High Fidelity Text-to-Speech Via Discrete Tokens Using Token Transducer and Group Masked Language Model

0

Sign in to get full access
Overview
- This paper proposes a novel approach to high-fidelity text-to-speech (TTS) synthesis using discrete tokens and a group masked language model.
- The method utilizes a token transducer architecture to generate discrete audio tokens, which are then passed through a group masked language model to produce the final speech waveform.
- The authors claim their approach outperforms existing TTS systems in terms of speech quality, while maintaining efficiency and scalability.
Plain English Explanation
The paper describes a new way to convert written text into high-quality, natural-sounding speech. Instead of generating the speech waveform directly, the researchers' method first creates a series of discrete audio "tokens" that represent the sounds of the speech. These tokens are then processed by a language model that has been specially trained to assemble the tokens into a complete speech waveform.
The key innovation is the use of these discrete audio tokens, which allow the system to better capture the nuances and details of human speech compared to previous TTS approaches. The language model is also designed to work efficiently, enabling the system to generate high-quality speech quickly and without requiring a lot of computing power.
The authors claim their method outperforms existing TTS systems in terms of the fidelity and naturalness of the generated speech. This could have important applications in areas like voice assistants, audiobook narration, and speech-based interfaces, where lifelike, high-quality speech synthesis is essential.
Technical Explanation
The paper introduces a novel text-to-speech (TTS) synthesis system that generates high-fidelity speech by first producing discrete audio tokens and then using a group masked language model to assemble those tokens into a final waveform.
The system starts with a token transducer that takes in text and generates a sequence of discrete audio tokens. These tokens represent the fundamental sounds and attributes of speech, such as phonemes, prosody, and voice quality. The token transducer is trained using a combination of automated speech recognition and TTS data.
The discrete tokens are then passed through a group masked language model, which has been specially designed to assemble the tokens into a high-quality speech waveform. The language model is trained in a self-supervised fashion, learning to predict missing tokens in a group of related tokens.
The researchers demonstrate that their approach, which they call "Token Transducer and Group Masked Language Model" (TT-GMLM), outperforms existing TTS systems on objective measures of speech quality. They also show that the system is efficient and scalable, able to generate speech rapidly while using relatively modest computational resources.
Critical Analysis
The paper presents a compelling approach to high-fidelity TTS that addresses some of the limitations of previous methods. The use of discrete audio tokens allows the system to better capture the nuances of human speech, while the group masked language model provides an efficient way to assemble those tokens into a final waveform.
However, the paper does not delve deeply into the potential limitations or drawbacks of the TT-GMLM approach. For example, the authors do not discuss how the system might perform on more challenging or diverse speech data, such as accented or emotional speech. Additionally, the paper does not address potential privacy or security concerns that could arise from the use of such an advanced TTS system.
Readers may also want to know more about the specific architectural choices and training procedures used in the TT-GMLM model. While the paper provides a high-level overview, more technical details would be helpful for researchers looking to build upon or replicate the work.
Overall, the paper presents a promising new direction for TTS research, but further exploration of the method's limitations and potential real-world applications would strengthen the analysis.
Conclusion
The "High Fidelity Text-to-Speech Via Discrete Tokens Using Token Transducer and Group Masked Language Model" paper introduces a novel approach to generating high-quality, natural-sounding synthetic speech. By utilizing discrete audio tokens and a specialized language model, the researchers have developed a TTS system that outperforms existing methods in terms of speech fidelity and efficiency.
This work has important implications for a wide range of applications, from voice assistants and audiobook narration to speech-based interfaces and accessibility tools. As the demand for lifelike, high-quality speech synthesis continues to grow, the TT-GMLM approach could emerge as a valuable tool for researchers and developers in the field of text-to-speech.
While the paper provides a strong technical foundation, further research is needed to explore the system's performance on more diverse speech data and to address potential limitations or concerns. Nevertheless, this study represents a significant step forward in the quest for truly natural-sounding, high-fidelity text-to-speech synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
High Fidelity Text-to-Speech Via Discrete Tokens Using Token Transducer and Group Masked Language Model
Joun Yeop Lee, Myeonghun Jeong, Minchan Kim, Ji-Hyun Lee, Hoon-Young Cho, Nam Soo Kim
We propose a novel two-stage text-to-speech (TTS) framework with two types of discrete tokens, i.e., semantic and acoustic tokens, for high-fidelity speech synthesis. It features two core components: the Interpreting module, which processes text and a speech prompt into semantic tokens focusing on linguistic contents and alignment, and the Speaking module, which captures the timbre of the target voice to generate acoustic tokens from semantic tokens, enriching speech reconstruction. The Interpreting stage employs a transducer for its robustness in aligning text to speech. In contrast, the Speaking stage utilizes a Conformer-based architecture integrated with a Grouped Masked Language Model (G-MLM) to boost computational efficiency. Our experiments verify that this innovative structure surpasses the conventional models in the zero-shot scenario in terms of speech quality and speaker similarity.
Read more6/26/2024
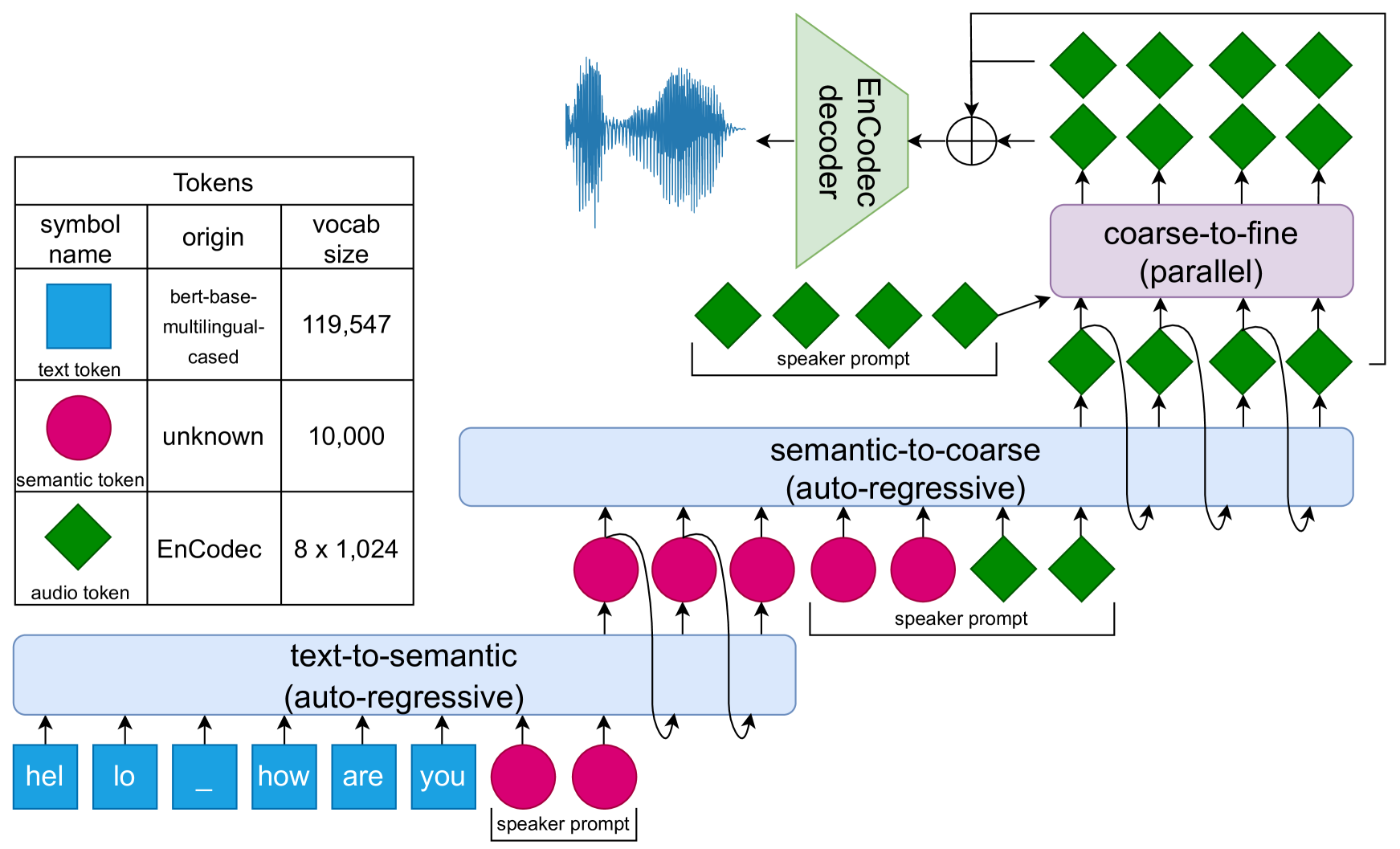
0
Evaluating Text-to-Speech Synthesis from a Large Discrete Token-based Speech Language Model
Siyang Wang, 'Eva Sz'ekely
Recent advances in generative language modeling applied to discrete speech tokens presented a new avenue for text-to-speech (TTS) synthesis. These speech language models (SLMs), similarly to their textual counterparts, are scalable, probabilistic, and context-aware. While they can produce diverse and natural outputs, they sometimes face issues such as unintelligibility and the inclusion of non-speech noises or hallucination. As the adoption of this innovative paradigm in speech synthesis increases, there is a clear need for an in-depth evaluation of its capabilities and limitations. In this paper, we evaluate TTS from a discrete token-based SLM, through both automatic metrics and listening tests. We examine five key dimensions: speaking style, intelligibility, speaker consistency, prosodic variation, spontaneous behaviour. Our results highlight the model's strength in generating varied prosody and spontaneous outputs. It is also rated higher in naturalness and context appropriateness in listening tests compared to a conventional TTS. However, the model's performance in intelligibility and speaker consistency lags behind traditional TTS. Additionally, we show that increasing the scale of SLMs offers a modest boost in robustness. Our findings aim to serve as a benchmark for future advancements in generative SLMs for speech synthesis.
Read more5/17/2024

0
Single-stage TTS with Masked Audio Token Modeling and Semantic Knowledge Distillation
Gerard I. G'allego, Roy Fejgin, Chunghsin Yeh, Xiaoyu Liu, Gautam Bhattacharya
Audio token modeling has become a powerful framework for speech synthesis, with two-stage approaches employing semantic tokens remaining prevalent. In this paper, we aim to simplify this process by introducing a semantic knowledge distillation method that enables high-quality speech generation in a single stage. Our proposed model improves speech quality, intelligibility, and speaker similarity compared to a single-stage baseline. Although two-stage systems still lead in intelligibility, our model significantly narrows the gap while delivering comparable speech quality. These findings showcase the potential of single-stage models to achieve efficient, high-quality TTS with a more compact and streamlined architecture.
Read more9/18/2024

0
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, Zhifu Gao, Zhijie Yan
Recent years have witnessed a trend that large language model (LLM) based text-to-speech (TTS) emerges into the mainstream due to their high naturalness and zero-shot capacity. In this paradigm, speech signals are discretized into token sequences, which are modeled by an LLM with text as prompts and reconstructed by a token-based vocoder to waveforms. Obviously, speech tokens play a critical role in LLM-based TTS models. Current speech tokens are learned in an unsupervised manner, which lacks explicit semantic information and alignment to the text. In this paper, we propose to represent speech with supervised semantic tokens, which are derived from a multilingual speech recognition model by inserting vector quantization into the encoder. Based on the tokens, we further propose a scalable zero-shot TTS synthesizer, CosyVoice, which consists of an LLM for text-to-token generation and a conditional flow matching model for token-to-speech synthesis. Experimental results show that supervised semantic tokens significantly outperform existing unsupervised tokens in terms of content consistency and speaker similarity for zero-shot voice cloning. Moreover, we find that utilizing large-scale data further improves the synthesis performance, indicating the scalable capacity of CosyVoice. To the best of our knowledge, this is the first attempt to involve supervised speech tokens into TTS models.
Read more7/10/2024