Explaining Black-box Model Predictions via Two-level Nested Feature Attributions with Consistency Property

0
📈
Sign in to get full access
Overview
- Explains a method for extracting both high-level and low-level feature attributions from black-box machine learning models
- Introduces a "consistency property" to ensure the high-level and low-level attributions are aligned
- Demonstrated on image classification and text classification tasks
Plain English Explanation
Machine learning models, especially complex "black-box" models, can be difficult for humans to understand. Techniques that explain the predictions of these models are crucial to build trust in AI systems.
The inputs to these models often have a nested structure - high-level features that are each made up of multiple low-level features. For example, in an image classification task, a high-level feature might be "the presence of a dog," which is composed of lower-level features like "pointy ears," "furry texture," and "four-legged shape."
To fully understand these models, we need explanations at both the high-level and low-level. High-level feature attributions (HiFAs) tell us which high-level features are most important, while low-level feature attributions (LoFAs) explain the contributions of the underlying low-level features.
This paper proposes a new method to estimate both HiFAs and LoFAs simultaneously, while ensuring they are consistent with each other. The key idea is to introduce a "consistency property" that bridges the separate optimization problems for the two types of attributions. This helps produce explanations that are faithful to the black-box model and internally coherent.
Technical Explanation
The proposed method is model-agnostic, meaning it can work with any black-box machine learning model, not just a specific architecture. It starts by decomposing the input into high-level and low-level features, similar to how deep learning models learn hierarchical representations.
The method then estimates the HiFAs and LoFAs simultaneously, using a smaller number of queries to the black-box model compared to other explanation techniques. This is achieved by introducing a "consistency property" - a constraint that ensures the high-level and low-level attributions are aligned and make sense together.
Experiments on image classification and text classification tasks show that the proposed method produces accurate, faithful, and coherent explanations, outperforming other state-of-the-art techniques. The HiFAs highlight the most important high-level features, while the LoFAs provide detailed insights into the underlying reasons for the model's predictions.
Critical Analysis
The paper acknowledges that the proposed method, like other explanation techniques, has some limitations. For example, it assumes the input has a known nested structure, which may not always be the case. Additionally, the experiments focus on specific domains like image and text classification, so further research is needed to evaluate the method's generalizability to other types of machine learning problems.
One potential concern is that the "consistency property" introduced in the method may be too restrictive, potentially sacrificing some flexibility or accuracy in the explanations. It would be interesting to see how the method performs compared to approaches that allow more freedom between the high-level and low-level attributions.
Overall, this research represents an important step forward in making complex black-box models more transparent and interpretable. By providing explanations at both the high-level and low-level, the proposed method can help build greater trust in AI systems and enable more meaningful interactions between humans and these powerful machine learning models.
Conclusion
This paper introduces a novel technique for extracting both high-level and low-level feature attributions from black-box machine learning models. By enforcing a "consistency property" between the two types of explanations, the method produces accurate and coherent insights that can help users better understand the inner workings of complex AI systems.
The demonstrated success on image and text classification tasks suggests this approach could have wide-ranging applications, potentially enabling more transparent and trustworthy AI across many domains. As machine learning models continue to grow in power and complexity, techniques like this will become increasingly important to ensure these technologies are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Explaining Black-box Model Predictions via Two-level Nested Feature Attributions with Consistency Property
Yuya Yoshikawa, Masanari Kimura, Ryotaro Shimizu, Yuki Saito
Techniques that explain the predictions of black-box machine learning models are crucial to make the models transparent, thereby increasing trust in AI systems. The input features to the models often have a nested structure that consists of high- and low-level features, and each high-level feature is decomposed into multiple low-level features. For such inputs, both high-level feature attributions (HiFAs) and low-level feature attributions (LoFAs) are important for better understanding the model's decision. In this paper, we propose a model-agnostic local explanation method that effectively exploits the nested structure of the input to estimate the two-level feature attributions simultaneously. A key idea of the proposed method is to introduce the consistency property that should exist between the HiFAs and LoFAs, thereby bridging the separate optimization problems for estimating them. Thanks to this consistency property, the proposed method can produce HiFAs and LoFAs that are both faithful to the black-box models and consistent with each other, using a smaller number of queries to the models. In experiments on image classification in multiple instance learning and text classification using language models, we demonstrate that the HiFAs and LoFAs estimated by the proposed method are accurate, faithful to the behaviors of the black-box models, and provide consistent explanations.
Read more5/24/2024

0
Selective Explanations
Lucas Monteiro Paes, Dennis Wei, Flavio P. Calmon
Feature attribution methods explain black-box machine learning (ML) models by assigning importance scores to input features. These methods can be computationally expensive for large ML models. To address this challenge, there has been increasing efforts to develop amortized explainers, where a machine learning model is trained to predict feature attribution scores with only one inference. Despite their efficiency, amortized explainers can produce inaccurate predictions and misleading explanations. In this paper, we propose selective explanations, a novel feature attribution method that (i) detects when amortized explainers generate low-quality explanations and (ii) improves these explanations using a technique called explanations with initial guess. Our selective explanation method allows practitioners to specify the fraction of samples that receive explanations with initial guess, offering a principled way to bridge the gap between amortized explainers and their high-quality counterparts.
Read more5/31/2024
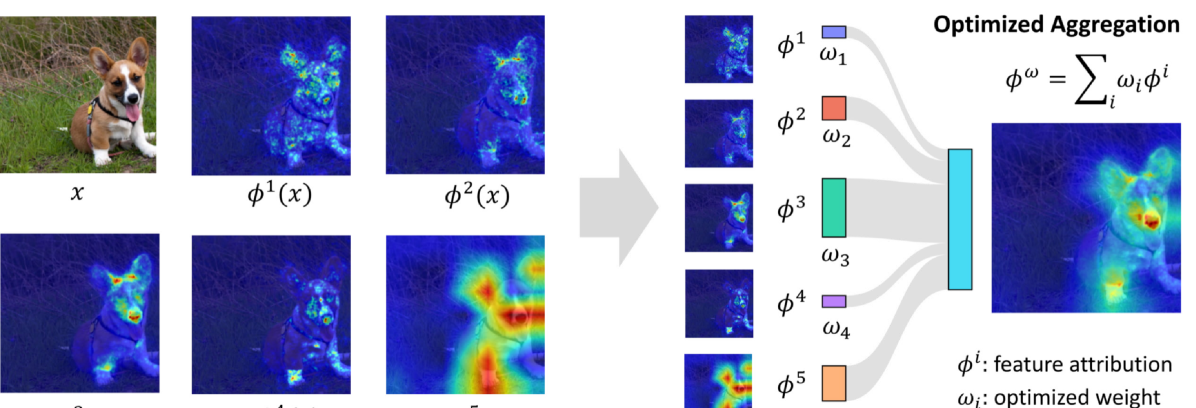
0
Provably Better Explanations with Optimized Aggregation of Feature Attributions
Thomas Decker, Ananta R. Bhattarai, Jindong Gu, Volker Tresp, Florian Buettner
Using feature attributions for post-hoc explanations is a common practice to understand and verify the predictions of opaque machine learning models. Despite the numerous techniques available, individual methods often produce inconsistent and unstable results, putting their overall reliability into question. In this work, we aim to systematically improve the quality of feature attributions by combining multiple explanations across distinct methods or their variations. For this purpose, we propose a novel approach to derive optimal convex combinations of feature attributions that yield provable improvements of desired quality criteria such as robustness or faithfulness to the model behavior. Through extensive experiments involving various model architectures and popular feature attribution techniques, we demonstrate that our combination strategy consistently outperforms individual methods and existing baselines.
Read more6/10/2024
🌐
0
On Gradient-like Explanation under a Black-box Setting: When Black-box Explanations Become as Good as White-box
Yi Cai, Gerhard Wunder
Attribution methods shed light on the explainability of data-driven approaches such as deep learning models by uncovering the most influential features in a to-be-explained decision. While determining feature attributions via gradients delivers promising results, the internal access required for acquiring gradients can be impractical under safety concerns, thus limiting the applicability of gradient-based approaches. In response to such limited flexibility, this paper presents methodAbr~(gradient-estimation-based explanation), an approach that produces gradient-like explanations through only query-level access. The proposed approach holds a set of fundamental properties for attribution methods, which are mathematically rigorously proved, ensuring the quality of its explanations. In addition to the theoretical analysis, with a focus on image data, the experimental results empirically demonstrate the superiority of the proposed method over state-of-the-art black-box methods and its competitive performance compared to methods with full access.
Read more5/15/2024