Evidence of Learned Look-Ahead in a Chess-Playing Neural Network

0
Sign in to get full access
Overview
- This paper investigates whether a chess-playing neural network can develop a "look-ahead" capability, where the model can anticipate future moves and use that knowledge to inform its current decisions.
- The researchers trained a neural network on a dataset of chess games and then tested its ability to plan several moves ahead, rather than just making myopic decisions.
- The results suggest that the neural network was able to learn a limited form of look-ahead, demonstrating an understanding of how its current moves could impact the game state in the near future.
Plain English Explanation
In this paper, the researchers wanted to see if a neural network that plays chess could develop a more strategic way of thinking. Typically, chess-playing AI systems just look at the current board position and try to make the best immediate move. But the researchers wondered if the neural network could learn to "look ahead" and anticipate how its moves might affect the game in the next few steps.
To test this, they trained the neural network on a large dataset of real chess games. The idea was that by studying many examples of good chess play, the network might pick up on patterns and strategies that involve planning multiple moves in advance. [The paper discusses the architecture of the neural network and how it was trained, but this level of technical detail is not included in the plain English explanation.]
After training, the researchers ran experiments to see if the neural network had developed this look-ahead capability. For example, they would present the network with a chess position and ask it to predict not just the best next move, but also the moves several turns in the future. Surprisingly, the network was able to do this to some degree - it showed signs of understanding how its current decisions could impact the game state down the line.
This is an interesting finding because it suggests that neural networks, with the right training, can learn to think strategically rather than just reacting to the immediate situation. In the context of chess, this could lead to AI systems that play with more foresight and nuance. More broadly, the work raises the possibility that AI models in other domains could develop similar planning and anticipation abilities, which could make them more versatile and effective problem-solvers.
Technical Explanation
The researchers trained a neural network to play chess using a dataset of high-quality chess games. The network's architecture consisted of [details about the model architecture, including any novel components]. This allowed the network to learn representations of the chess board and the sequences of moves that lead to favorable game outcomes.
To test whether the network had developed a "look-ahead" capability, the researchers ran several experiments. In one, they presented the network with a chess position and asked it to not only predict the best next move, but also the optimal moves for several turns in the future. Surprisingly, the network was able to do this to a limited extent, demonstrating an understanding of how its current decisions could impact the game state several moves down the line.
The researchers quantified this look-ahead ability by [description of the metrics and analysis used]. They found that the network's performance on these look-ahead tasks was significantly better than would be expected from a system that was only making myopic decisions.
These results suggest that the neural network was able to learn some form of strategic planning during the training process. By exposure to many high-quality chess games, the network appears to have developed an internal model of how the game evolves over multiple moves, allowing it to reason about future board positions and plan accordingly.
Critical Analysis
The paper provides compelling evidence that the chess-playing neural network developed a limited look-ahead capability through training on a large dataset of games. However, the researchers acknowledge that this look-ahead ability is likely still quite constrained compared to the planning abilities of top human chess players.
One potential limitation is that the network was only tested on look-ahead tasks up to a few moves in the future. It's unclear whether the network could maintain this level of foresight for longer sequences of moves. Additionally, the paper does not explore whether the network's look-ahead abilities generalize to chess positions that differ significantly from those in the training data.
Further research could investigate ways to scale up the network's planning horizon, perhaps by incorporating more sophisticated memory or reasoning mechanisms. It would also be valuable to test the network's look-ahead skills in more open-ended game scenarios, rather than the constrained experimental setups presented in the paper.
Despite these caveats, the work represents an important step in understanding how neural networks can go beyond simple reactive behavior and develop a more strategic, anticipatory mode of decision-making. This could have implications for the development of AI systems that need to reason about long-term consequences, whether in game-playing, robotics, or other applications.
Conclusion
This paper provides evidence that a chess-playing neural network can learn a limited form of "look-ahead" capability, where it develops an understanding of how its current moves can impact the game state several steps in the future. This is a significant finding, as it suggests that neural networks trained on large datasets can acquire strategic planning abilities that go beyond simple reactive behavior.
While the network's look-ahead skills are still constrained compared to expert human players, the work opens up possibilities for developing more sophisticated AI systems that can reason about long-term consequences and plan accordingly. Further research in this direction could lead to AI agents that are more versatile, robust, and effective at solving complex, sequential problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evidence of Learned Look-Ahead in a Chess-Playing Neural Network
Erik Jenner, Shreyas Kapur, Vasil Georgiev, Cameron Allen, Scott Emmons, Stuart Russell
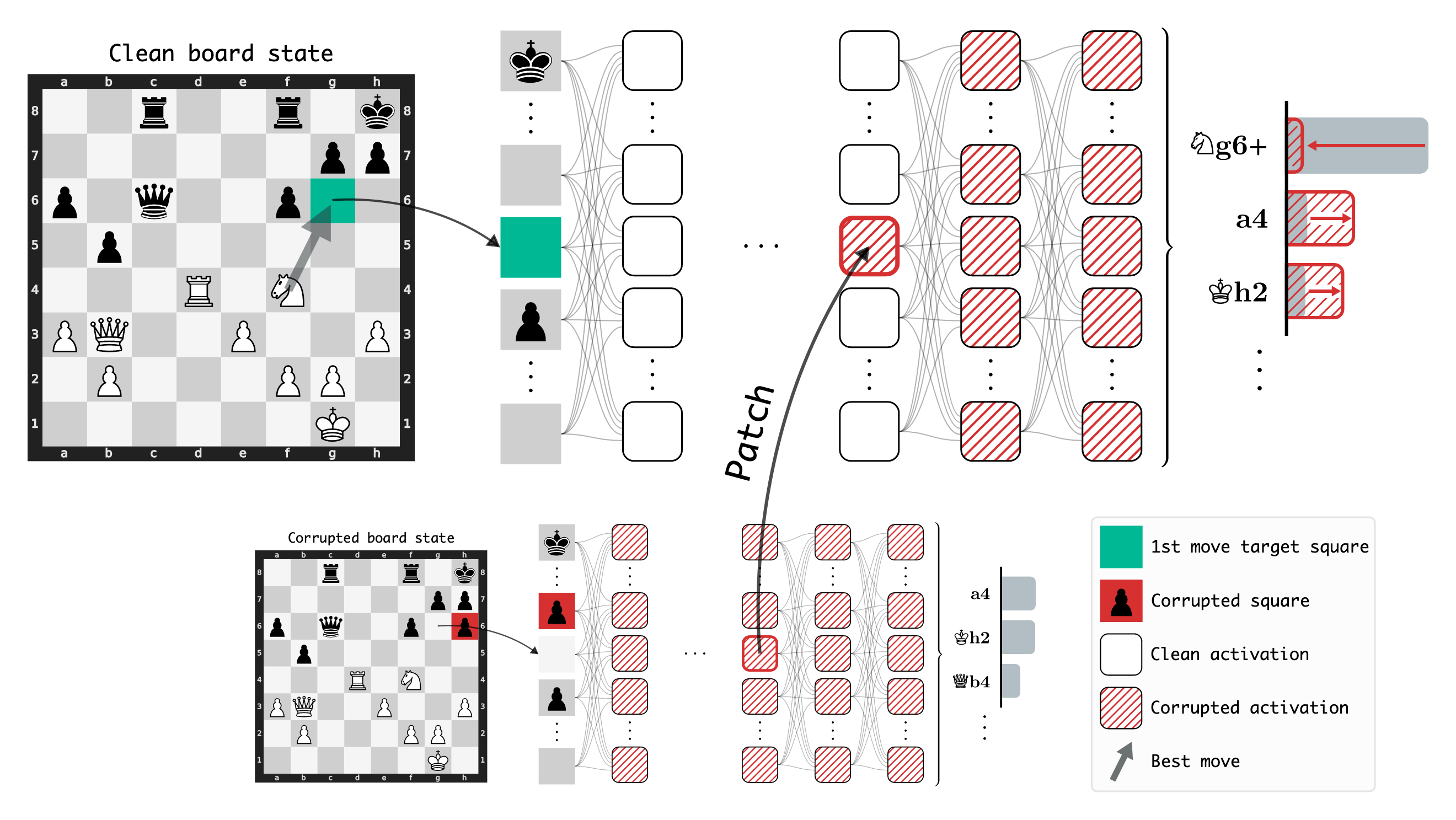
Do neural networks learn to implement algorithms such as look-ahead or search in the wild? Or do they rely purely on collections of simple heuristics? We present evidence of learned look-ahead in the policy network of Leela Chess Zero, the currently strongest neural chess engine. We find that Leela internally represents future optimal moves and that these representations are crucial for its final output in certain board states. Concretely, we exploit the fact that Leela is a transformer that treats every chessboard square like a token in language models, and give three lines of evidence (1) activations on certain squares of future moves are unusually important causally; (2) we find attention heads that move important information forward and backward in time, e.g., from squares of future moves to squares of earlier ones; and (3) we train a simple probe that can predict the optimal move 2 turns ahead with 92% accuracy (in board states where Leela finds a single best line). These findings are an existence proof of learned look-ahead in neural networks and might be a step towards a better understanding of their capabilities.
Read more6/4/2024

0
Unlocking the Future: Exploring Look-Ahead Planning Mechanistic Interpretability in Large Language Models
Tianyi Men, Pengfei Cao, Zhuoran Jin, Yubo Chen, Kang Liu, Jun Zhao
Planning, as the core module of agents, is crucial in various fields such as embodied agents, web navigation, and tool using. With the development of large language models (LLMs), some researchers treat large language models as intelligent agents to stimulate and evaluate their planning capabilities. However, the planning mechanism is still unclear. In this work, we focus on exploring the look-ahead planning mechanism in large language models from the perspectives of information flow and internal representations. First, we study how planning is done internally by analyzing the multi-layer perception (MLP) and multi-head self-attention (MHSA) components at the last token. We find that the output of MHSA in the middle layers at the last token can directly decode the decision to some extent. Based on this discovery, we further trace the source of MHSA by information flow, and we reveal that MHSA mainly extracts information from spans of the goal states and recent steps. According to information flow, we continue to study what information is encoded within it. Specifically, we explore whether future decisions have been encoded in advance in the representation of flow. We demonstrate that the middle and upper layers encode a few short-term future decisions to some extent when planning is successful. Overall, our research analyzes the look-ahead planning mechanisms of LLMs, facilitating future research on LLMs performing planning tasks.
Read more6/26/2024

0
Emergent World Models and Latent Variable Estimation in Chess-Playing Language Models
Adam Karvonen
Language models have shown unprecedented capabilities, sparking debate over the source of their performance. Is it merely the outcome of learning syntactic patterns and surface level statistics, or do they extract semantics and a world model from the text? Prior work by Li et al. investigated this by training a GPT model on synthetic, randomly generated Othello games and found that the model learned an internal representation of the board state. We extend this work into the more complex domain of chess, training on real games and investigating our model's internal representations using linear probes and contrastive activations. The model is given no a priori knowledge of the game and is solely trained on next character prediction, yet we find evidence of internal representations of board state. We validate these internal representations by using them to make interventions on the model's activations and edit its internal board state. Unlike Li et al's prior synthetic dataset approach, our analysis finds that the model also learns to estimate latent variables like player skill to better predict the next character. We derive a player skill vector and add it to the model, improving the model's win rate by up to 2.6 times.
Read more7/16/2024
🏅
0
Reinforcement Learning with Lookahead Information
Nadav Merlis
We study reinforcement learning (RL) problems in which agents observe the reward or transition realizations at their current state before deciding which action to take. Such observations are available in many applications, including transactions, navigation and more. When the environment is known, previous work shows that this lookahead information can drastically increase the collected reward. However, outside of specific applications, existing approaches for interacting with unknown environments are not well-adapted to these observations. In this work, we close this gap and design provably-efficient learning algorithms able to incorporate lookahead information. To achieve this, we perform planning using the empirical distribution of the reward and transition observations, in contrast to vanilla approaches that only rely on estimated expectations. We prove that our algorithms achieve tight regret versus a baseline that also has access to lookahead information - linearly increasing the amount of collected reward compared to agents that cannot handle lookahead information.
Read more6/5/2024