Explainable Metric Learning for Deflating Data Bias

0

Sign in to get full access
Overview
- The paper explores a method for "explainable metric learning" to address data biases in machine learning models.
- It proposes a novel technique that aims to make machine learning models more transparent and interpretable.
- The approach involves learning a distance metric that can deflate the influence of biases in the training data, while preserving the underlying semantic relationships.
Plain English Explanation
Machine learning models are often trained on datasets that contain biases, such as overrepresentation of certain demographic groups or biases in how the data was collected. These biases can then get "baked into" the models, leading to unfair or unreliable predictions.
The researchers in this paper have developed a new technique to address this problem. Their method focuses on learning a special "distance metric" that can recognize and reduce the impact of biases in the training data. This distance metric essentially changes how the model measures the similarity or differences between data points, in a way that filters out the biases.
The key idea is to make the model more "explainable" - that is, to provide insights into how it is making its decisions. By understanding the biases the model is learning, researchers and users can then take steps to mitigate them. This aligns with a broader trend in explainable AI towards building more transparent and accountable machine learning systems.
Overall, this research represents an important step forward in the quest to develop fair and reliable AI models that can be trusted to make consequential decisions.
Technical Explanation
The paper proposes an "explainable metric learning" approach to address dataset biases in machine learning. The key idea is to learn a distance metric that can "deflate" the influence of biases, while preserving the underlying semantic relationships in the data.
Specifically, the method involves training a neural network to learn a specialized distance function, rather than relying on standard Euclidean distance. This distance function is designed to be more sensitive to the "true" similarities between data points, as defined by their semantic labels, and less sensitive to spurious correlations due to dataset biases.
The training process involves optimizing this distance metric using a combination of standard metric learning losses (e.g. triplet loss) and a novel "debiasing" term. This debiasing term encourages the model to find a distance measure that minimizes the influence of known biases in the dataset, such as demographic factors.
Through extensive experiments on benchmark datasets, the authors demonstrate that their explainable metric learning approach can lead to significant improvements in model fairness and reliability, without sacrificing overall predictive performance. The learned distance metrics also provide useful insights into the inner workings of the model and the nature of the dataset biases.
Critical Analysis
The paper makes a valuable contribution by proposing a novel approach to address dataset biases in machine learning, a critical issue in the development of fair and reliable AI systems.
One key strength of the method is its ability to provide "explanations" for the model's behavior, by revealing the distance metric it has learned and how it differs from standard Euclidean distance. This aligns with the growing emphasis on explainable AI and the need for more transparent and accountable machine learning models.
However, the paper also acknowledges several limitations and areas for future work. For example, the approach relies on having prior knowledge of the specific biases present in the dataset, which may not always be the case in practice. Additionally, the computational overhead of learning the specialized distance metric may be a concern for some real-world applications.
Further research is also needed to better understand the relationship between dataset biases and model performance, as well as to explore techniques for aligning AI models with human knowledge and values.
Conclusion
This paper presents a promising approach to address dataset biases in machine learning, by learning an "explainable" distance metric that can deflate the influence of known biases. The ability to provide insights into the model's decision-making process is a key strength, as it aligns with the growing emphasis on explainable and reliable AI.
While the method has some limitations, it represents an important step forward in the quest to develop fair and trustworthy machine learning systems that can be deployed with confidence in high-stakes applications. Continued research in this area, along with a focus on aligning AI with human values, will be crucial for realizing the full potential of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Explainable Metric Learning for Deflating Data Bias
Emma Andrews, Prabhat Mishra
Image classification is an essential part of computer vision which assigns a given input image to a specific category based on the similarity evaluation within given criteria. While promising classifiers can be obtained through deep learning models, these approaches lack explainability, where the classification results are hard to interpret in a human-understandable way. In this paper, we present an explainable metric learning framework, which constructs hierarchical levels of semantic segments of an image for better interpretability. The key methodology involves a bottom-up learning strategy, starting by training the local metric learning model for the individual segments and then combining segments to compose comprehensive metrics in a tree. Specifically, our approach enables a more human-understandable similarity measurement between two images based on the semantic segments within it, which can be utilized to generate new samples to reduce bias in a training dataset. Extensive experimental evaluation demonstrates that the proposed approach can drastically improve model accuracy compared with state-of-the-art methods.
Read more7/9/2024

0
Classification Metrics for Image Explanations: Towards Building Reliable XAI-Evaluations
Benjamin Fresz, Lena Lorcher, Marco Huber
Decision processes of computer vision models - especially deep neural networks - are opaque in nature, meaning that these decisions cannot be understood by humans. Thus, over the last years, many methods to provide human-understandable explanations have been proposed. For image classification, the most common group are saliency methods, which provide (super-)pixelwise feature attribution scores for input images. But their evaluation still poses a problem, as their results cannot be simply compared to the unknown ground truth. To overcome this, a slew of different proxy metrics have been defined, which are - as the explainability methods themselves - often built on intuition and thus, are possibly unreliable. In this paper, new evaluation metrics for saliency methods are developed and common saliency methods are benchmarked on ImageNet. In addition, a scheme for reliability evaluation of such metrics is proposed that is based on concepts from psychometric testing. The used code can be found at https://github.com/lelo204/ClassificationMetricsForImageExplanations .
Read more6/10/2024

0
Aligning Human Knowledge with Visual Concepts Towards Explainable Medical Image Classification
Yunhe Gao, Difei Gu, Mu Zhou, Dimitris Metaxas
Although explainability is essential in the clinical diagnosis, most deep learning models still function as black boxes without elucidating their decision-making process. In this study, we investigate the explainable model development that can mimic the decision-making process of human experts by fusing the domain knowledge of explicit diagnostic criteria. We introduce a simple yet effective framework, Explicd, towards Explainable language-informed criteria-based diagnosis. Explicd initiates its process by querying domain knowledge from either large language models (LLMs) or human experts to establish diagnostic criteria across various concept axes (e.g., color, shape, texture, or specific patterns of diseases). By leveraging a pretrained vision-language model, Explicd injects these criteria into the embedding space as knowledge anchors, thereby facilitating the learning of corresponding visual concepts within medical images. The final diagnostic outcome is determined based on the similarity scores between the encoded visual concepts and the textual criteria embeddings. Through extensive evaluation of five medical image classification benchmarks, Explicd has demonstrated its inherent explainability and extends to improve classification performance compared to traditional black-box models.
Read more6/11/2024
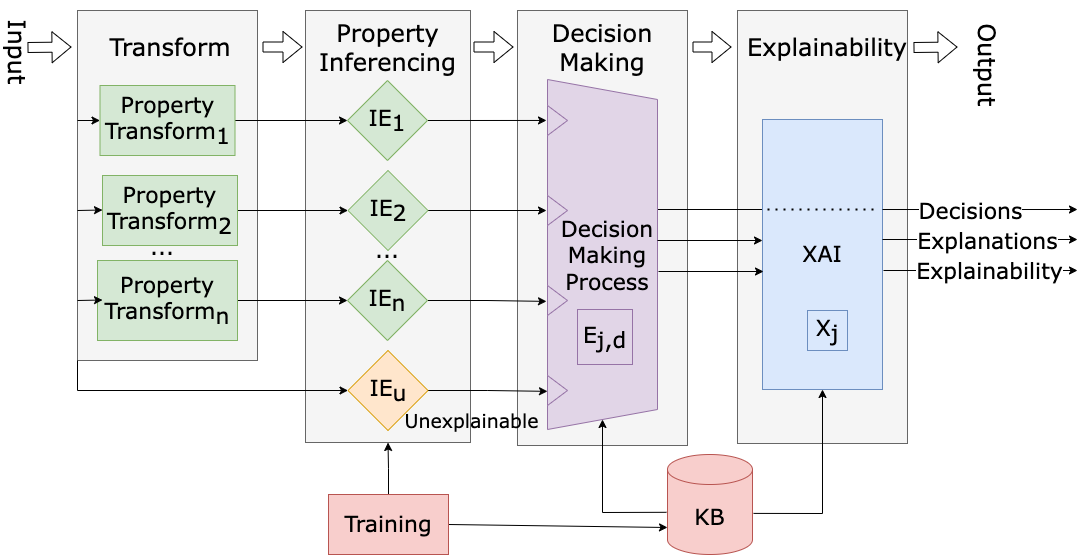
0
An AI Architecture with the Capability to Explain Recognition Results
Paul Whitten, Francis Wolff, Chris Papachristou
Explainability is needed to establish confidence in machine learning results. Some explainable methods take a post hoc approach to explain the weights of machine learning models, others highlight areas of the input contributing to decisions. These methods do not adequately explain decisions, in plain terms. Explainable property-based systems have been shown to provide explanations in plain terms, however, they have not performed as well as leading unexplainable machine learning methods. This research focuses on the importance of metrics to explainability and contributes two methods yielding performance gains. The first method introduces a combination of explainable and unexplainable flows, proposing a metric to characterize explainability of a decision. The second method compares classic metrics for estimating the effectiveness of neural networks in the system, posing a new metric as the leading performer. Results from the new methods and examples from handwritten datasets are presented.
Read more7/4/2024