Training LLMs over Neurally Compressed Text
2404.03626
1
11
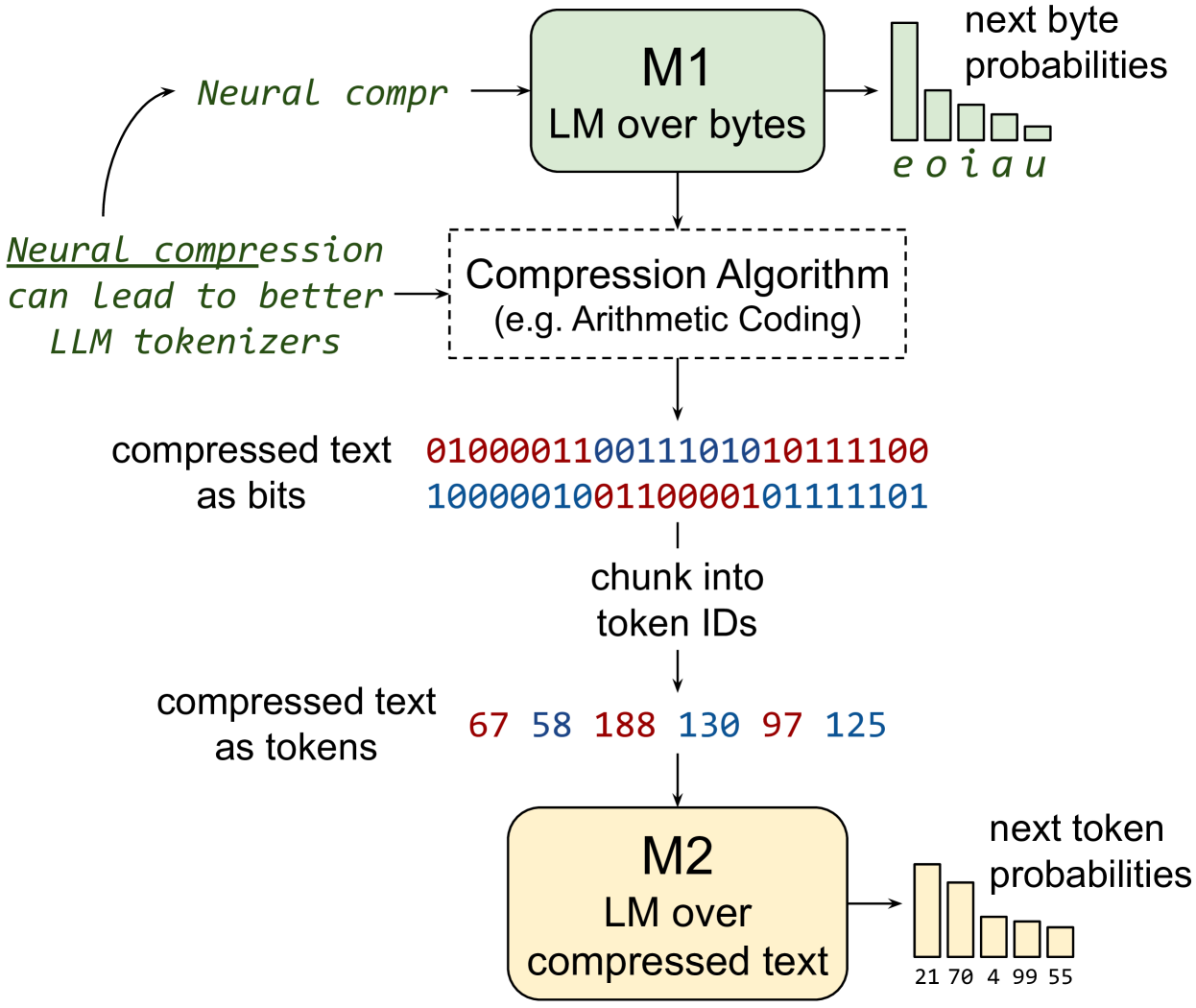
Abstract
In this paper, we explore the idea of training large language models (LLMs) over highly compressed text. While standard subword tokenizers compress text by a small factor, neural text compressors can achieve much higher rates of compression. If it were possible to train LLMs directly over neurally compressed text, this would confer advantages in training and serving efficiency, as well as easier handling of long text spans. The main obstacle to this goal is that strong compression tends to produce opaque outputs that are not well-suited for learning. In particular, we find that text naively compressed via Arithmetic Coding is not readily learnable by LLMs. To overcome this, we propose Equal-Info Windows, a novel compression technique whereby text is segmented into blocks that each compress to the same bit length. Using this method, we demonstrate effective learning over neurally compressed text that improves with scale, and outperforms byte-level baselines by a wide margin on perplexity and inference speed benchmarks. While our method delivers worse perplexity than subword tokenizers for models trained with the same parameter count, it has the benefit of shorter sequence lengths. Shorter sequence lengths require fewer autoregressive generation steps, and reduce latency. Finally, we provide extensive analysis of the properties that contribute to learnability, and offer concrete suggestions for how to further improve the performance of high-compression tokenizers.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the potential benefits of training large language models (LLMs) on neurally compressed text, rather than the original uncompressed text.
- The authors propose that training LLMs on compressed text can lead to improved performance, reduced model size, and faster inference times.
- They investigate the effects of different neural compression techniques, such as Learning to Compress Prompt Natural Language Formats and Transforming LLMs into Cross-Modal, Cross-Lingual Engines, on the training and performance of LLMs.
Plain English Explanation
The paper investigates a novel approach to training large language models (LLMs), which are powerful AI systems that can understand and generate human-like text. Instead of training these models on the original, uncompressed text, the researchers explored the benefits of training them on text that has been "compressed" using neural networks.
Neural compression is a technique that can reduce the size of text data by encoding it in a more efficient way, similar to how image and video files are compressed. The researchers hypothesized that training LLMs on this compressed text could lead to several advantages, such as:
- Improved performance: The compressed text may contain more relevant information, allowing the LLM to learn more effectively.
- Reduced model size: The compressed text requires less storage space, which could lead to smaller and more efficient LLM models.
- Faster inference: Smaller models generally run faster, which could make the LLM's text generation and analysis tasks more efficient.
To test these ideas, the researchers experimented with different neural compression techniques, such as those described in Learning to Compress Prompt Natural Language Formats and Transforming LLMs into Cross-Modal, Cross-Lingual Engines. They then trained LLMs on the compressed text and evaluated the models' performance, size, and inference speed.
Technical Explanation
The paper investigates the potential benefits of training large language models (LLMs) on neurally compressed text, rather than the original uncompressed text. The authors propose that this approach can lead to improved model performance, reduced model size, and faster inference times.
The researchers explore the effects of different neural compression techniques on the training and performance of LLMs. These compression methods, such as those described in Learning to Compress Prompt Natural Language Formats and Transforming LLMs into Cross-Modal, Cross-Lingual Engines, aim to encode the text in a more efficient way, reducing its size while preserving the essential information.
The authors hypothesize that training LLMs on this compressed text could lead to several advantages:
- Improved performance: The compressed text may contain more relevant information, allowing the LLM to learn more effectively.
- Reduced model size: The compressed text requires less storage space, which could lead to smaller and more efficient LLM models.
- Faster inference: Smaller models generally run faster, which could make the LLM's text generation and analysis tasks more efficient.
To test these hypotheses, the researchers conducted experiments where they trained LLMs on both the original uncompressed text and the neurally compressed text. They then evaluated the models' performance, size, and inference speed, comparing the results between the two approaches.
The paper presents the experimental design, the specific neural compression techniques used, and the insights gained from the study. The results aim to inform the development of more efficient and effective LLMs, which have a wide range of applications in natural language processing and generation.
Critical Analysis
The paper presents a compelling investigation into the potential benefits of training large language models (LLMs) on neurally compressed text. The researchers' hypotheses are well-grounded in the existing literature, such as the work on Learning to Compress Prompt Natural Language Formats and Transforming LLMs into Cross-Modal, Cross-Lingual Engines, which have shown the promise of neural compression techniques.
One potential limitation of the study is the scope of the evaluation. The authors primarily focus on the model's performance, size, and inference speed, but do not delve deeply into the potential impact on the model's generalization capabilities or its ability to handle long-context learning, as discussed in Long-Context LLMs Struggle with Long-Context Learning. Further research could explore these aspects to provide a more comprehensive understanding of the trade-offs involved in training LLMs on neurally compressed text.
Additionally, the paper does not address the potential challenges of CLAM-TTS: Improving Neural Codec Language Model or the implications for large language models and mathematicians. These areas could be explored in future work to better understand the broader impact and limitations of the proposed approach.
Overall, the paper presents a well-designed study with promising results. The findings could have significant implications for the development of more efficient and effective LLMs, which are increasingly important in a wide range of applications. Further research to address the identified limitations and explore additional aspects would help strengthen the impact of this work.
Conclusion
This paper explores the potential benefits of training large language models (LLMs) on neurally compressed text, rather than the original uncompressed text. The authors propose that this approach can lead to improved model performance, reduced model size, and faster inference times.
The researchers investigate the effects of different neural compression techniques on the training and performance of LLMs. Their experiments show that training LLMs on compressed text can offer several advantages, such as improved model accuracy, smaller model size, and faster inference speed.
These findings have important implications for the development of more efficient and effective LLMs, which are crucial for a wide range of natural language processing and generation tasks. The insights from this study could help researchers and practitioners create more powerful and resource-efficient language models, with potential applications in areas like machine translation, text summarization, and conversational AI.
Further research is needed to explore the broader implications of training LLMs on neurally compressed text, such as its impact on model generalization and long-context learning. Nonetheless, this paper presents a valuable contribution to the ongoing efforts to improve the performance and efficiency of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Lightweight Conceptual Dictionary Learning for Text Classification Using Information Compression
Li Wan, Tansu Alpcan, Margreta Kuijper, Emanuele Viterbo
0
0
We propose a novel, lightweight supervised dictionary learning framework for text classification based on data compression and representation. This two-phase algorithm initially employs the Lempel-Ziv-Welch (LZW) algorithm to construct a dictionary from text datasets, focusing on the conceptual significance of dictionary elements. Subsequently, dictionaries are refined considering label data, optimizing dictionary atoms to enhance discriminative power based on mutual information and class distribution. This process generates discriminative numerical representations, facilitating the training of simple classifiers such as SVMs and neural networks. We evaluate our algorithm's information-theoretic performance using information bottleneck principles and introduce the information plane area rank (IPAR) as a novel metric to quantify the information-theoretic performance. Tested on six benchmark text datasets, our algorithm competes closely with top models, especially in limited-vocabulary contexts, using significantly fewer parameters. review{Our algorithm closely matches top-performing models, deviating by only ~2% on limited-vocabulary datasets, using just 10% of their parameters. However, it falls short on diverse-vocabulary datasets, likely due to the LZW algorithm's constraints with low-repetition data. This contrast highlights its efficiency and limitations across different dataset types.
5/6/2024
💬
New!CompactifAI: Extreme Compression of Large Language Models using Quantum-Inspired Tensor Networks
Andrei Tomut, Saeed S. Jahromi, Abhijoy Sarkar, Uygar Kurt, Sukhbinder Singh, Faysal Ishtiaq, Cesar Mu~noz, Prabdeep Singh Bajaj, Ali Elborady, Gianni del Bimbo, Mehrazin Alizadeh, David Montero, Pablo Martin-Ramiro, Muhammad Ibrahim, Oussama Tahiri Alaoui, John Malcolm, Samuel Mugel, Roman Orus
0
0
Large Language Models (LLMs) such as ChatGPT and LlaMA are advancing rapidly in generative Artificial Intelligence (AI), but their immense size poses significant challenges, such as huge training and inference costs, substantial energy demands, and limitations for on-site deployment. Traditional compression methods such as pruning, distillation, and low-rank approximation focus on reducing the effective number of neurons in the network, while quantization focuses on reducing the numerical precision of individual weights to reduce the model size while keeping the number of neurons fixed. While these compression methods have been relatively successful in practice, there is no compelling reason to believe that truncating the number of neurons is an optimal strategy. In this context, this paper introduces CompactifAI, an innovative LLM compression approach using quantum-inspired Tensor Networks that focuses on the model's correlation space instead, allowing for a more controlled, refined and interpretable model compression. Our method is versatile and can be implemented with - or on top of - other compression techniques. As a benchmark, we demonstrate that a combination of CompactifAI with quantization allows to reduce a 93% the memory size of LlaMA 7B, reducing also 70% the number of parameters, accelerating 50% the training and 25% the inference times of the model, and just with a small accuracy drop of 2% - 3%, going much beyond of what is achievable today by other compression techniques. Our methods also allow to perform a refined layer sensitivity profiling, showing that deeper layers tend to be more suitable for tensor network compression, which is compatible with recent observations on the ineffectiveness of those layers for LLM performance. Our results imply that standard LLMs are, in fact, heavily overparametrized, and do not need to be large at all.
5/14/2024
Compression Represents Intelligence Linearly
Yuzhen Huang, Jinghan Zhang, Zifei Shan, Junxian He
0
0
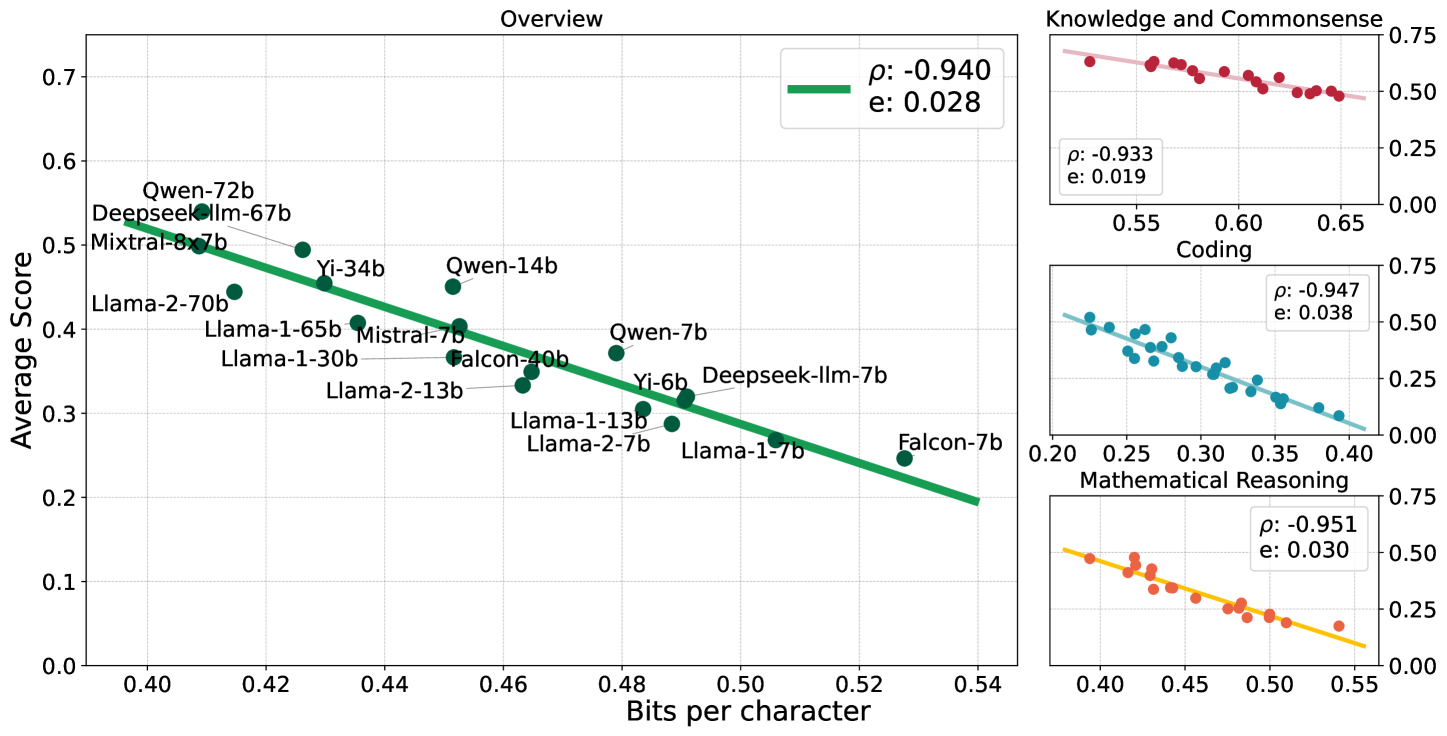
There is a belief that learning to compress well will lead to intelligence. Recently, language modeling has been shown to be equivalent to compression, which offers a compelling rationale for the success of large language models (LLMs): the development of more advanced language models is essentially enhancing compression which facilitates intelligence. Despite such appealing discussions, little empirical evidence is present for the interplay between compression and intelligence. In this work, we examine their relationship in the context of LLMs, treating LLMs as data compressors. Given the abstract concept of intelligence, we adopt the average downstream benchmark scores as a surrogate, specifically targeting intelligence related to knowledge and commonsense, coding, and mathematical reasoning. Across 12 benchmarks, our study brings together 30 public LLMs that originate from diverse organizations. Remarkably, we find that LLMs' intelligence -- reflected by average benchmark scores -- almost linearly correlates with their ability to compress external text corpora. These results provide concrete evidence supporting the belief that superior compression indicates greater intelligence. Furthermore, our findings suggest that compression efficiency, as an unsupervised metric derived from raw text corpora, serves as a reliable evaluation measure that is linearly associated with the model capabilities. We open-source our compression datasets as well as our data collection pipelines to facilitate future researchers to assess compression properly.
4/16/2024
💬
On the Compressibility of Quantized Large Language Models
Yu Mao, Weilan Wang, Hongchao Du, Nan Guan, Chun Jason Xue
0
0
Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.
5/7/2024