Evaluating representation learning on the protein structure universe

0
Sign in to get full access
Overview
- The paper "Evaluating Representation Learning on the Protein Structure Universe" explores how well different machine learning models can learn useful representations of protein structures.
- Protein structure is a crucial aspect of understanding and predicting protein function, which has many applications in fields like drug discovery and molecular biology.
- The authors evaluate several state-of-the-art protein representation learning models on a diverse set of tasks to understand their strengths and limitations.
Plain English Explanation
Proteins are the building blocks of life, responsible for carrying out many critical functions in our bodies. Understanding the 3D structure of proteins is key to unraveling how they work and how we can design drugs or other molecules to interact with them.
The researchers in this paper wanted to see how well different machine learning models could learn useful representations of protein structures. They took several leading models, like those described in papers on learning language from protein structure, geometric self-supervised pretraining for 3D protein structures, and capturing protein sequence information, and put them through a rigorous set of tests.
The goal was to understand the strengths and limitations of these models - how well they could predict things like a protein's function or structure based on just its sequence information. This can help guide future research in this area and point to the most promising approaches for representing and reasoning about the complex 3D world of proteins.
Technical Explanation
The paper evaluates several state-of-the-art protein representation learning models, including those described in papers on pre-training protein bi-level representations and accelerating inference for molecular diffusion models.
The authors designed a comprehensive set of evaluation tasks to probe different aspects of the learned representations, including predicting protein function, structure, and other properties. They used diverse protein datasets covering a wide range of structural and functional families.
The results show that the models have varied strengths - some excel at predicting protein function, while others are better at capturing structural similarity. The authors provide detailed analysis on the performance tradeoffs and suggest directions for further improving protein representation learning.
Critical Analysis
The paper provides a thorough and unbiased evaluation of several leading protein representation learning models. The authors acknowledge the limitations of the study, such as the scope of the evaluation tasks and datasets used. They also note that the field is rapidly evolving, and future models may overcome some of the current limitations.
One potential concern is the heavy reliance on proxy tasks for evaluating the representations, as opposed to more direct measures of their usefulness for real-world applications like drug discovery. The authors address this to some extent by including a diverse set of tasks, but further research is needed to understand the true practical value of these representations.
Additionally, the paper does not provide much insight into the specific inductive biases and architectural choices that lead to the observed performance differences between the models. A deeper analysis of the model internals could shed light on the most important factors for effective protein representation learning.
Overall, this paper makes a valuable contribution by providing a comprehensive benchmarking of state-of-the-art techniques and identifying promising directions for future research in this important field.
Conclusion
This paper presents a thorough evaluation of leading protein representation learning models, shedding light on their relative strengths and limitations. The findings can help guide future research in this area and inform the development of more effective techniques for representing and reasoning about protein structures.
The authors' rigorous experimental design and diverse set of evaluation tasks offer a valuable snapshot of the current state of the field. While the results highlight the progress made, they also suggest that there is still room for improvement, particularly in bridging the gap between proxy tasks and real-world applications.
Continued advancements in protein representation learning could have significant implications for fields like drug discovery, molecular biology, and our overall understanding of the natural world. This paper lays the groundwork for further exploration and innovation in this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating representation learning on the protein structure universe
Arian R. Jamasb, Alex Morehead, Chaitanya K. Joshi, Zuobai Zhang, Kieran Didi, Simon V. Mathis, Charles Harris, Jian Tang, Jianlin Cheng, Pietro Lio, Tom L. Blundell
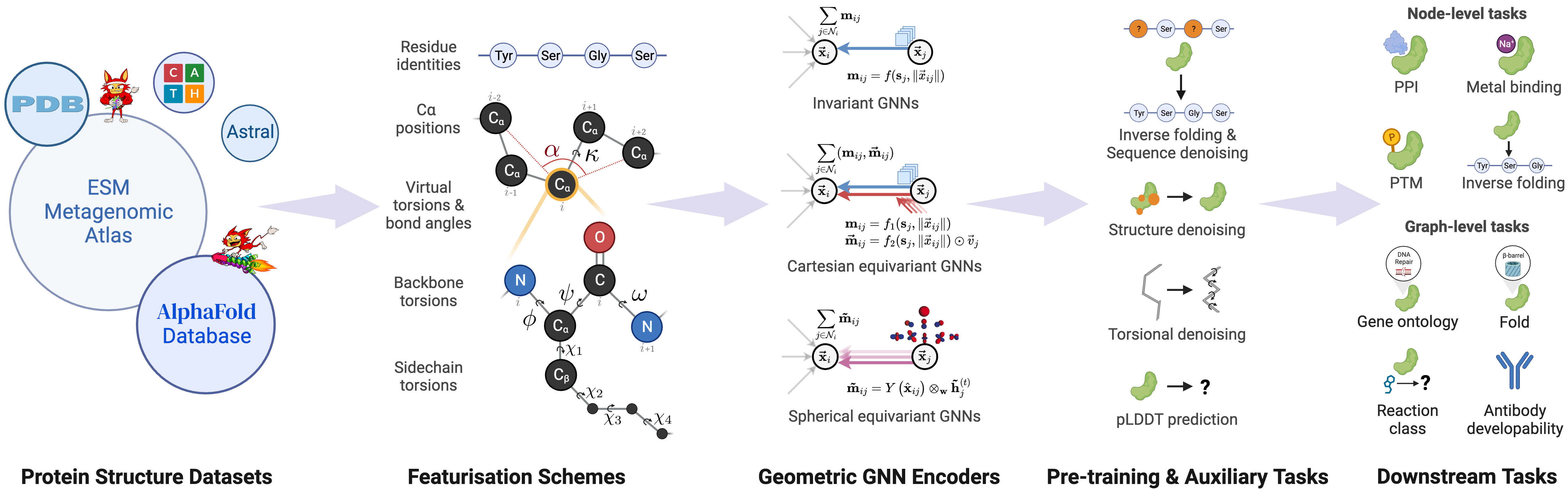
We introduce ProteinWorkshop, a comprehensive benchmark suite for representation learning on protein structures with Geometric Graph Neural Networks. We consider large-scale pre-training and downstream tasks on both experimental and predicted structures to enable the systematic evaluation of the quality of the learned structural representation and their usefulness in capturing functional relationships for downstream tasks. We find that: (1) large-scale pretraining on AlphaFold structures and auxiliary tasks consistently improve the performance of both rotation-invariant and equivariant GNNs, and (2) more expressive equivariant GNNs benefit from pretraining to a greater extent compared to invariant models. We aim to establish a common ground for the machine learning and computational biology communities to rigorously compare and advance protein structure representation learning. Our open-source codebase reduces the barrier to entry for working with large protein structure datasets by providing: (1) storage-efficient dataloaders for large-scale structural databases including AlphaFoldDB and ESM Atlas, as well as (2) utilities for constructing new tasks from the entire PDB. ProteinWorkshop is available at: github.com/a-r-j/ProteinWorkshop.
Read more6/21/2024
0
Learning the Language of Protein Structure
Benoit Gaujac, J'er'emie Don`a, Liviu Copoiu, Timothy Atkinson, Thomas Pierrot, Thomas D. Barrett
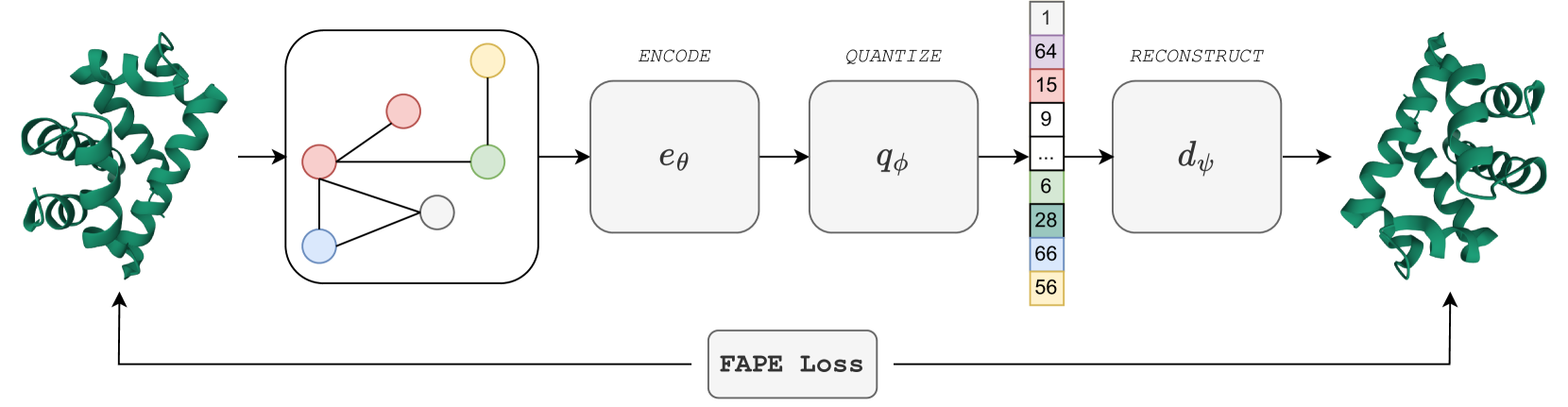
Representation learning and emph{de novo} generation of proteins are pivotal computational biology tasks. Whilst natural language processing (NLP) techniques have proven highly effective for protein sequence modelling, structure modelling presents a complex challenge, primarily due to its continuous and three-dimensional nature. Motivated by this discrepancy, we introduce an approach using a vector-quantized autoencoder that effectively tokenizes protein structures into discrete representations. This method transforms the continuous, complex space of protein structures into a manageable, discrete format with a codebook ranging from 4096 to 64000 tokens, achieving high-fidelity reconstructions with backbone root mean square deviations (RMSD) of approximately 1-5 AA. To demonstrate the efficacy of our learned representations, we show that a simple GPT model trained on our codebooks can generate novel, diverse, and designable protein structures. Our approach not only provides representations of protein structure, but also mitigates the challenges of disparate modal representations and sets a foundation for seamless, multi-modal integration, enhancing the capabilities of computational methods in protein design.
Read more5/28/2024
🌿
0
Geometric Self-Supervised Pretraining on 3D Protein Structures using Subgraphs
Michail Chatzianastasis, George Dasoulas, Michalis Vazirgiannis
Protein representation learning aims to learn informative protein embeddings capable of addressing crucial biological questions, such as protein function prediction. Although sequence-based transformer models have shown promising results by leveraging the vast amount of protein sequence data in a self-supervised way, there is still a gap in applying these methods to 3D protein structures. In this work, we propose a pre-training scheme going beyond trivial masking methods leveraging 3D and hierarchical structures of proteins. We propose a novel self-supervised method to pretrain 3D graph neural networks on 3D protein structures, by predicting the distances between local geometric centroids of protein subgraphs and the global geometric centroid of the protein. The motivation for this method is twofold. First, the relative spatial arrangements and geometric relationships among different regions of a protein are crucial for its function. Moreover, proteins are often organized in a hierarchical manner, where smaller substructures, such as secondary structure elements, assemble into larger domains. By considering subgraphs and their relationships to the global protein structure, the model can learn to reason about these hierarchical levels of organization. We experimentally show that our proposed pertaining strategy leads to significant improvements in the performance of 3D GNNs in various protein classification tasks.
Read more6/21/2024
🖼️
0
CCPL: Cross-modal Contrastive Protein Learning
Jiangbin Zheng, Stan Z. Li
Effective protein representation learning is crucial for predicting protein functions. Traditional methods often pretrain protein language models on large, unlabeled amino acid sequences, followed by finetuning on labeled data. While effective, these methods underutilize the potential of protein structures, which are vital for function determination. Common structural representation techniques rely heavily on annotated data, limiting their generalizability. Moreover, structural pretraining methods, similar to natural language pretraining, can distort actual protein structures. In this work, we introduce a novel unsupervised protein structure representation pretraining method, cross-modal contrastive protein learning (CCPL). CCPL leverages a robust protein language model and uses unsupervised contrastive alignment to enhance structure learning, incorporating self-supervised structural constraints to maintain intrinsic structural information. We evaluated our model across various benchmarks, demonstrating the framework's superiority.
Read more9/5/2024