Evaluating the Translation Performance of Large Language Models Based on Euas-20

0

Sign in to get full access
Overview
- The paper evaluates the translation performance of large language models (LLMs) using the EUAS-20 dataset.
- It examines how well LLMs can perform cross-lingual translation tasks compared to conventional machine translation models.
- The research provides insights into the strengths and limitations of LLMs for multilingual translation.
Plain English Explanation
The paper investigates how well large language models (LLMs) - powerful AI systems trained on vast amounts of text data - can perform the task of translating between different languages. The researchers used a dataset called EUAS-20, which contains text in multiple languages, to test the translation capabilities of these LLMs.
The key idea is to see if these advanced language models, which have shown impressive abilities in tasks like generating human-like text, can also excel at the challenging problem of translating text between different languages. This is an important question because if LLMs can match or outperform traditional machine translation systems, it could lead to significant improvements in multilingual communication and information sharing.
The researchers compare the performance of LLMs to existing translation models, looking at factors like translation quality, speed, and flexibility. By understanding the strengths and limitations of LLMs for this task, the findings can help guide the development of more powerful and versatile multilingual language models in the future.
Technical Explanation
The paper evaluates the translation performance of large language models (LLMs) using the EUAS-20 dataset. EUAS-20 is a multilingual dataset that contains text in 20 different languages, allowing the researchers to assess the cross-lingual translation abilities of LLMs.
The study compares the translation quality of LLMs, such as GPT-3, to that of conventional machine translation models. The researchers use standard translation evaluation metrics, like BLEU scores, to quantify the accuracy and fluency of the translations produced by the different systems.
In addition to translation quality, the paper also examines other important aspects of translation performance, such as the speed and flexibility of the LLMs. This includes evaluating how well the LLMs can handle tasks like zero-shot translation, where they are asked to translate between language pairs they were not explicitly trained on.
The findings provide insights into the strengths and limitations of LLMs for multilingual translation tasks. The results show that LLMs can achieve competitive translation performance, but also highlight areas where they may still fall short compared to specialized machine translation models. These insights can inform the development of more advanced and versatile multilingual language models in the future.
Critical Analysis
The paper presents a thorough evaluation of LLM translation performance, but there are a few potential limitations or areas for further research:
-
The study only tested a limited set of LLMs, such as GPT-3, and did not include some of the more recently developed models that may have improved translation capabilities.
-
The analysis focused on translation quality metrics, but did not delve deeply into other important aspects like the models' ability to preserve the meaning and nuance of the original text during translation.
-
The paper did not explore how the translation performance of LLMs might vary across different language pairs or domains, which could provide additional insights.
-
While the study compared LLMs to conventional machine translation models, it would be valuable to also explore how LLMs could be combined with or adapted for specific translation tasks to further enhance their performance.
Overall, the research provides a solid foundation for understanding the current state of LLM translation capabilities, but continued exploration and refinement of these models will be necessary to unlock their full potential for multilingual communication and information exchange.
Conclusion
This paper offers a comprehensive evaluation of the translation performance of large language models (LLMs) using the EUAS-20 dataset. The findings suggest that LLMs can achieve competitive translation quality compared to specialized machine translation models, but also highlight areas where they may still have room for improvement.
By understanding the strengths and limitations of LLMs for cross-lingual translation tasks, this research can help guide the development of more advanced and versatile multilingual language models in the future. As LLMs continue to evolve, their potential to significantly enhance global communication and information sharing could become increasingly transformative.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating the Translation Performance of Large Language Models Based on Euas-20
Yan Huang, Wei Liu
In recent years, with the rapid development of deep learning technology, large language models (LLMs) such as BERT and GPT have achieved breakthrough results in natural language processing tasks. Machine translation (MT), as one of the core tasks of natural language processing, has also benefited from the development of large language models and achieved a qualitative leap. Despite the significant progress in translation performance achieved by large language models, machine translation still faces many challenges. Therefore, in this paper, we construct the dataset Euas-20 to evaluate the performance of large language models on translation tasks, the translation ability on different languages, and the effect of pre-training data on the translation ability of LLMs for researchers and developers.
Read more8/7/2024
💬
0
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
Read more6/17/2024

0
GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
Read more5/17/2024
0
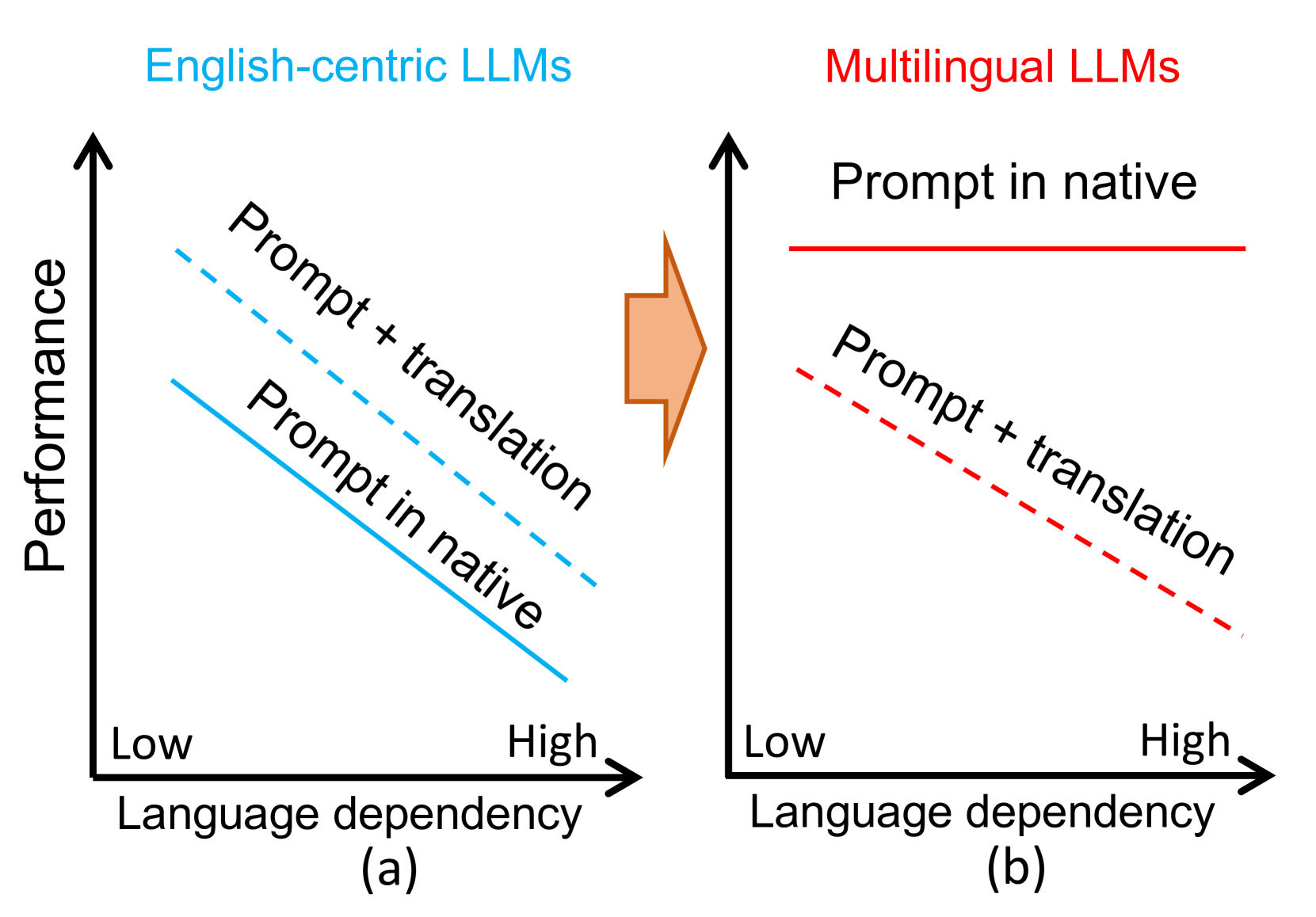
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, Lidong Bing
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
Read more6/21/2024