Evaluation of Instruction-Following Ability for Large Language Models on Story-Ending Generation
2406.16356
0
0
Abstract
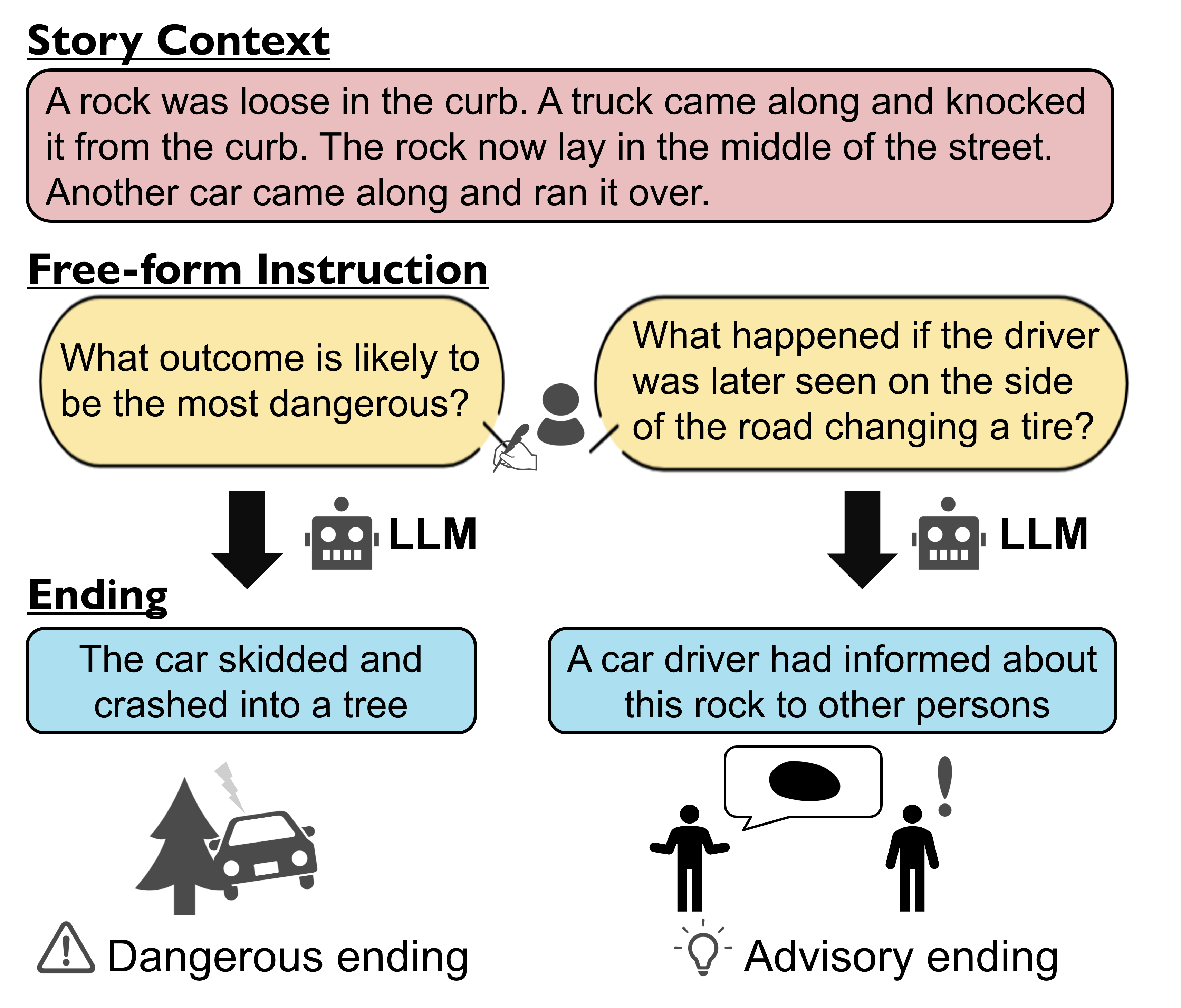
Instruction-tuned Large Language Models (LLMs) have achieved remarkable performance across various benchmark tasks. While providing instructions to LLMs for guiding their generations is user-friendly, assessing their instruction-following capabilities is still unclarified due to a lack of evaluation metrics. In this paper, we focus on evaluating the instruction-following ability of LLMs in the context of story-ending generation, which requires diverse and context-specific instructions. We propose an automatic evaluation pipeline that utilizes a machine reading comprehension (MRC) model to determine whether the generated story-ending reflects instruction. Our findings demonstrate that our proposed metric aligns with human evaluation. Furthermore, our experiments confirm that recent open-source LLMs can achieve instruction-following performance close to GPT-3.5, as assessed through automatic evaluation.
Create account to get full access
Overview
- This paper evaluates the ability of large language models (LLMs) to follow instructions and generate appropriate story endings.
- The researchers tested several popular LLMs, including GPT-3, InstructGPT, and Chinchilla, on a task that required them to generate relevant and coherent story endings based on provided prompts.
- The goal was to assess the models' capacity to understand and follow instructions, a critical skill for real-world applications like question-answering, task completion, and content generation.
Plain English Explanation
The paper explores how well large language models, which are advanced AI systems trained on vast amounts of text data, can understand and follow instructions to complete a specific task. The researchers focused on having these models generate appropriate endings for short stories, based on prompts they were given.
This is an important test because the ability to follow instructions is crucial for many real-world applications of language models, such as answering questions, completing tasks, and generating content. If a language model can't understand and follow the instructions it's given, it won't be very useful in these types of applications.
By testing popular language models like GPT-3, InstructGPT, and Chinchilla on this story-ending task, the researchers were able to assess how well the models could comprehend and respond to the instructions they were provided. This gives us a better understanding of the current capabilities and limitations of these powerful AI systems.
Technical Explanation
The paper presents an evaluation of the instruction-following ability of several large language models (LLMs) on the task of generating appropriate story endings. The researchers tested models including GPT-3, InstructGPT, and Chinchilla on a dataset of short story prompts, where the models were asked to generate relevant and coherent endings.
The experiment design involved providing the models with a story prompt and instructing them to generate an ending that logically follows the events and atmosphere of the story. The researchers then had human evaluators assess the quality and appropriateness of the generated story endings.
The results showed that while the models were generally able to generate relevant story endings, their performance varied widely, with some models demonstrating stronger instruction-following abilities than others. The paper discusses potential factors that may have contributed to these differences, such as the models' training data and architectures.
The insights from this research contribute to our understanding of the current capabilities and limitations of large language models in terms of their ability to comprehend and follow instructions, which is a crucial skill for many real-world applications of these AI systems.
Critical Analysis
The paper provides a valuable evaluation of the instruction-following abilities of several prominent large language models, but it also acknowledges some limitations and areas for further research.
One potential concern is the reliance on human evaluators to assess the quality of the generated story endings. While this approach allows for a more nuanced assessment, it introduces subjective biases and inconsistencies. The researchers could have explored more objective metrics or automated evaluation methods to supplement the human assessment.
Additionally, the paper focuses solely on the story-ending generation task, which may not fully capture the models' instruction-following capabilities in other domains. Expanding the evaluation to include a wider range of instruction-following tasks could provide a more comprehensive understanding of the models' abilities.
The paper also does not delve deeply into the specific architectural differences or training approaches that may have contributed to the observed performance variations between the models. Further research exploring these factors could yield valuable insights for improving the instruction-following abilities of LLMs.
Despite these limitations, the paper makes a valuable contribution to the ongoing efforts to evaluate and optimize the performance of large language models on real-world tasks that require understanding and following instructions.
Conclusion
This paper presents an important evaluation of the instruction-following abilities of several prominent large language models, focusing on their performance in generating appropriate story endings based on provided prompts. The findings suggest that while these models can generally produce relevant and coherent story endings, their instruction-following capabilities vary, highlighting the need for continued research and development in this area.
The insights from this study contribute to our understanding of the current strengths and limitations of large language models, which have become increasingly influential in a wide range of applications, from question-answering to task completion and content generation. Improving the instruction-following abilities of these models is crucial for their effective deployment in real-world scenarios that require clear understanding and execution of instructions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Large Language Models at Evaluating Instruction Following
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, Danqi Chen
0
0
As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasing list of models. This paper investigates the efficacy of these ``LLM evaluators'', particularly in using them to assess instruction following, a metric that gauges how closely generated text adheres to the given instruction. We introduce a challenging meta-evaluation benchmark, LLMBar, designed to test the ability of an LLM evaluator in discerning instruction-following outputs. The authors manually curated 419 pairs of outputs, one adhering to instructions while the other diverging, yet may possess deceptive qualities that mislead an LLM evaluator, e.g., a more engaging tone. Contrary to existing meta-evaluation, we discover that different evaluators (i.e., combinations of LLMs and prompts) exhibit distinct performance on LLMBar and even the highest-scoring ones have substantial room for improvement. We also present a novel suite of prompting strategies that further close the gap between LLM and human evaluators. With LLMBar, we hope to offer more insight into LLM evaluators and foster future research in developing better instruction-following models.
4/17/2024

FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini
0
0
Modern Language Models (LMs) are capable of following long and complex instructions that enable a large and diverse set of user requests. While Information Retrieval (IR) models use these LMs as the backbone of their architectures, virtually none of them allow users to provide detailed instructions alongside queries, thus limiting their ability to satisfy complex information needs. In this work, we study the use of instructions in IR systems. First, we introduce our dataset FollowIR, which contains a rigorous instruction evaluation benchmark as well as a training set for helping IR models learn to better follow real-world instructions. FollowIR repurposes detailed instructions -- also known as narratives -- developed for professional assessors to evaluate retrieval systems. In particular, we build our benchmark from three collections curated for shared tasks at the Text REtrieval Conference (TREC). These collections contains hundreds to thousands of labeled documents per query, making them suitable for our exploration. Through this process, we can measure how well IR models follow instructions, through a new pairwise evaluation framework. Our results indicate that existing retrieval models fail to correctly use instructions, using them for basic keywords and struggling to understand long-form information. However, we show that it is possible for IR models to learn to follow complex instructions: our new FollowIR-7B model has significant improvements after fine-tuning on our training set.
5/8/2024

Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models
Guanting Dong, Keming Lu, Chengpeng Li, Tingyu Xia, Bowen Yu, Chang Zhou, Jingren Zhou
0
0
One core capability of large language models (LLMs) is to follow natural language instructions. However, the issue of automatically constructing high-quality training data to enhance the complex instruction-following abilities of LLMs without manual annotation remains unresolved. In this paper, we introduce AutoIF, the first scalable and reliable method for automatically generating instruction-following training data. AutoIF transforms the validation of instruction-following data quality into code verification, requiring LLMs to generate instructions, the corresponding code to check the correctness of the instruction responses, and unit test samples to verify the code's correctness. Then, execution feedback-based rejection sampling can generate data for Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) training. AutoIF achieves significant improvements across three training algorithms, SFT, Offline DPO, and Online DPO, when applied to the top open-source LLMs, Qwen2 and LLaMA3, in self-alignment and strong-to-weak distillation settings. Our code is publicly available at https://github.com/QwenLM/AutoIF.
6/21/2024
Evaluating and Optimizing Educational Content with Large Language Model Judgments
Joy He-Yueya, Noah D. Goodman, Emma Brunskill
0
0
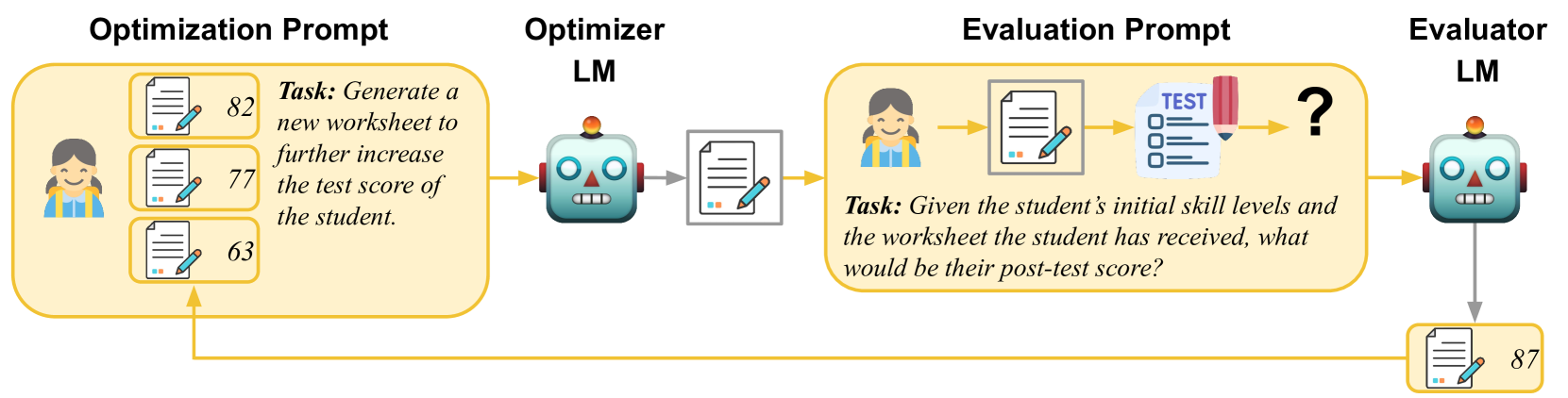
Creating effective educational materials generally requires expensive and time-consuming studies of student learning outcomes. To overcome this barrier, one idea is to build computational models of student learning and use them to optimize instructional materials. However, it is difficult to model the cognitive processes of learning dynamics. We propose an alternative approach that uses Language Models (LMs) as educational experts to assess the impact of various instructions on learning outcomes. Specifically, we use GPT-3.5 to evaluate the overall effect of instructional materials on different student groups and find that it can replicate well-established educational findings such as the Expertise Reversal Effect and the Variability Effect. This demonstrates the potential of LMs as reliable evaluators of educational content. Building on this insight, we introduce an instruction optimization approach in which one LM generates instructional materials using the judgments of another LM as a reward function. We apply this approach to create math word problem worksheets aimed at maximizing student learning gains. Human teachers' evaluations of these LM-generated worksheets show a significant alignment between the LM judgments and human teacher preferences. We conclude by discussing potential divergences between human and LM opinions and the resulting pitfalls of automating instructional design.
5/7/2024