidence on correctly predicted samples. Because a sample itself has insufficient ability to indicate correctness, we use its transformed versions (e.g., rotated, greyscaled and color-jittered) during calibrator training. Trained on an in-distribution validation set and tested with isolated, individual test samples, our method achieves competitive calibration performance on both in-distribution and out-of-distribution test sets compared with the state of the art. Further, our analysis points out the difference between our method and commonly used objectives such as CE loss and mean square error loss, where the latters sometimes deviates from the calibration aim.
Read more4/26/2024
🧠
0
On Measuring Calibration of Discrete Probabilistic Neural Networks
Spencer Young, Porter Jenkins
As machine learning systems become increasingly integrated into real-world applications, accurately representing uncertainty is crucial for enhancing their safety, robustness, and reliability. Training neural networks to fit high-dimensional probability distributions via maximum likelihood has become an effective method for uncertainty quantification. However, such models often exhibit poor calibration, leading to overconfident predictions. Traditional metrics like Expected Calibration Error (ECE) and Negative Log Likelihood (NLL) have limitations, including biases and parametric assumptions. This paper proposes a new approach using conditional kernel mean embeddings to measure calibration discrepancies without these biases and assumptions. Preliminary experiments on synthetic data demonstrate the method's potential, with future work planned for more complex applications.
Read more5/22/2024