BWArea Model: Learning World Model, Inverse Dynamics, and Policy for Controllable Language Generation
2405.17039
0
0
Abstract
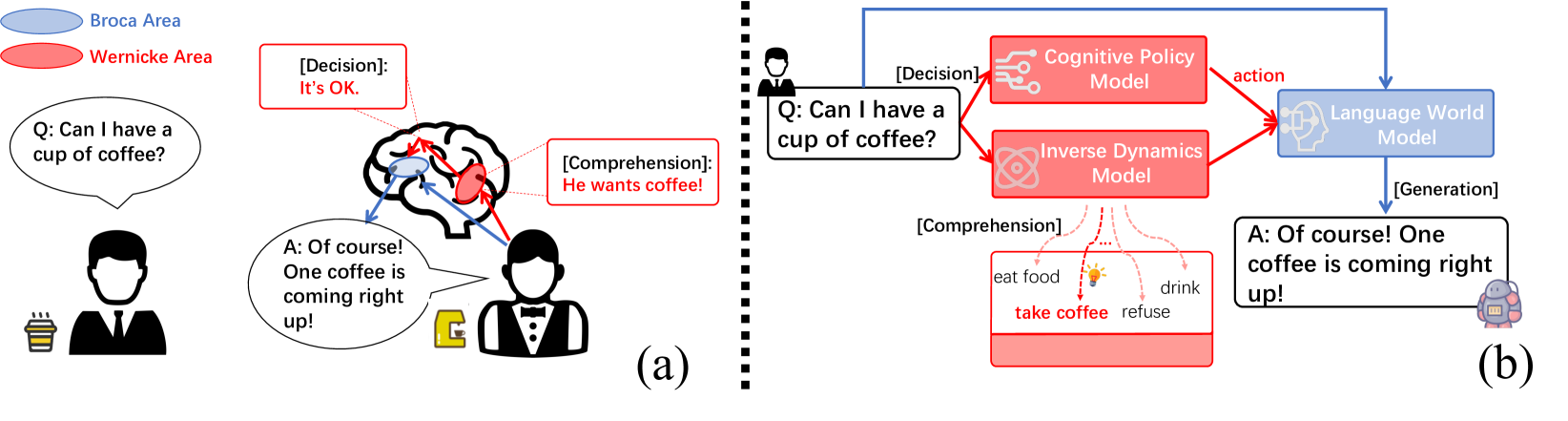
Large language models (LLMs) have catalyzed a paradigm shift in natural language processing, yet their limited controllability poses a significant challenge for downstream applications. We aim to address this by drawing inspiration from the neural mechanisms of the human brain, specifically Broca's and Wernicke's areas, which are crucial for language generation and comprehension, respectively. In particular, Broca's area receives cognitive decision signals from Wernicke's area, treating the language generation as an intricate decision-making process, which differs from the fully auto-regressive language generation of existing LLMs. In a similar vein, our proposed system, the BWArea model, conceptualizes language generation as a decision-making task. This model has three components: a language world model, an inverse dynamics model, and a cognitive policy. Like Wernicke's area, the inverse dynamics model is designed to deduce the underlying cognitive intentions, or latent actions, behind each token. The BWArea model is amenable to both pre-training and fine-tuning like existing LLMs. With 30B clean pre-training tokens, we have trained a BWArea model, which achieves competitive performance with LLMs of equal size (1B parameters). Unlike fully auto-regressive LLMs, its pre-training performance does not degenerate if dirty data unintentionally appears. This shows the advantage of a decomposed structure of BWArea model in reducing efforts in laborious data selection and labeling. Finally, we reveal that the BWArea model offers enhanced controllability via fine-tuning the cognitive policy with downstream reward metrics, thereby facilitating alignment with greater simplicity. On 9 out of 10 tasks from two suites, TextWorld and BigBench Hard, our method shows superior performance to auto-regressive LLMs.
Create account to get full access
Overview
- The paper proposes the BWArea model, which learns a world model, inverse dynamics, and policy for controllable language generation.
- The model aims to address the challenge of achieving fine-grained control over language generation while maintaining coherence and consistency.
- The authors explore using reinforcement learning to train the model, which allows for direct optimization of desired properties in the generated language.
Plain English Explanation
The BWArea model is a system designed to generate language in a more controlled and purposeful way. One of the key challenges in language generation is maintaining coherence and consistency while also being able to fine-tune the output to achieve specific goals or characteristics. The BWArea model tackles this by learning a internal "world model" that represents the relationships between different concepts and ideas. This world model is then used to guide the language generation process, allowing the system to generate text that is aligned with the desired properties.
The authors use reinforcement learning techniques to train the BWArea model, which means they define specific objectives or "rewards" that the model tries to optimize for. For example, the model could be rewarded for generating text that is coherent, on-topic, and has a particular tone or style. By directly optimizing for these desired qualities, the BWArea model is able to produce language that is more controllable and tailored to the user's needs.
The key innovation of this work is the integration of the world model, inverse dynamics, and policy components, which work together to enable this fine-grained control over the generated language. The world model captures the underlying structure of language and concepts, the inverse dynamics model translates high-level objectives into low-level actions, and the policy module actually generates the text.
Technical Explanation
The BWArea model consists of three main components: a world model, an inverse dynamics model, and a policy model. The world model learns to represent the relationships between different concepts and ideas, capturing the underlying structure of language and knowledge. The inverse dynamics model then translates high-level objectives or desired properties into low-level actions that can be taken by the policy model to generate text.
The policy model is responsible for the actual language generation, but it does so in a more controlled and targeted way thanks to the guidance provided by the world model and inverse dynamics components. This allows the BWArea model to optimize the generated text for specific qualities, such as coherence, topic relevance, and stylistic attributes.
The authors train the BWArea model using reinforcement learning, where the model is rewarded for generating text that aligns with the desired properties. This is in contrast to more traditional language models that are trained solely on predicting the next word in a sequence. By directly optimizing for the target qualities, the BWArea model is able to achieve finer-grained control over the language generation process while maintaining overall coherence and consistency.
Critical Analysis
The BWArea model represents an interesting approach to addressing the challenge of controllable language generation. By integrating the world model, inverse dynamics, and policy components, the authors have created a system that can generate text with more targeted and fine-grained control.
One potential limitation of the approach is the reliance on reinforcement learning, which can be computationally intensive and may require careful hyperparameter tuning to achieve good results. Additionally, the performance of the model is likely to be heavily dependent on the quality and coverage of the world model, which could be a limiting factor if the underlying knowledge representation is incomplete or biased.
It would also be valuable to see more extensive evaluation of the model's capabilities, particularly in terms of its ability to maintain coherence and consistency while achieving specific stylistic or topical objectives. The paper provides some initial results, but a more thorough assessment of the model's strengths and weaknesses would help to better understand its potential applications and limitations.
Overall, the BWArea model represents an interesting step towards more controllable and purposeful language generation. As the field of natural language processing continues to advance, approaches like this that integrate different components and leverage reinforcement learning may become increasingly important for developing systems that can generate language tailored to specific needs and contexts.
Conclusion
The BWArea model proposed in this paper offers a novel approach to the challenge of controllable language generation. By learning a world model, inverse dynamics, and policy, the system is able to generate text that is not only coherent and consistent, but can also be fine-tuned to achieve specific objectives or desired properties.
The use of reinforcement learning to directly optimize the generated language for target qualities is a particularly interesting aspect of the work, as it allows the model to be trained in a more targeted and purposeful way. While the approach may have some limitations in terms of computational complexity and the quality of the underlying world model, the overall concept represents an important step towards developing more versatile and capable language generation systems.
As the field of natural language processing continues to evolve, models like the BWArea that integrate multiple components and leverage advanced training techniques may become increasingly valuable for a wide range of applications, from creative writing to task-oriented dialogue systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Cognitively Inspired Energy-Based World Models
Alexi Gladstone, Ganesh Nanduru, Md Mofijul Islam, Aman Chadha, Jundong Li, Tariq Iqbal
0
0
One of the predominant methods for training world models is autoregressive prediction in the output space of the next element of a sequence. In Natural Language Processing (NLP), this takes the form of Large Language Models (LLMs) predicting the next token; in Computer Vision (CV), this takes the form of autoregressive models predicting the next frame/token/pixel. However, this approach differs from human cognition in several respects. First, human predictions about the future actively influence internal cognitive processes. Second, humans naturally evaluate the plausibility of predictions regarding future states. Based on this capability, and third, by assessing when predictions are sufficient, humans allocate a dynamic amount of time to make a prediction. This adaptive process is analogous to System 2 thinking in psychology. All these capabilities are fundamental to the success of humans at high-level reasoning and planning. Therefore, to address the limitations of traditional autoregressive models lacking these human-like capabilities, we introduce Energy-Based World Models (EBWM). EBWM involves training an Energy-Based Model (EBM) to predict the compatibility of a given context and a predicted future state. In doing so, EBWM enables models to achieve all three facets of human cognition described. Moreover, we developed a variant of the traditional autoregressive transformer tailored for Energy-Based models, termed the Energy-Based Transformer (EBT). Our results demonstrate that EBWM scales better with data and GPU Hours than traditional autoregressive transformers in CV, and that EBWM offers promising early scaling in NLP. Consequently, this approach offers an exciting path toward training future models capable of System 2 thinking and intelligently searching across state spaces.
6/14/2024
Evaluating the World Model Implicit in a Generative Model
Keyon Vafa, Justin Y. Chen, Jon Kleinberg, Sendhil Mullainathan, Ashesh Rambachan
0
0
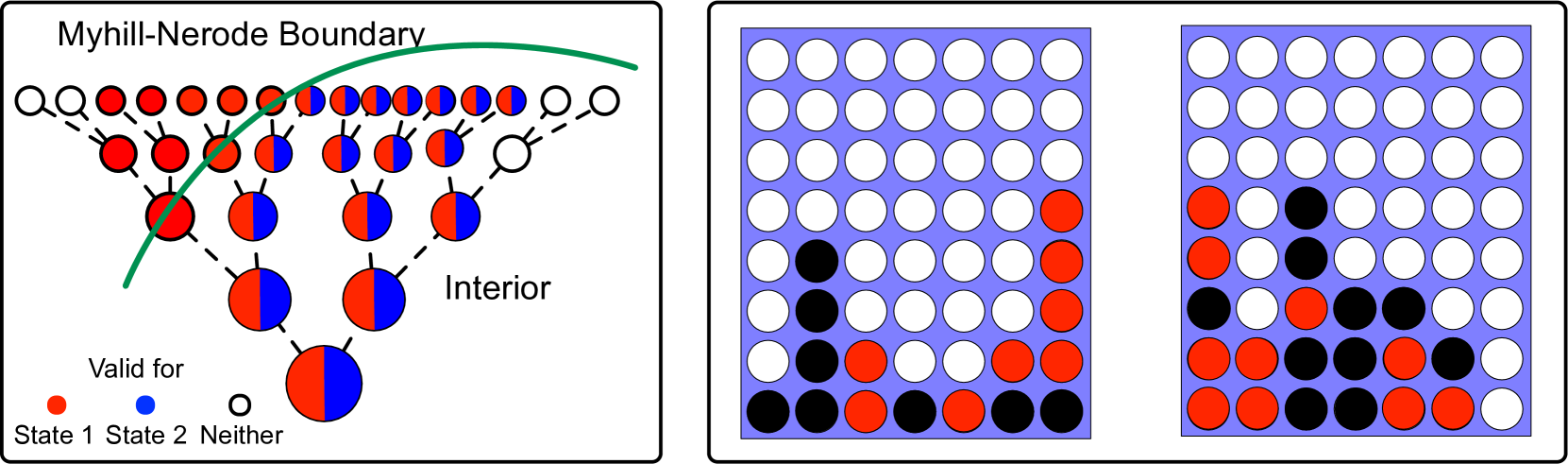
Recent work suggests that large language models may implicitly learn world models. How should we assess this possibility? We formalize this question for the case where the underlying reality is governed by a deterministic finite automaton. This includes problems as diverse as simple logical reasoning, geographic navigation, game-playing, and chemistry. We propose new evaluation metrics for world model recovery inspired by the classic Myhill-Nerode theorem from language theory. We illustrate their utility in three domains: game playing, logic puzzles, and navigation. In all domains, the generative models we consider do well on existing diagnostics for assessing world models, but our evaluation metrics reveal their world models to be far less coherent than they appear. Such incoherence creates fragility: using a generative model to solve related but subtly different tasks can lead it to fail badly. Building generative models that meaningfully capture the underlying logic of the domains they model would be immensely valuable; our results suggest new ways to assess how close a given model is to that goal.
6/26/2024
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
0
0
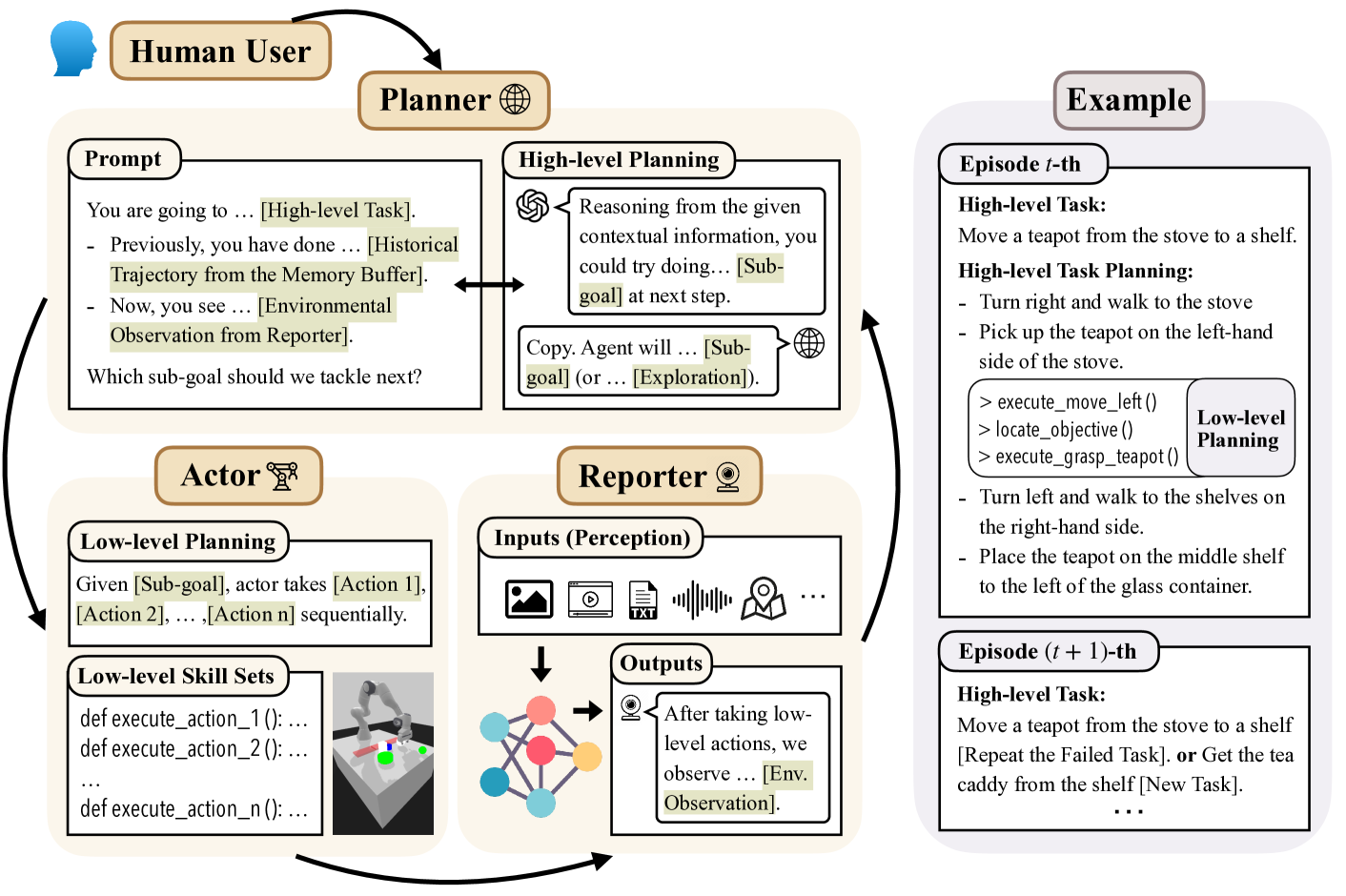
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
5/31/2024
💬
Policy Learning with a Language Bottleneck
Megha Srivastava, Cedric Colas, Dorsa Sadigh, Jacob Andreas
0
0
Modern AI systems such as self-driving cars and game-playing agents achieve superhuman performance, but often lack human-like features such as generalization, interpretability and human inter-operability. Inspired by the rich interactions between language and decision-making in humans, we introduce Policy Learning with a Language Bottleneck (PLLB), a framework enabling AI agents to generate linguistic rules that capture the strategies underlying their most rewarding behaviors. PLLB alternates between a rule generation step guided by language models, and an update step where agents learn new policies guided by rules. In a two-player communication game, a maze solving task, and two image reconstruction tasks, we show that PLLB agents are not only able to learn more interpretable and generalizable behaviors, but can also share the learned rules with human users, enabling more effective human-AI coordination.
5/8/2024