Reinforcement Learning with Lookahead Information
2406.02258
0
0
🏅
Abstract
We study reinforcement learning (RL) problems in which agents observe the reward or transition realizations at their current state before deciding which action to take. Such observations are available in many applications, including transactions, navigation and more. When the environment is known, previous work shows that this lookahead information can drastically increase the collected reward. However, outside of specific applications, existing approaches for interacting with unknown environments are not well-adapted to these observations. In this work, we close this gap and design provably-efficient learning algorithms able to incorporate lookahead information. To achieve this, we perform planning using the empirical distribution of the reward and transition observations, in contrast to vanilla approaches that only rely on estimated expectations. We prove that our algorithms achieve tight regret versus a baseline that also has access to lookahead information - linearly increasing the amount of collected reward compared to agents that cannot handle lookahead information.
Create account to get full access
Overview
- This paper explores reinforcement learning (RL) problems where agents can observe the reward or transition realizations at their current state before deciding on an action.
- This type of "lookahead" information is available in many real-world applications, such as transactions, navigation, and more.
- Previous work has shown that when the environment is known, this lookahead information can significantly increase the collected reward.
- However, existing approaches for interacting with unknown environments are not well-suited to handle this type of information.
- This paper aims to close this gap by designing provably-efficient learning algorithms that can incorporate lookahead information.
Plain English Explanation
In this paper, the researchers explore a type of reinforcement learning problem where the agent (the decision-making system) can observe some additional information before deciding on its next action. This additional information could be, for example, the reward the agent would receive or how the environment would change if the agent took a certain action.
The researchers explain that this kind of "lookahead" information is available in many real-world situations, such as when making financial transactions or navigating through an environment. Previous research has shown that if the agent already knows how the environment works, this lookahead information can greatly improve the agent's performance and the overall rewards it collects.
However, the researchers note that existing approaches for agents learning in unknown environments do not handle this lookahead information very well. To address this, the researchers have developed new learning algorithms that can effectively use the lookahead information, even when the environment is not fully known.
By incorporating the empirical distribution of the observed reward and transition information, rather than just relying on estimated averages, these new algorithms can achieve strong performance guarantees. Specifically, the researchers show that their algorithms can collect significantly more reward over time compared to agents that cannot use the lookahead information.
Technical Explanation
The core of this paper is the design and analysis of new reinforcement learning algorithms that can effectively utilize lookahead information about rewards and state transitions. This lookahead information is available in many real-world RL problems, such as transactions, navigation, and others.
Previous work has shown that when the environment model is known, having access to this lookahead information can drastically increase the collected reward. However, outside of specific applications, existing RL approaches are not well-adapted to leverage this additional information in unknown environments.
To address this gap, the researchers propose new algorithms that perform planning using the empirical distribution of the observed reward and transition information, rather than just relying on estimated expectations as in standard RL. This allows the agent to better capture the underlying dynamics and make more informed decisions.
The researchers provide a regret analysis, showing that their algorithms achieve tight bounds compared to a baseline that also has access to the lookahead information. This means the new algorithms are able to linearly increase the amount of reward collected over time, compared to agents that cannot handle the lookahead data.
The key technical contributions include:
- Designing RL algorithms that can effectively utilize lookahead information about rewards and state transitions
- Analyzing the regret of these algorithms compared to a strong baseline that also has access to the lookahead data
- Proving that the new algorithms can significantly outperform standard RL approaches that do not leverage the additional information
Critical Analysis
The paper presents a thoughtful approach to incorporating lookahead information into reinforcement learning algorithms for unknown environments. The theoretical guarantees and performance improvements demonstrated are compelling.
However, one potential limitation is the reliance on certain assumptions, such as the reward and transition observations being independent and identically distributed. Real-world environments may exhibit more complex dependencies and non-stationarities that are not fully captured by the proposed framework.
Additionally, the paper focuses on regret bounds as the primary performance metric. While this is a common approach in theoretical RL research, it may not always align perfectly with practical objectives. Exploring other evaluation metrics, such as sample efficiency or safety constraints, could provide additional insights.
Further research could also investigate the robustness of these algorithms to model misspecification, outliers in the observed data, or other practical challenges that may arise in diverse application domains. Bridging the gap between the theoretical guarantees and real-world performance remains an important area for continued study.
Overall, this work represents a valuable contribution to the understanding of how lookahead information can be effectively leveraged in reinforcement learning, with potential implications for numerous applications. The authors have laid a strong foundation for further exploration in this direction.
Conclusion
This paper addresses an important gap in reinforcement learning research by designing new algorithms that can effectively utilize lookahead information about rewards and state transitions, even in unknown environments.
The key innovation is the use of the empirical distribution of the observed data, rather than just relying on estimated expectations, to perform more informed planning and decision-making. This allows the agents to significantly outperform standard RL approaches in terms of the overall reward collected over time.
The theoretical guarantees and performance improvements demonstrated in this work have the potential to impact a wide range of real-world applications where lookahead information is available, such as financial transactions, navigation, and beyond. Further research to address practical challenges and broaden the applicability of these techniques could lead to exciting advancements in the field of reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Beyond Optimism: Exploration With Partially Observable Rewards
Simone Parisi, Alireza Kazemipour, Michael Bowling
0
0
Exploration in reinforcement learning (RL) remains an open challenge. RL algorithms rely on observing rewards to train the agent, and if informative rewards are sparse the agent learns slowly or may not learn at all. To improve exploration and reward discovery, popular algorithms rely on optimism. But what if sometimes rewards are unobservable, e.g., situations of partial monitoring in bandits and the recent formalism of monitored Markov decision process? In this case, optimism can lead to suboptimal behavior that does not explore further to collapse uncertainty. With this paper, we present a novel exploration strategy that overcomes the limitations of existing methods and guarantees convergence to an optimal policy even when rewards are not always observable. We further propose a collection of tabular environments for benchmarking exploration in RL (with and without unobservable rewards) and show that our method outperforms existing ones.
6/21/2024
🏅
Informed Reinforcement Learning for Situation-Aware Traffic Rule Exceptions
Daniel Bogdoll, Jing Qin, Moritz Nekolla, Ahmed Abouelazm, Tim Joseph, J. Marius Zollner
0
0
Reinforcement Learning is a highly active research field with promising advancements. In the field of autonomous driving, however, often very simple scenarios are being examined. Common approaches use non-interpretable control commands as the action space and unstructured reward designs which lack structure. In this work, we introduce Informed Reinforcement Learning, where a structured rulebook is integrated as a knowledge source. We learn trajectories and asses them with a situation-aware reward design, leading to a dynamic reward which allows the agent to learn situations which require controlled traffic rule exceptions. Our method is applicable to arbitrary RL models. We successfully demonstrate high completion rates of complex scenarios with recent model-based agents.
6/13/2024
An approach to improve agent learning via guaranteeing goal reaching in all episodes
Pavel Osinenko, Grigory Yaremenko, Georgiy Malaniya, Anton Bolychev
0
0
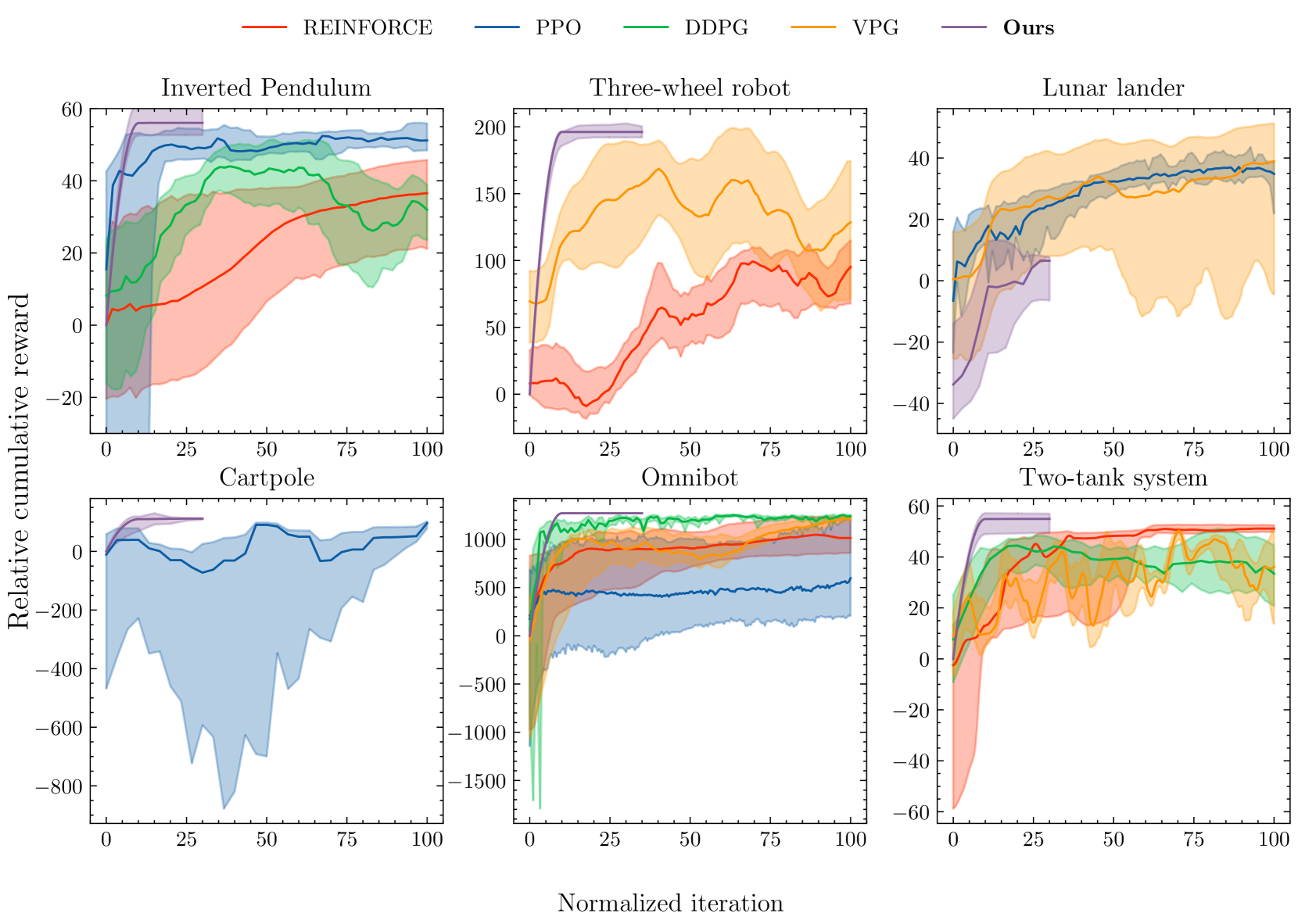
Reinforcement learning is commonly concerned with problems of maximizing accumulated rewards in Markov decision processes. Oftentimes, a certain goal state or a subset of the state space attain maximal reward. In such a case, the environment may be considered solved when the goal is reached. Whereas numerous techniques, learning or non-learning based, exist for solving environments, doing so optimally is the biggest challenge. Say, one may choose a reward rate which penalizes the action effort. Reinforcement learning is currently among the most actively developed frameworks for solving environments optimally by virtue of maximizing accumulated reward, in other words, returns. Yet, tuning agents is a notoriously hard task as reported in a series of works. Our aim here is to help the agent learn a near-optimal policy efficiently while ensuring a goal reaching property of some basis policy that merely solves the environment. We suggest an algorithm, which is fairly flexible, and can be used to augment practically any agent as long as it comprises of a critic. A formal proof of a goal reaching property is provided. Simulation experiments on six problems under five agents, including the benchmarked one, provided an empirical evidence that the learning can indeed be boosted while ensuring goal reaching property.
5/30/2024

Provable Interactive Learning with Hindsight Instruction Feedback
Dipendra Misra, Aldo Pacchiano, Robert E. Schapire
0
0
We study interactive learning in a setting where the agent has to generate a response (e.g., an action or trajectory) given a context and an instruction. In contrast, to typical approaches that train the system using reward or expert supervision on response, we study learning with hindsight instruction where a teacher provides an instruction that is most suitable for the agent's generated response. This hindsight labeling of instruction is often easier to provide than providing expert supervision of the optimal response which may require expert knowledge or can be impractical to elicit. We initiate the theoretical analysis of interactive learning with hindsight labeling. We first provide a lower bound showing that in general, the regret of any algorithm must scale with the size of the agent's response space. We then study a specialized setting where the underlying instruction-response distribution can be decomposed as a low-rank matrix. We introduce an algorithm called LORIL for this setting and show that its regret scales as $sqrt{T}$ where $T$ is the number of rounds and depends on the intrinsic rank but does not depend on the size of the agent's response space. We provide experiments in two domains showing that LORIL outperforms baselines even when the low-rank assumption is violated.
4/16/2024