Evaluation and Comparison of Visual Language Models for Transportation Engineering Problems

0

Sign in to get full access
Overview
- This paper evaluates and compares the performance of various visual language models on transportation engineering problems.
- The researchers tested different models to see how well they could handle tasks like infrastructure planning, traffic management, and transportation system analysis.
- They found that some models performed better than others depending on the specific problem and data used.
Plain English Explanation
The paper explores how well different AI models that can understand both images and text can be used to solve problems in the field of transportation engineering. Transportation engineers need to tackle a variety of challenges, like figuring out the best places to build new roads or bridges, managing traffic flow, and analyzing the performance of transportation systems.
The researchers tested several visual language models - AI systems that can process both visual and textual information - to see how they would do on these types of transportation-related tasks. They found that some models were better than others at certain problems, depending on factors like the specific dataset used and the level of visual understanding required.
By evaluating these models, the researchers hope to provide guidance on which AI systems might be most useful for transportation engineers trying to leverage advanced technology to solve their challenges.
Technical Explanation
The paper Evaluation and Comparison of Visual Language Models for Transportation Engineering Problems investigates the performance of various vision-language models on a range of transportation engineering tasks. The authors tested models like CLIP, DALL-E, and others on problems such as infrastructure planning, traffic management, and system analysis.
The experiments involved fine-tuning the pre-trained visual language models on transportation-specific datasets and evaluating their performance on relevant benchmarks. The results showed that model performance varied depending on the task, with some excelling at visual reasoning while others were stronger at language understanding.
The authors provide detailed insights into the strengths and weaknesses of each model, as well as recommendations for practitioners on which approaches may be most suitable for different transportation engineering applications. The findings from this research can help guide the selection and application of these advanced AI systems in the transportation domain.
Critical Analysis
The paper provides a thorough and thoughtful evaluation of the capabilities of various visual language models for transportation engineering problems. However, it's important to note that the performance of these models may be heavily dependent on the specific datasets and tasks used in the evaluation. The authors acknowledge this limitation and encourage further validation on a broader range of transportation-related problems.
Additionally, the paper does not delve into the potential biases or limitations of the underlying models themselves. As these AI systems become more widely adopted, it will be crucial to carefully examine their decision-making processes and ensure they are not perpetuating harmful biases or making unsafe decisions, especially in high-stakes domains like transportation.
Future research could also explore ways to make these models more transparent and interpretable, allowing transportation engineers to better understand the reasoning behind the models' outputs and have greater confidence in their decisions.
Conclusion
This paper presents a valuable evaluation of how well different visual language models perform on transportation engineering problems. The findings suggest that these advanced AI systems have significant potential to aid transportation professionals in tackling a range of challenges, from infrastructure planning to traffic management.
However, the research also highlights the need for continued refinement and validation of these models to ensure they are reliable, unbiased, and suitable for real-world transportation applications. As the field of transportation engineering continues to evolve, the integration of cutting-edge AI technologies will undoubtedly play an important role in driving innovation and improving the efficiency and safety of our transportation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluation and Comparison of Visual Language Models for Transportation Engineering Problems
Sanjita Prajapati, Tanu Singh, Chinmay Hegde, Pranamesh Chakraborty
Recent developments in vision language models (VLM) have shown great potential for diverse applications related to image understanding. In this study, we have explored state-of-the-art VLM models for vision-based transportation engineering tasks such as image classification and object detection. The image classification task involves congestion detection and crack identification, whereas, for object detection, helmet violations were identified. We have applied open-source models such as CLIP, BLIP, OWL-ViT, Llava-Next, and closed-source GPT-4o to evaluate the performance of these state-of-the-art VLM models to harness the capabilities of language understanding for vision-based transportation tasks. These tasks were performed by applying zero-shot prompting to the VLM models, as zero-shot prompting involves performing tasks without any training on those tasks. It eliminates the need for annotated datasets or fine-tuning for specific tasks. Though these models gave comparative results with benchmark Convolutional Neural Networks (CNN) models in the image classification tasks, for object localization tasks, it still needs improvement. Therefore, this study provides a comprehensive evaluation of the state-of-the-art VLM models highlighting the advantages and limitations of the models, which can be taken as the baseline for future improvement and wide-scale implementation.
Read more9/5/2024

0
Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
Read more4/16/2024
💬
0
Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, Dorsa Sadigh
Visually-conditioned language models (VLMs) have seen growing adoption in applications such as visual dialogue, scene understanding, and robotic task planning; adoption that has fueled a wealth of new models such as LLaVa, InstructBLIP, and PaLI-3. Despite the volume of new releases, key design decisions around image preprocessing, architecture, and optimization are under-explored, making it challenging to understand what factors account for model performance $-$ a challenge further complicated by the lack of objective, consistent evaluations. To address these gaps, we first compile a suite of standardized evaluations spanning visual question answering, object localization, and challenge sets that probe properties such as hallucination; evaluations that provide fine-grained insight VLM capabilities. Second, we rigorously investigate VLMs along key design axes, including pretrained visual representations and training from base vs. instruct-tuned language models, amongst others. We couple our analysis with three resource contributions: (1) a unified framework for evaluating VLMs, (2) optimized, flexible training code, and (3) checkpoints for all models, including a family of VLMs at the 7-13B scale that strictly outperform InstructBLIP and LLaVa v1.5, the state-of-the-art in open VLMs.
Read more5/31/2024
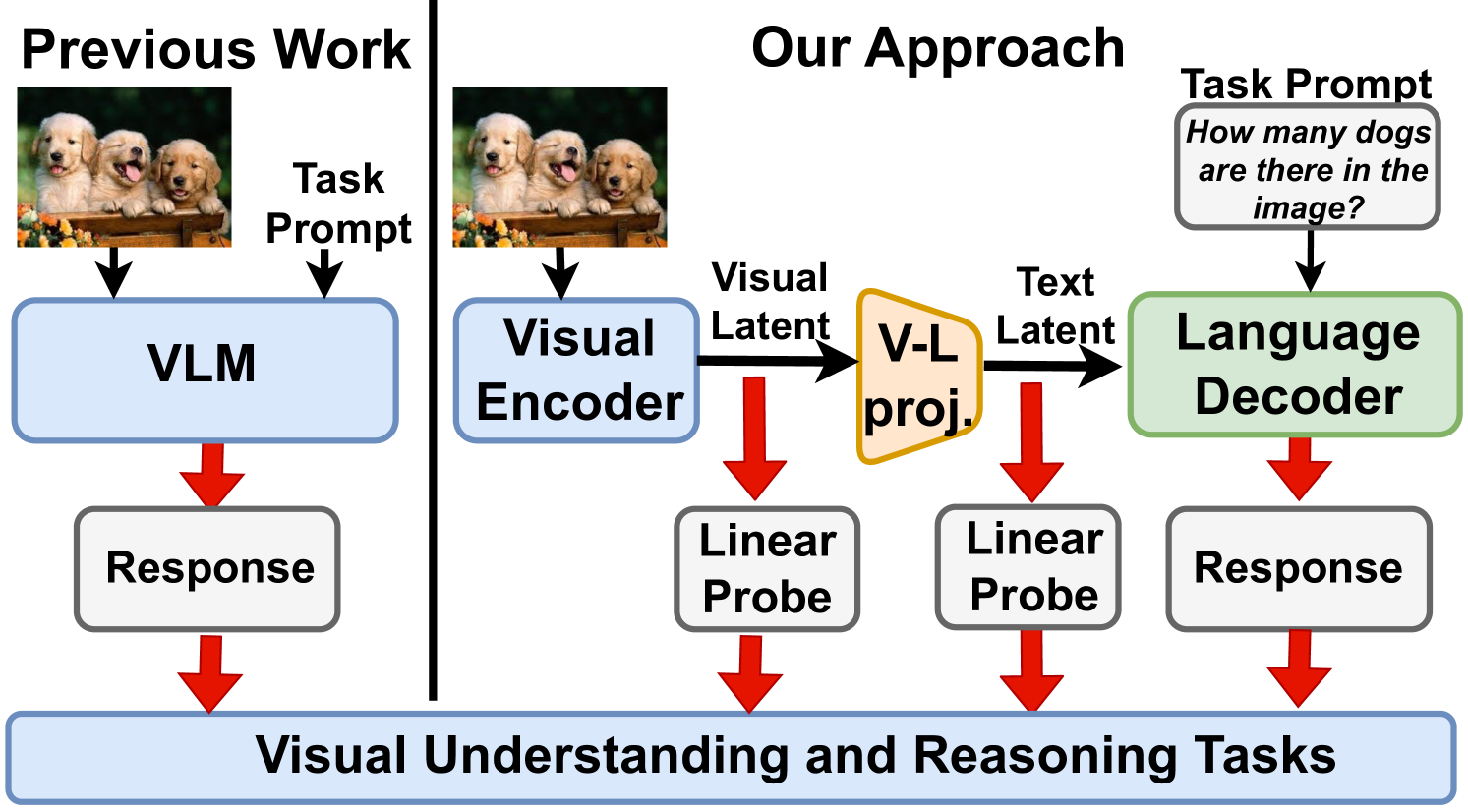
0
Response Wide Shut: Surprising Observations in Basic Vision Language Model Capabilities
Shivam Chandhok, Wan-Cyuan Fan, Leonid Sigal
Vision-Language Models (VLMs) have emerged as general purpose tools for addressing a variety of complex computer vision problems. Such models have been shown to be highly capable, but, at the same time, also lacking some basic visual understanding skills. In this paper, we set out to understand the limitations of SoTA VLMs on fundamental visual tasks: object classification, understanding spatial arrangement, and ability to delineate individual object instances (through counting), by constructing a series of tests that probe which components of design, specifically, maybe lacking. Importantly, we go significantly beyond the current benchmarks, that simply measure final performance of VLM, by also comparing and contrasting it to performance of probes trained directly on features obtained from visual encoder (image embeddings), as well as intermediate vision-language projection used to bridge image-encoder and LLM-decoder ouput in many SoTA models (e.g., LLaVA, BLIP, InstructBLIP). In doing so, we uncover nascent shortcomings in VLMs response and make a number of important observations which could help train and develop more effective VLM models in future.
Read more8/14/2024