Explaining Vision-Language Similarities in Dual Encoders with Feature-Pair Attributions

0

Sign in to get full access
Overview
- The research paper explores how dual encoder models, which jointly encode visual and textual inputs, develop similar representations between the vision and language modalities.
- The paper introduces a novel technique called "Feature-Pair Attributions" to analyze the correspondence between visual and textual features in these models.
- The findings provide insights into the inner workings of dual encoder architectures and their ability to learn cross-modal associations.
Plain English Explanation
The paper looks at how vision-language models are able to understand the connections between images and text. These models are trained on large datasets of image-caption pairs, and they learn to encode both visual and textual information into a shared representation space.
The researchers wanted to understand how the model's internal "features" - the individual components that make up its understanding - relate to each other across the visual and language domains. To do this, they developed a new analysis technique called "Feature-Pair Attributions." This allows them to identify specific visual and textual features that are strongly associated with each other within the model.
By applying this technique, the researchers found that the model is able to discover meaningful correspondences between visual elements (like objects, textures, and spatial relationships) and textual elements (like words and phrases). For example, the model might learn that the visual feature of a "dog" is strongly linked to the textual feature of the word "dog."
This provides insights into how vision-language models are able to refine their perceptions and link representations between the two modalities. It suggests that these models are able to develop structured representations that capture the meaningful relationships between visual and textual concepts.
Technical Explanation
The paper introduces a novel technique called "Feature-Pair Attributions" to analyze the correspondence between visual and textual features in dual encoder models. These models jointly encode both visual and textual inputs into a shared representation space, allowing them to learn cross-modal associations.
The researchers apply this technique to two popular dual encoder architectures: CLIP and ALIGN. They first train these models on large image-text datasets, then use Feature-Pair Attributions to identify the specific visual and textual features that are strongly correlated within the model's internal representations.
The key idea behind Feature-Pair Attributions is to measure the "attribution" or importance of each feature pair (one visual, one textual) in the model's overall prediction. This is done by perturbing the input features and observing the change in the model's output, which reveals how much each feature pair contributes to the final result.
The analysis shows that the dual encoder models are able to discover meaningful correspondences between visual elements (like objects, textures, and spatial relationships) and textual elements (like words and phrases). For example, the visual feature of a "dog" is strongly associated with the textual feature of the word "dog" within the model's representations.
These findings provide insight into how dual encoder architectures are able to link representations and develop structured representations that capture the cross-modal associations between vision and language.
Critical Analysis
The paper presents a novel and insightful analysis of dual encoder vision-language models. The Feature-Pair Attributions technique provides a useful tool for probing the inner workings of these models and understanding how they learn to connect visual and textual features.
One potential limitation of the study is that it focuses on two specific model architectures (CLIP and ALIGN) and may not generalize to all dual encoder models. Additionally, the analysis is based on the models' final representations and does not examine the evolution of these representations during training.
Further research could explore how Feature-Pair Attributions vary across different model architectures, training datasets, and fine-tuning tasks. It would also be interesting to investigate the diversity of captions generated by these models and how their internal representations relate to this.
Overall, the paper makes a valuable contribution by shedding light on the inner workings of dual encoder vision-language models and providing a new analytical tool for the research community to build upon.
Conclusion
This research paper presents a novel technique called "Feature-Pair Attributions" to analyze the correspondence between visual and textual features in dual encoder vision-language models. The findings offer insights into how these models are able to refine their perceptions and link representations between the two modalities, suggesting that they develop structured representations that capture meaningful cross-modal associations.
The technique and insights provided in this paper have the potential to advance our understanding of multimodal vision-language models and inform the development of more robust and interpretable systems that can effectively bridge the gap between visual and textual information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Explaining Vision-Language Similarities in Dual Encoders with Feature-Pair Attributions
Lucas Moller, Pascal Tilli, Ngoc Thang Vu, Sebastian Pad'o
Dual encoder architectures like CLIP models map two types of inputs into a shared embedding space and learn similarities between them. However, it is not understood how such models compare two inputs. Here, we address this research gap with two contributions. First, we derive a method to attribute predictions of any differentiable dual encoder onto feature-pair interactions between its inputs. Second, we apply our method to CLIP-type models and show that they learn fine-grained correspondences between parts of captions and regions in images. They match objects across input modes and also account for mismatches. However, this visual-linguistic grounding ability heavily varies between object classes, depends on the training data distribution, and largely improves after in-domain training. Using our method we can identify knowledge gaps about specific object classes in individual models and can monitor their improvement upon fine-tuning.
Read more8/27/2024
✨
0
Adapting Dual-encoder Vision-language Models for Paraphrased Retrieval
Jiacheng Cheng, Hijung Valentina Shin, Nuno Vasconcelos, Bryan Russell, Fabian Caba Heilbron
In the recent years, the dual-encoder vision-language models (eg CLIP) have achieved remarkable text-to-image retrieval performance. However, we discover that these models usually results in very different retrievals for a pair of paraphrased queries. Such behavior might render the retrieval system less predictable and lead to user frustration. In this work, we consider the task of paraphrased text-to-image retrieval where a model aims to return similar results given a pair of paraphrased queries. To start with, we collect a dataset of paraphrased image descriptions to facilitate quantitative evaluation for this task. We then hypothesize that the undesired behavior of existing dual-encoder model is due to their text towers which are trained on image-sentence pairs and lack the ability to capture the semantic similarity between paraphrased queries. To improve on this, we investigate multiple strategies for training a dual-encoder model starting from a language model pretrained on a large text corpus. Compared to public dual-encoder models such as CLIP and OpenCLIP, the model trained with our best adaptation strategy achieves a significantly higher ranking similarity for paraphrased queries while maintaining similar zero-shot classification and retrieval accuracy.
Read more5/7/2024
0
Finetuning CLIP to Reason about Pairwise Differences
Dylan Sam, Devin Willmott, Joao D. Semedo, J. Zico Kolter
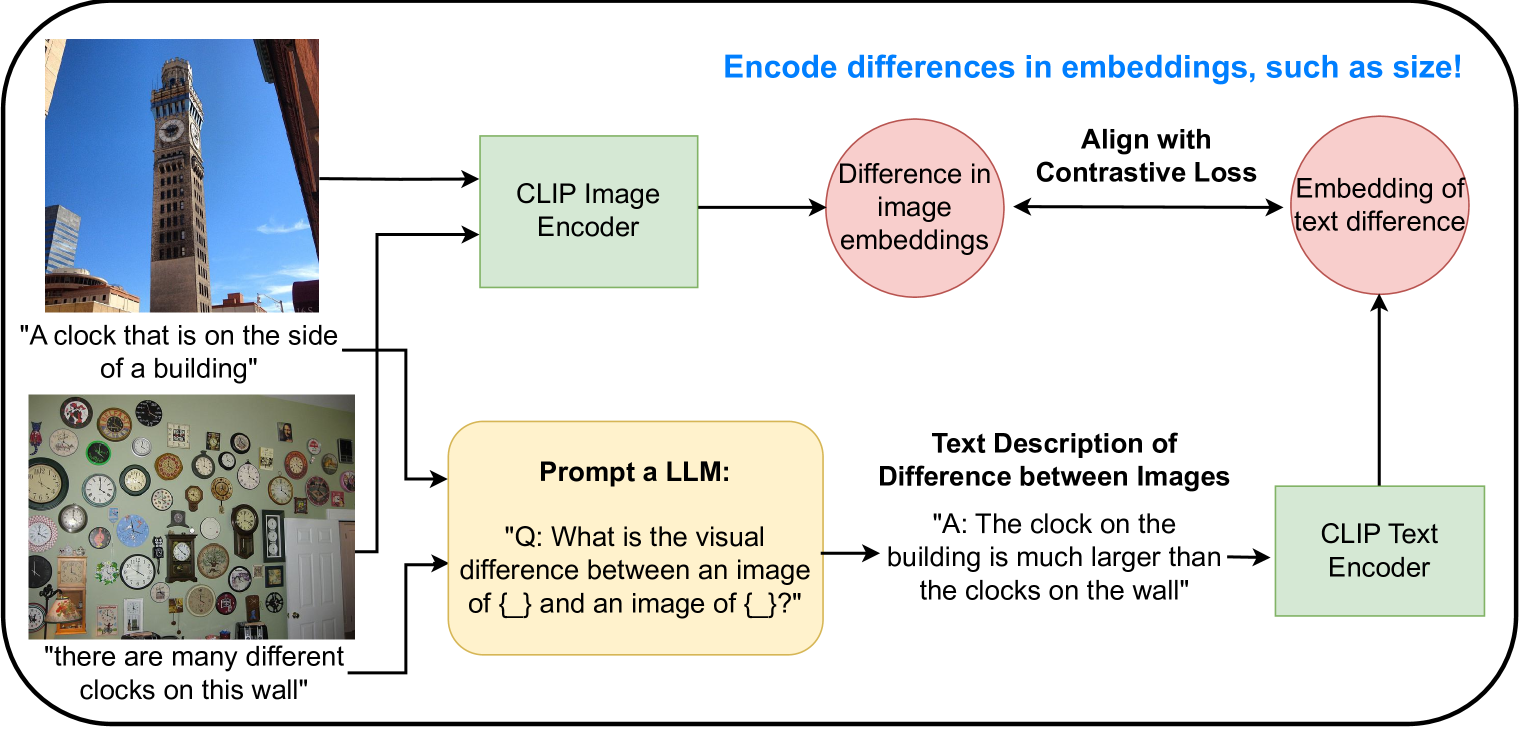
Vision-language models (VLMs) such as CLIP are trained via contrastive learning between text and image pairs, resulting in aligned image and text embeddings that are useful for many downstream tasks. A notable drawback of CLIP, however, is that the resulting embedding space seems to lack some of the structure of their purely text-based alternatives. For instance, while text embeddings have been long noted to satisfy emph{analogies} in embedding space using vector arithmetic, CLIP has no such property. In this paper, we propose an approach to natively train CLIP in a contrastive manner to reason about differences in embedding space. We finetune CLIP so that the differences in image embedding space correspond to emph{text descriptions of the image differences}, which we synthetically generate with large language models on image-caption paired datasets. We first demonstrate that our approach yields significantly improved capabilities in ranking images by a certain attribute (e.g., elephants are larger than cats), which is useful in retrieval or constructing attribute-based classifiers, and improved zeroshot classification performance on many downstream image classification tasks. In addition, our approach enables a new mechanism for inference that we refer to as comparative prompting, where we leverage prior knowledge of text descriptions of differences between classes of interest, achieving even larger performance gains in classification. Finally, we illustrate that the resulting embeddings obey a larger degree of geometric properties in embedding space, such as in text-to-image generation.
Read more9/17/2024
0
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
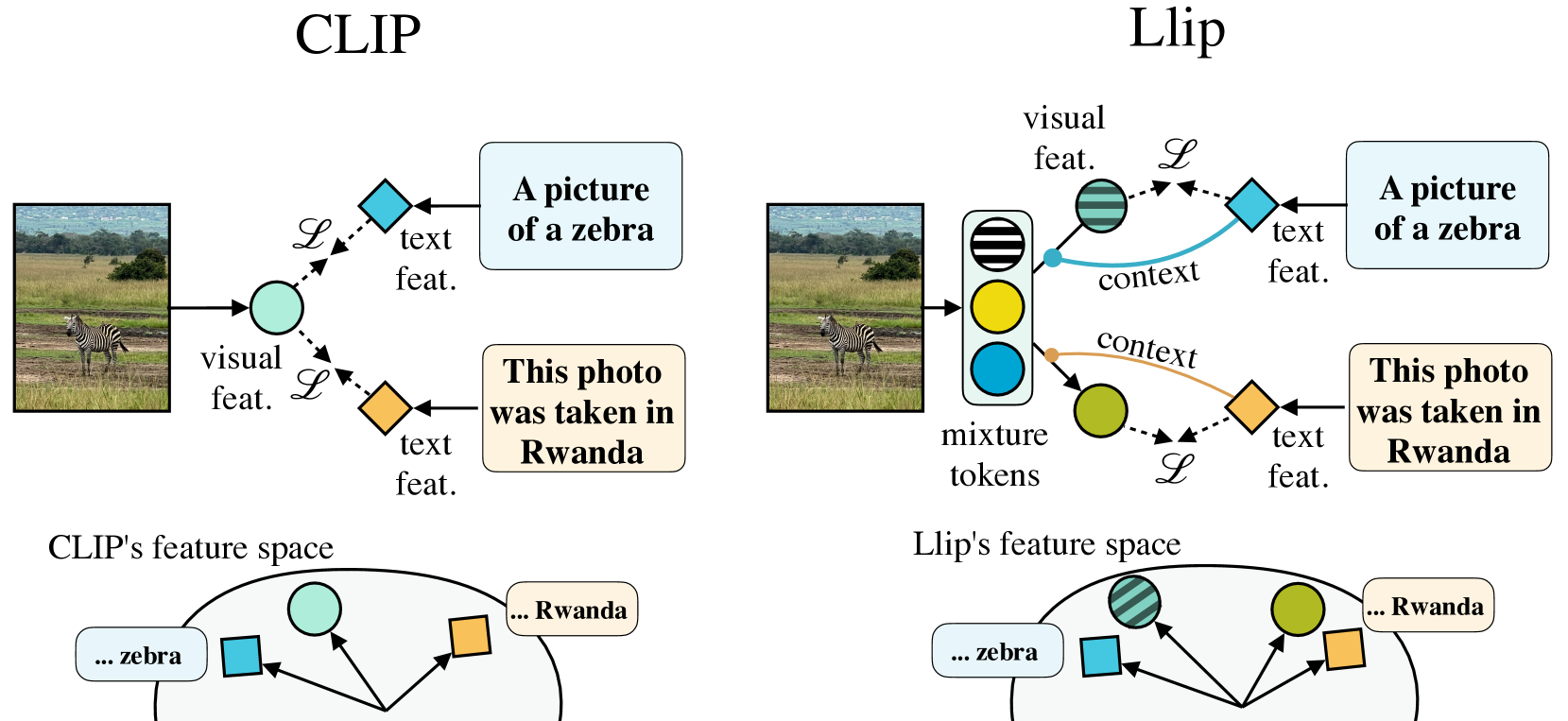
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
Read more5/15/2024