Evaluating the World Model Implicit in a Generative Model
2406.03689
2
0
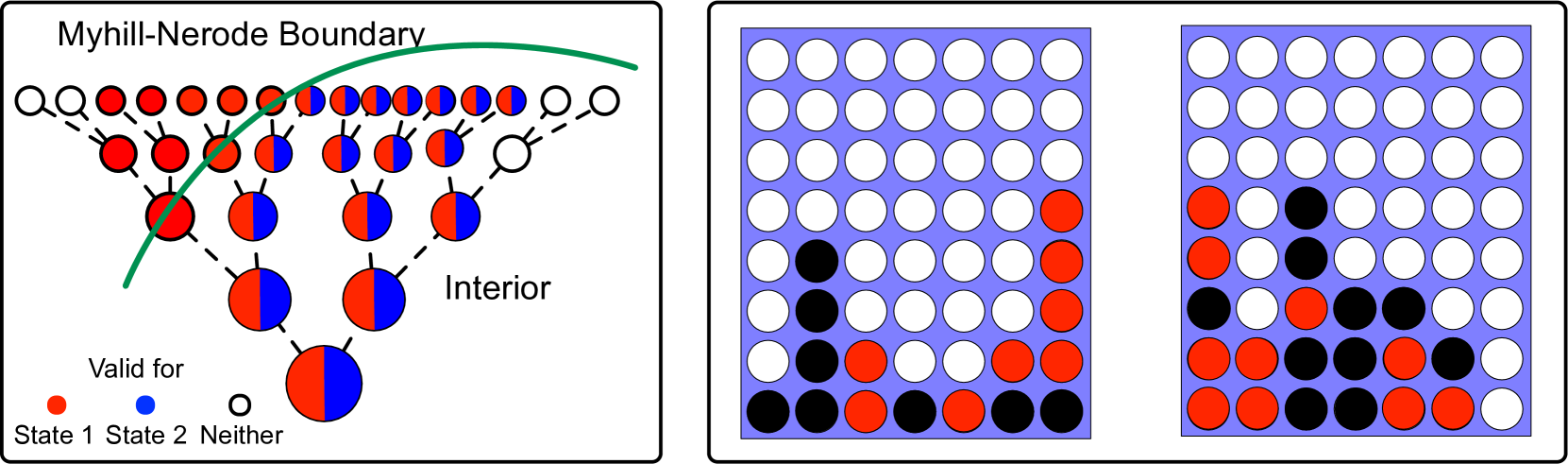
Abstract
Recent work suggests that large language models may implicitly learn world models. How should we assess this possibility? We formalize this question for the case where the underlying reality is governed by a deterministic finite automaton. This includes problems as diverse as simple logical reasoning, geographic navigation, game-playing, and chemistry. We propose new evaluation metrics for world model recovery inspired by the classic Myhill-Nerode theorem from language theory. We illustrate their utility in three domains: game playing, logic puzzles, and navigation. In all domains, the generative models we consider do well on existing diagnostics for assessing world models, but our evaluation metrics reveal their world models to be far less coherent than they appear. Such incoherence creates fragility: using a generative model to solve related but subtly different tasks can lead it to fail badly. Building generative models that meaningfully capture the underlying logic of the domains they model would be immensely valuable; our results suggest new ways to assess how close a given model is to that goal.
Create account to get full access
Overview
- This paper proposes a method to evaluate the world model implicit in a generative model.
- The authors argue that generative models, such as those used in machine learning, often encode an implicit world model that can be examined and understood.
- By analyzing the world model, researchers can gain insights into the biases and limitations of the model, which can help improve the model's performance and safety.
Plain English Explanation
Generative models are a type of machine learning algorithm that can generate new data, like images or text, that looks similar to the data they were trained on. These models often develop an internal representation of the "world" they were trained on, which influences the data they generate.
The researchers in this paper suggest that we can examine this internal world model to better understand the model's biases and limitations. This can help us improve the model's performance and ensure it behaves safely and ethically.
For example, a generative model trained on images of faces might develop an implicit world model that assumes all faces have certain features, like two eyes and a nose. By analyzing this world model, we can identify these assumptions and adjust the model to be more inclusive of diverse facial features.
Similarly, a world model for autonomous driving might make certain assumptions about the behavior of other vehicles or the layout of roads. Understanding these assumptions can help us improve the model's safety and reliability.
Technical Explanation
The paper proposes a framework for evaluating the world model implicit in a generative model. The key steps are:
-
Extracting the world model: The authors show how to extract the world model from a generative model, using techniques like latent space analysis and hierarchical temporal abstractions.
-
Evaluating the world model: The extracted world model is then evaluated along various dimensions, such as its comprehensiveness, its alignment with reality, and its biases and limitations.
-
Improving the world model: Based on the evaluation, the authors suggest ways to improve the world model, such as fine-tuning the generative model or incorporating additional training data.
The paper demonstrates the proposed framework on several examples, including language models and image generation models, showing how the analysis of the implicit world model can provide valuable insights.
Critical Analysis
The paper presents a novel and promising approach for evaluating and improving generative models by examining their implicit world models. However, the authors acknowledge that the proposed framework has some limitations:
- Extracting the world model accurately can be challenging, especially for complex models, and may require significant computational resources.
- The evaluation of the world model is largely subjective and may depend on the specific application and desired properties of the model.
- The paper does not provide a comprehensive list of evaluation metrics or a clear way to prioritize different aspects of the world model.
Additionally, the paper does not address the potential ethical concerns around the biases and limitations of the world model, such as the perpetuation of harmful stereotypes or the exclusion of underrepresented groups. Further research is needed to ensure that the analysis of world models leads to the development of more responsible and equitable generative models.
Conclusion
This paper presents a novel framework for evaluating the world model implicit in a generative model. By examining the internal representations developed by these models, researchers can gain valuable insights into their biases, limitations, and potential safety issues.
The proposed approach has the potential to significantly improve the performance and reliability of generative models, especially in critical applications like autonomous driving, medical diagnosis, and content moderation. However, further research is needed to address the technical and ethical challenges of this method.
Overall, this paper represents an important step towards a deeper understanding of the inner workings of generative models and their potential impact on the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond
Zheng Zhu, Xiaofeng Wang, Wangbo Zhao, Chen Min, Nianchen Deng, Min Dou, Yuqi Wang, Botian Shi, Kai Wang, Chi Zhang, Yang You, Zhaoxiang Zhang, Dawei Zhao, Liang Xiao, Jian Zhao, Jiwen Lu, Guan Huang
0
0
General world models represent a crucial pathway toward achieving Artificial General Intelligence (AGI), serving as the cornerstone for various applications ranging from virtual environments to decision-making systems. Recently, the emergence of the Sora model has attained significant attention due to its remarkable simulation capabilities, which exhibits an incipient comprehension of physical laws. In this survey, we embark on a comprehensive exploration of the latest advancements in world models. Our analysis navigates through the forefront of generative methodologies in video generation, where world models stand as pivotal constructs facilitating the synthesis of highly realistic visual content. Additionally, we scrutinize the burgeoning field of autonomous-driving world models, meticulously delineating their indispensable role in reshaping transportation and urban mobility. Furthermore, we delve into the intricacies inherent in world models deployed within autonomous agents, shedding light on their profound significance in enabling intelligent interactions within dynamic environmental contexts. At last, we examine challenges and limitations of world models, and discuss their potential future directions. We hope this survey can serve as a foundational reference for the research community and inspire continued innovation. This survey will be regularly updated at: https://github.com/GigaAI-research/General-World-Models-Survey.
5/7/2024
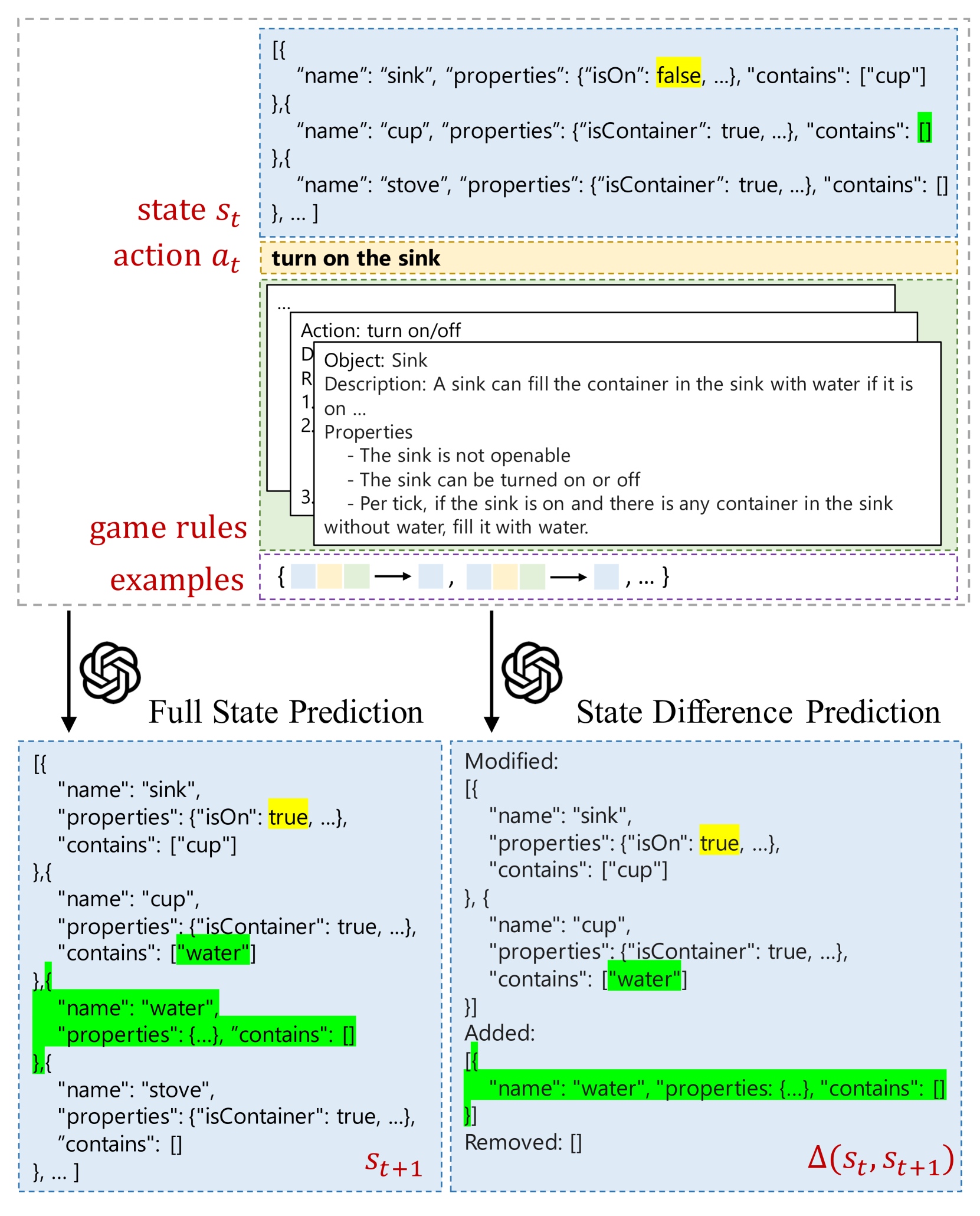
Can Language Models Serve as Text-Based World Simulators?
Ruoyao Wang, Graham Todd, Ziang Xiao, Xingdi Yuan, Marc-Alexandre C^ot'e, Peter Clark, Peter Jansen
0
0
Virtual environments play a key role in benchmarking advances in complex planning and decision-making tasks but are expensive and complicated to build by hand. Can current language models themselves serve as world simulators, correctly predicting how actions change different world states, thus bypassing the need for extensive manual coding? Our goal is to answer this question in the context of text-based simulators. Our approach is to build and use a new benchmark, called ByteSized32-State-Prediction, containing a dataset of text game state transitions and accompanying game tasks. We use this to directly quantify, for the first time, how well LLMs can serve as text-based world simulators. We test GPT-4 on this dataset and find that, despite its impressive performance, it is still an unreliable world simulator without further innovations. This work thus contributes both new insights into current LLM's capabilities and weaknesses, as well as a novel benchmark to track future progress as new models appear.
6/11/2024
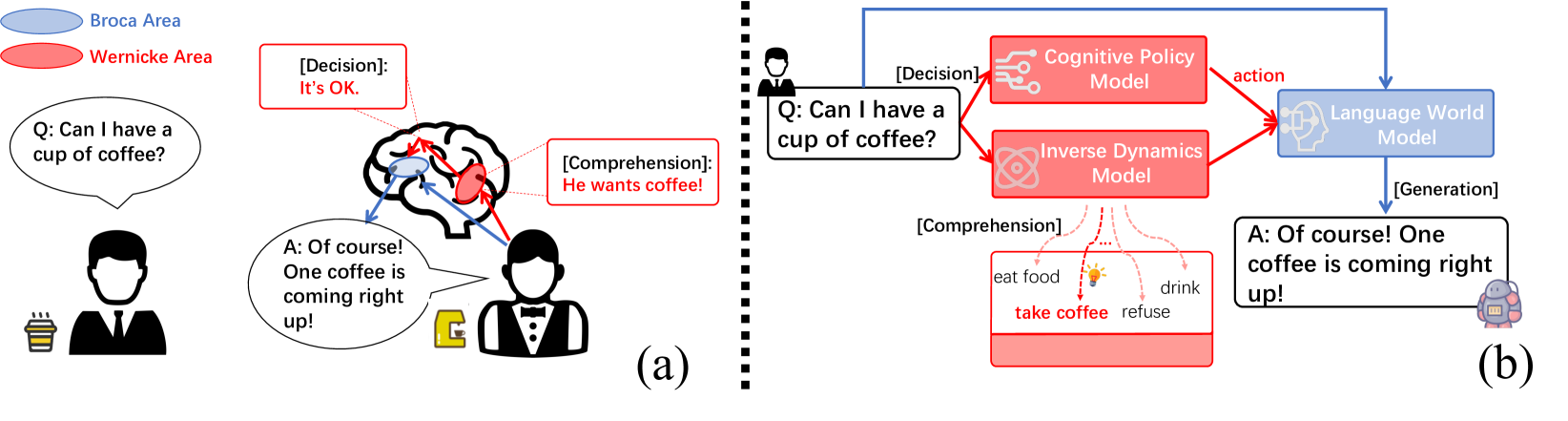
BWArea Model: Learning World Model, Inverse Dynamics, and Policy for Controllable Language Generation
Chengxing Jia, Pengyuan Wang, Ziniu Li, Yi-Chen Li, Zhilong Zhang, Nan Tang, Yang Yu
0
0
Large language models (LLMs) have catalyzed a paradigm shift in natural language processing, yet their limited controllability poses a significant challenge for downstream applications. We aim to address this by drawing inspiration from the neural mechanisms of the human brain, specifically Broca's and Wernicke's areas, which are crucial for language generation and comprehension, respectively. In particular, Broca's area receives cognitive decision signals from Wernicke's area, treating the language generation as an intricate decision-making process, which differs from the fully auto-regressive language generation of existing LLMs. In a similar vein, our proposed system, the BWArea model, conceptualizes language generation as a decision-making task. This model has three components: a language world model, an inverse dynamics model, and a cognitive policy. Like Wernicke's area, the inverse dynamics model is designed to deduce the underlying cognitive intentions, or latent actions, behind each token. The BWArea model is amenable to both pre-training and fine-tuning like existing LLMs. With 30B clean pre-training tokens, we have trained a BWArea model, which achieves competitive performance with LLMs of equal size (1B parameters). Unlike fully auto-regressive LLMs, its pre-training performance does not degenerate if dirty data unintentionally appears. This shows the advantage of a decomposed structure of BWArea model in reducing efforts in laborious data selection and labeling. Finally, we reveal that the BWArea model offers enhanced controllability via fine-tuning the cognitive policy with downstream reward metrics, thereby facilitating alignment with greater simplicity. On 9 out of 10 tasks from two suites, TextWorld and BigBench Hard, our method shows superior performance to auto-regressive LLMs.
5/28/2024
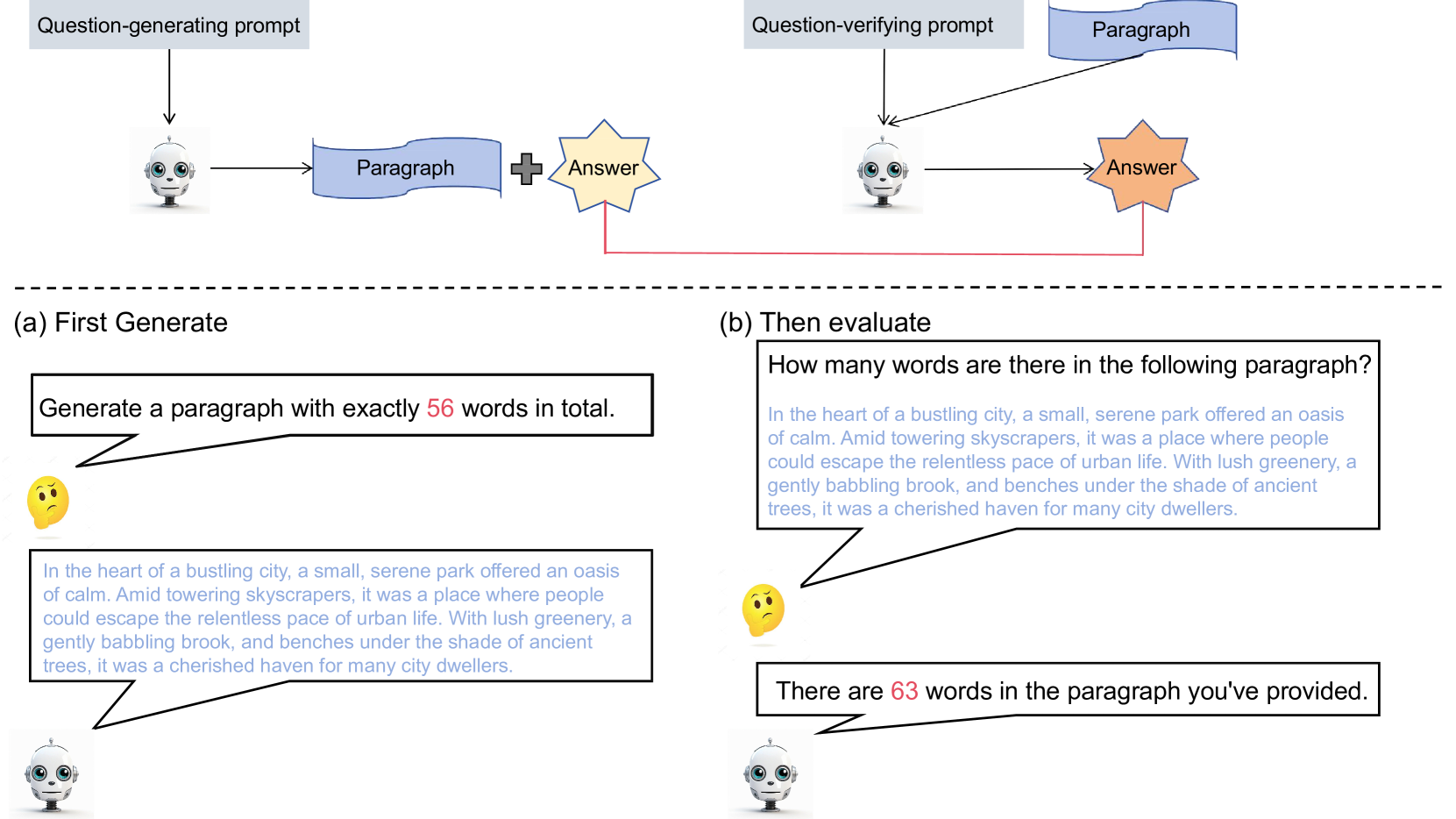
Can I understand what I create? Self-Knowledge Evaluation of Large Language Models
Zhiquan Tan, Lai Wei, Jindong Wang, Xing Xie, Weiran Huang
0
0
Large language models (LLMs) have achieved remarkable progress in linguistic tasks, necessitating robust evaluation frameworks to understand their capabilities and limitations. Inspired by Feynman's principle of understanding through creation, we introduce a self-knowledge evaluation framework that is easy to implement, evaluating models on their ability to comprehend and respond to self-generated questions. Our findings, based on testing multiple models across diverse tasks, reveal significant gaps in the model's self-knowledge ability. Further analysis indicates these gaps may be due to misalignment with human attention mechanisms. Additionally, fine-tuning on self-generated math task may enhance the model's math performance, highlighting the potential of the framework for efficient and insightful model evaluation and may also contribute to the improvement of LLMs.
6/11/2024