Evaluating Zero-Shot Long-Context LLM Compression
2406.06773
0
0

Abstract
This study evaluates the effectiveness of zero-shot compression techniques on large language models (LLMs) under long-context. We identify the tendency for computational errors to increase under long-context when employing certain compression methods. We propose a hypothesis to explain the varied behavior of different LLM compression techniques and explore remedies to mitigate the performance decline observed in some techniques under long-context. This is a course report for COS 598D Machine Learning and Systems by Prof. Kai Li at Princeton University. Due to limited computational resources, our experiments were conducted only on LLaMA-2-7B-32K.
Create account to get full access
Overview
- This paper evaluates techniques for compressing the long-term context used by large language models (LLMs) to improve their performance on tasks requiring long-term reasoning.
- The researchers investigate "zero-shot" compression methods that can compress and decompress the context without any additional training.
- The paper compares the performance of these zero-shot compression techniques to more traditional approaches that require fine-tuning the LLM on compressed text.
Plain English Explanation
Modern LLMs are incredibly powerful, but they struggle with tasks that require understanding and reasoning over long passages of text. This is because the models have a limited "context window" - they can only consider a certain number of previous words when generating new text. To address this, researchers have developed techniques to compress the long-term context used by LLMs, allowing them to reason over a larger amount of information.
This paper explores "zero-shot" compression methods, which can compress and decompress the context without requiring any additional training of the LLM. This is in contrast to other approaches that need to fine-tune the LLM on the compressed text. The researchers compare the performance of these zero-shot techniques to the more traditional fine-tuning approach, to see which one works best for improving long-term reasoning in LLMs.
The key idea behind zero-shot compression is to use a separate neural network to compress the long-term context, without modifying the LLM itself. This allows the LLM to continue using its existing capabilities, while benefiting from the expanded context window provided by the compression. The paper investigates different zero-shot compression architectures and evaluates their effectiveness on benchmark tasks that require long-term understanding.
Technical Explanation
The paper introduces several zero-shot compression techniques and compares them to a fine-tuning approach on the LOCO and XNLI-LC benchmarks, which test an LLM's ability to reason over long passages of text.
The zero-shot compression methods include:
- Recurrent Context Compression (RCC): A recurrent neural network that compresses the long-term context into a fixed-size representation, inspired by Recurrent Context Compression.
- Informer-based LLM (InflLM): A transformer-based model that compresses the context, based on the InflLM architecture.
- Concatenation-based Compression: A simpler approach that simply concatenates the compressed context with the LLM's input.
The researchers compare the performance of these zero-shot methods to a fine-tuning approach, where the LLM is trained directly on the compressed text. They evaluate the models on both the LOCO and XNLI-LC benchmarks, measuring metrics like F1 score and accuracy.
The results show that the zero-shot compression techniques can match or even outperform the fine-tuning approach, demonstrating the potential of this more efficient and flexible compression strategy. The paper provides insights into the tradeoffs between different compression architectures and highlights opportunities for further research in this area.
Critical Analysis
The paper presents a thorough evaluation of zero-shot compression techniques for improving long-term reasoning in LLMs. The researchers carefully designed their experiments to compare the zero-shot methods to a fine-tuning baseline, providing a fair and comprehensive assessment.
One potential limitation is that the paper only evaluates the compression approaches on two specific benchmarks (LOCO and XNLI-LC). While these are well-established tests of long-term reasoning, it would be valuable to see how the techniques perform on a wider range of tasks and datasets. Additionally, the paper does not provide much insight into the computational and memory efficiency of the various compression methods, which could be an important practical consideration.
Another area for further research is the interaction between the compression model and the LLM. The paper treats them as separate components, but there may be opportunities to more tightly integrate the compression and language modeling capabilities to achieve even better performance. Exploring techniques like joint training or dynamic context expansion could be fruitful avenues to investigate.
Overall, this paper makes a valuable contribution by demonstrating the potential of zero-shot compression methods for improving long-term reasoning in LLMs. The findings highlight the importance of continued research in this area, as the ability to efficiently leverage long-term context is crucial for advancing the capabilities of these powerful language models.
Conclusion
This paper evaluates zero-shot compression techniques for improving the long-term reasoning capabilities of large language models (LLMs). The researchers introduce several novel compression architectures and compare their performance to a fine-tuning approach on benchmark tasks that require understanding and reasoning over long passages of text.
The key finding is that the zero-shot compression methods can match or even outperform the fine-tuning approach, providing a more efficient and flexible way to expand the context window used by LLMs. This suggests that zero-shot compression is a promising direction for enhancing the long-term reasoning abilities of these powerful language models, with potential applications in areas like long-form text generation, question answering, and document understanding.
The paper provides a solid foundation for further research in this area, highlighting opportunities to explore more advanced compression architectures, tighter integration between the compression and language modeling components, and evaluation on a wider range of tasks. Continued advances in long-term context compression could unlock significant improvements in the capabilities of large language models, with far-reaching implications for various natural language processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ZeroDL: Zero-shot Distribution Learning for Text Clustering via Large Language Models
Hwiyeol Jo, Hyunwoo Lee, Taiwoo Park
0
0
The recent advancements in large language models (LLMs) have brought significant progress in solving NLP tasks. Notably, in-context learning (ICL) is the key enabling mechanism for LLMs to understand specific tasks and grasping nuances. In this paper, we propose a simple yet effective method to contextualize a task toward a specific LLM, by (1) observing how a given LLM describes (all or a part of) target datasets, i.e., open-ended zero-shot inference, and (2) aggregating the open-ended inference results by the LLM, and (3) finally incorporate the aggregated meta-information for the actual task. We show the effectiveness of this approach in text clustering tasks, and also highlight the importance of the contextualization through examples of the above procedure.
6/21/2024
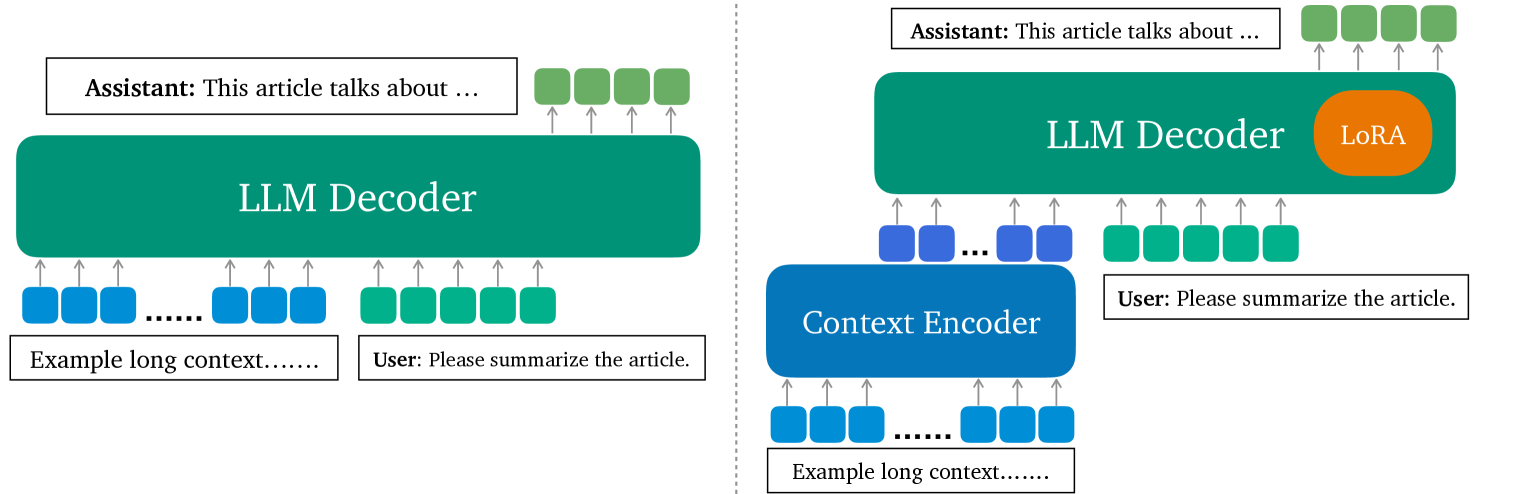
LLoCO: Learning Long Contexts Offline
Sijun Tan, Xiuyu Li, Shishir Patil, Ziyang Wu, Tianjun Zhang, Kurt Keutzer, Joseph E. Gonzalez, Raluca Ada Popa
0
0
Processing long contexts remains a challenge for large language models (LLMs) due to the quadratic computational and memory overhead of the self-attention mechanism and the substantial KV cache sizes during generation. We propose a novel approach to address this problem by learning contexts offline through context compression and in-domain parameter-efficient finetuning. Our method enables an LLM to create a concise representation of the original context and efficiently retrieve relevant information to answer questions accurately. We introduce LLoCO, a technique that combines context compression, retrieval, and parameter-efficient finetuning using LoRA. Our approach extends the effective context window of a 4k token LLaMA2-7B model to handle up to 128k tokens. We evaluate our approach on several long-context question-answering datasets, demonstrating that LLoCO significantly outperforms in-context learning while using $30times$ fewer tokens during inference. LLoCO achieves up to $7.62times$ speed-up and substantially reduces the cost of long document question answering, making it a promising solution for efficient long context processing. Our code is publicly available at https://github.com/jeffreysijuntan/lloco.
4/12/2024
🏷️
Ranking LLMs by compression
Peijia Guo, Ziguang Li, Haibo Hu, Chao Huang, Ming Li, Rui Zhang
0
0
We conceptualize the process of understanding as information compression, and propose a method for ranking large language models (LLMs) based on lossless data compression. We demonstrate the equivalence of compression length under arithmetic coding with cumulative negative log probabilities when using a large language model as a prior, that is, the pre-training phase of the model is essentially the process of learning the optimal coding length. At the same time, the evaluation metric compression ratio can be obtained without actual compression, which greatly saves overhead. In this paper, we use five large language models as priors for compression, then compare their performance on challenging natural language processing tasks, including sentence completion, question answering, and coreference resolution. Experimental results show that compression ratio and model performance are positively correlated, so it can be used as a general metric to evaluate large language models.
6/21/2024

Long-context LLMs Struggle with Long In-context Learning
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, Wenhu Chen
0
0
Large Language Models (LLMs) have made significant strides in handling long sequences. Some models like Gemini could even to be capable of dealing with millions of tokens. However, their performance evaluation has largely been confined to metrics like perplexity and synthetic tasks, which may not fully capture their true abilities in more challenging, real-world scenarios. We introduce a benchmark (LongICLBench) for long in-context learning in extreme-label classification using six datasets with 28 to 174 classes and input lengths from 2K to 50K tokens. Our benchmark requires LLMs to comprehend the entire input to recognize the massive label spaces to make correct predictions. We evaluate on 15 long-context LLMs and find that they perform well on less challenging classification tasks with smaller label space and shorter demonstrations. However, they struggle with more challenging task like Discovery with 174 labels, suggesting a gap in their ability to process long, context-rich sequences. Further analysis reveals a bias towards labels presented later in the sequence and a need for improved reasoning over multiple pieces of information. Our study reveals that long context understanding and reasoning is still a challenging task for the existing LLMs. We believe LongICLBench could serve as a more realistic evaluation for the future long-context LLMs.
6/13/2024