Instruction-following Evaluation through Verbalizer Manipulation
2307.10558
0
0
🌀
Abstract
While instruction-tuned models have shown remarkable success in various natural language processing tasks, accurately evaluating their ability to follow instructions remains challenging. Existing benchmarks primarily focus on common instructions that align well with what the model learned during training. However, proficiency in responding to these instructions does not necessarily imply strong ability in instruction following. In this paper, we propose a novel instruction-following evaluation protocol called verbalizer manipulation. It instructs the model to verbalize the task label with words aligning with model priors to different extents, adopting verbalizers from highly aligned (e.g., outputting postive'' for positive sentiment), to minimally aligned (e.g., outputting negative'' for positive sentiment). Verbalizer manipulation can be seamlessly integrated with any classification benchmark to examine the model's reliance on priors and its ability to override them to accurately follow the instructions. We conduct a comprehensive evaluation of four major model families across nine datasets, employing twelve sets of verbalizers for each of them. We observe that the instruction-following abilities of models, across different families and scales, are significantly distinguished by their performance on less natural verbalizers. Even the strongest GPT-4 model struggles to perform better than random guessing on the most challenging verbalizer, emphasizing the need for continued advancements to improve their instruction-following abilities.
Create account to get full access
Overview
- Existing benchmarks for evaluating instruction-following abilities of language models primarily focus on common instructions that align well with what the model learned during training.
- This may not accurately reflect the model's true ability to follow instructions, as proficiency in responding to these instructions does not necessarily imply strong ability in instruction following.
- The paper proposes a novel instruction-following evaluation protocol called "verbalizer manipulation" to better assess a model's reliance on priors and its ability to override them.
Plain English Explanation
Language models, like GPT-4, have become remarkably skilled at understanding and responding to various types of natural language tasks. However, accurately evaluating their ability to follow instructions remains challenging. Existing benchmarks often use instructions that are well-aligned with what the model has already learned during training, meaning the model can perform these tasks well without necessarily having a strong ability to follow instructions in general.
The researchers in this paper wanted to better understand how well these models can truly follow instructions, even when the instructions may not align with their established biases or "priors." To do this, they developed a new evaluation method called "verbalizer manipulation." This involves instructing the model to use specific words or "verbalizers" to describe the task, even if those words don't naturally match the task.
For example, the model might be asked to classify a piece of text as "positive" sentiment, but instead of using the word "positive," it would be instructed to use the word "negative." This challenges the model to override its learned associations and accurately follow the given instruction, rather than relying on its existing biases.
By applying this verbalizer manipulation approach across various datasets and model families, the researchers were able to gain deeper insights into the instruction-following abilities of state-of-the-art language models. Their findings suggest that even the most powerful models, like GPT-4, can struggle to perform well when the instructions significantly diverge from their learned priors, highlighting the need for continued advancements in this area.
Technical Explanation
The researchers conducted a comprehensive evaluation of four major model families (GPT, BERT, T5, and PaLM) across nine different datasets, using twelve sets of verbalizers for each. The verbalizers ranged from highly aligned with the model's priors (e.g., using "positive" for positive sentiment) to minimally aligned (e.g., using "negative" for positive sentiment).
By integrating the verbalizer manipulation protocol with existing classification benchmarks, the researchers were able to examine the models' reliance on priors and their ability to override them to accurately follow the instructions. They found that the instruction-following abilities of the models, across different families and scales, were significantly distinguished by their performance on the less natural verbalizers.
Even the powerful GPT-4 model struggled to perform better than random guessing on the most challenging verbalizers, suggesting that current state-of-the-art language models still have significant room for improvement when it comes to following instructions that diverge from their learned associations.
Critical Analysis
The paper highlights an important limitation of existing benchmarks for evaluating instruction-following abilities, which primarily focus on instructions that are well-aligned with the model's training data. This raises concerns about whether these benchmarks are truly capturing the full extent of a model's instruction-following capabilities.
While the verbalizer manipulation approach introduced in the paper is a valuable addition to the evaluation toolkit, it is worth considering its own potential limitations. The authors acknowledge that the effectiveness of this approach may depend on the specific task and dataset, and that further research is needed to understand its broader applicability.
Additionally, the paper does not delve into the potential reasons why even the strongest models struggle with the more challenging verbalizers. Further investigation into the underlying mechanisms and biases that contribute to these limitations could provide valuable insights for developing more robust and versatile instruction-following abilities in language models.
Conclusion
This research highlights the need for more nuanced and comprehensive approaches to evaluating the instruction-following capabilities of language models. The verbalizer manipulation protocol introduced in the paper offers a promising way to uncover the limitations of current state-of-the-art models, which may not be fully captured by traditional benchmarks.
As language models continue to advance, the ability to accurately follow instructions that diverge from their learned priors will become increasingly important, particularly for applications where precise and reliable instruction-following is critical. The insights gained from this research can help drive further advancements in this area, ultimately leading to more robust and versatile language models that can better serve the diverse needs of users and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Large Language Models at Evaluating Instruction Following
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, Danqi Chen
0
0
As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasing list of models. This paper investigates the efficacy of these ``LLM evaluators'', particularly in using them to assess instruction following, a metric that gauges how closely generated text adheres to the given instruction. We introduce a challenging meta-evaluation benchmark, LLMBar, designed to test the ability of an LLM evaluator in discerning instruction-following outputs. The authors manually curated 419 pairs of outputs, one adhering to instructions while the other diverging, yet may possess deceptive qualities that mislead an LLM evaluator, e.g., a more engaging tone. Contrary to existing meta-evaluation, we discover that different evaluators (i.e., combinations of LLMs and prompts) exhibit distinct performance on LLMBar and even the highest-scoring ones have substantial room for improvement. We also present a novel suite of prompting strategies that further close the gap between LLM and human evaluators. With LLMBar, we hope to offer more insight into LLM evaluators and foster future research in developing better instruction-following models.
4/17/2024
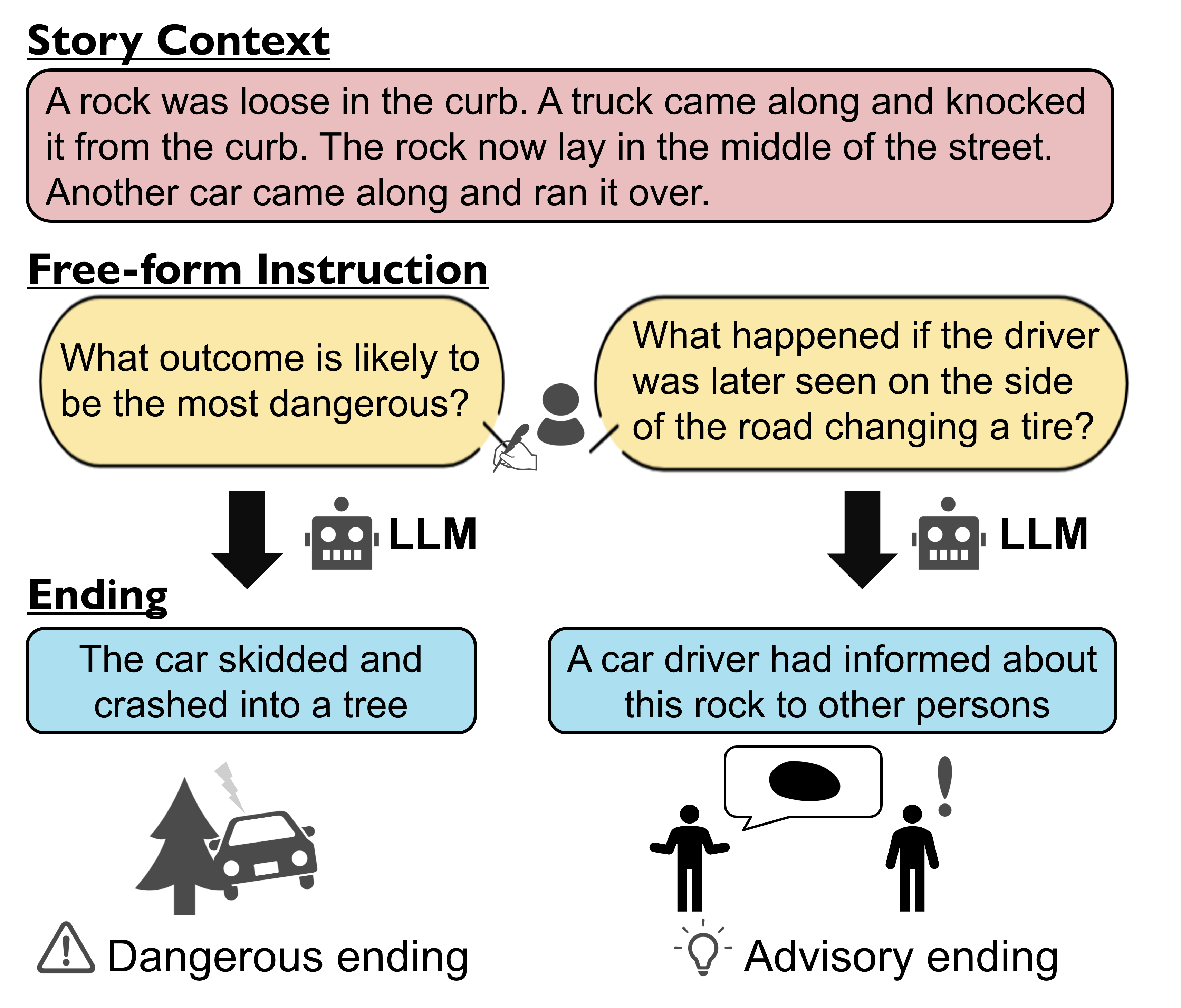
Evaluation of Instruction-Following Ability for Large Language Models on Story-Ending Generation
Rem Hida, Junki Ohmura, Toshiyuki Sekiya
0
0
Instruction-tuned Large Language Models (LLMs) have achieved remarkable performance across various benchmark tasks. While providing instructions to LLMs for guiding their generations is user-friendly, assessing their instruction-following capabilities is still unclarified due to a lack of evaluation metrics. In this paper, we focus on evaluating the instruction-following ability of LLMs in the context of story-ending generation, which requires diverse and context-specific instructions. We propose an automatic evaluation pipeline that utilizes a machine reading comprehension (MRC) model to determine whether the generated story-ending reflects instruction. Our findings demonstrate that our proposed metric aligns with human evaluation. Furthermore, our experiments confirm that recent open-source LLMs can achieve instruction-following performance close to GPT-3.5, as assessed through automatic evaluation.
6/26/2024

FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini
0
0
Modern Language Models (LMs) are capable of following long and complex instructions that enable a large and diverse set of user requests. While Information Retrieval (IR) models use these LMs as the backbone of their architectures, virtually none of them allow users to provide detailed instructions alongside queries, thus limiting their ability to satisfy complex information needs. In this work, we study the use of instructions in IR systems. First, we introduce our dataset FollowIR, which contains a rigorous instruction evaluation benchmark as well as a training set for helping IR models learn to better follow real-world instructions. FollowIR repurposes detailed instructions -- also known as narratives -- developed for professional assessors to evaluate retrieval systems. In particular, we build our benchmark from three collections curated for shared tasks at the Text REtrieval Conference (TREC). These collections contains hundreds to thousands of labeled documents per query, making them suitable for our exploration. Through this process, we can measure how well IR models follow instructions, through a new pairwise evaluation framework. Our results indicate that existing retrieval models fail to correctly use instructions, using them for basic keywords and struggling to understand long-form information. However, we show that it is possible for IR models to learn to follow complex instructions: our new FollowIR-7B model has significant improvements after fine-tuning on our training set.
5/8/2024
✅
Instruction Makes a Difference
Tosin Adewumi, Nudrat Habib, Lama Alkhaled, Elisa Barney
0
0
We introduce Instruction Document Visual Question Answering (iDocVQA) dataset and Large Language Document (LLaDoc) model, for training Language-Vision (LV) models for document analysis and predictions on document images, respectively. Usually, deep neural networks for the DocVQA task are trained on datasets lacking instructions. We show that using instruction-following datasets improves performance. We compare performance across document-related datasets using the recent state-of-the-art (SotA) Large Language and Vision Assistant (LLaVA)1.5 as the base model. We also evaluate the performance of the derived models for object hallucination using the Polling-based Object Probing Evaluation (POPE) dataset. The results show that instruction-tuning performance ranges from 11X to 32X of zero-shot performance and from 0.1% to 4.2% over non-instruction (traditional task) finetuning. Despite the gains, these still fall short of human performance (94.36%), implying there's much room for improvement.
6/14/2024