Exploring 3D-aware Latent Spaces for Efficiently Learning Numerous Scenes

0
Sign in to get full access
Overview
• This paper explores the use of 3D-aware latent spaces for efficiently learning numerous scenes in the context of neural rendering techniques like NeRF.
• The key idea is to leverage 3D structure in the latent representations to enable faster learning and more efficient scene representation compared to approaches that treat scenes as unstructured collections of images.
• The paper presents several techniques for imbuing latent spaces with 3D awareness and evaluates their performance on various 3D reconstruction and view synthesis tasks.
Plain English Explanation
The paper is looking at how neural networks can learn to represent 3D scenes in an efficient way. Current approaches often treat scenes like a jumble of 2D images, which can be slow and inefficient. Instead, the researchers wanted to see if they could build neural networks that are "aware" of the 3D structure of the scenes they're learning.
The key idea is to have the neural network's internal representations - the mathematical patterns it learns - reflect the 3D geometry of the scene. This 3D-aware latent space, as they call it, allows the network to learn scenes more quickly and represent them more compactly compared to treating them as unstructured collections of 2D images.
The paper explores different techniques for imbuing these latent representations with 3D awareness, and evaluates how well they perform on tasks like reconstructing 3D shapes from 2D images and generating new views of a 3D scene. The goal is to find ways to make neural networks that work with 3D data more efficient and practical to use.
Technical Explanation
The paper introduces several techniques for learning 3D-aware latent representations for efficient scene learning. This builds on prior work in neural rendering techniques like NeRF that can synthesize novel views of a 3D scene from 2D images.
One approach is to disentangle the latent representation into separate components for scene geometry, appearance, and other factors. This allows the network to more efficiently learn and represent the underlying 3D structure. The paper also explores incorporating 3D priors into the latent space, such as using a voxel grid representation, to further imbue the representations with 3D awareness.
Additionally, the authors investigate meta-learning techniques to enable rapid adaptation to new scenes by leveraging shared structure across scenes in the latent representations. They also present an incremental learning method that allows the model to continually expand its understanding of 3D scenes over time.
Experiments on tasks like view synthesis, 3D reconstruction, and scene understanding demonstrate the benefits of these 3D-aware latent representations compared to more naïve approaches. The techniques enable faster learning, more compact scene representations, and improved performance on downstream 3D perception and generation tasks.
Critical Analysis
The paper makes a strong case for the advantages of 3D-aware latent representations, but it also acknowledges some limitations and open questions. For example, the authors note that the meta-learning and incremental learning techniques, while promising, still have room for improvement in terms of sample efficiency and scalability.
Additionally, the paper focuses primarily on synthetic datasets and relatively simple 3D scenes. It will be important to evaluate these methods on more complex, real-world 3D data to understand their practical limitations and potential deployment challenges.
Another area for further research is the interpretability and explainability of the learned 3D-aware latent representations. Understanding how the network's internal representations reflect the underlying 3D geometry could lead to more robust and trustworthy 3D perception systems.
Overall, this paper represents an important step forward in the quest to build neural networks that can efficiently and effectively reason about 3D environments. The techniques developed here could have far-reaching implications for applications ranging from robotics to augmented reality.
Conclusion
This paper presents a novel approach to learning 3D-aware latent representations for efficient scene understanding and generation. By imbuing the neural network's internal representations with knowledge of 3D structure, the researchers were able to achieve faster learning, more compact scene encoding, and improved performance on a variety of 3D perception and generation tasks.
The techniques developed in this work, such as disentangled latent spaces, 3D priors, meta-learning, and incremental learning, represent important advancements in the field of neural rendering and 3D computer vision. As these methods are further refined and applied to more complex, real-world scenarios, they have the potential to unlock new capabilities in areas like robotics, autonomous driving, and augmented reality.
Overall, this paper is a significant contribution to the ongoing effort to build intelligent systems that can efficiently and effectively reason about the 3D world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring 3D-aware Latent Spaces for Efficiently Learning Numerous Scenes
Antoine Schnepf, Karim Kassab, Jean-Yves Franceschi, Laurent Caraffa, Flavian Vasile, Jeremie Mary, Andrew Comport, Val'erie Gouet-Brunet
We present a method enabling the scaling of NeRFs to learn a large number of semantically-similar scenes. We combine two techniques to improve the required training time and memory cost per scene. First, we learn a 3D-aware latent space in which we train Tri-Plane scene representations, hence reducing the resolution at which scenes are learned. Moreover, we present a way to share common information across scenes, hence allowing for a reduction of model complexity to learn a particular scene. Our method reduces effective per-scene memory costs by 44% and per-scene time costs by 86% when training 1000 scenes. Our project page can be found at https://3da-ae.github.io .
Read more5/20/2024

0
Query-based Semantic Gaussian Field for Scene Representation in Reinforcement Learning
Jiaxu Wang, Ziyi Zhang, Qiang Zhang, Jia Li, Jingkai Sun, Mingyuan Sun, Junhao He, Renjing Xu
Latent scene representation plays a significant role in training reinforcement learning (RL) agents. To obtain good latent vectors describing the scenes, recent works incorporate the 3D-aware latent-conditioned NeRF pipeline into scene representation learning. However, these NeRF-related methods struggle to perceive 3D structural information due to the inefficient dense sampling in volumetric rendering. Moreover, they lack fine-grained semantic information included in their scene representation vectors because they evenly consider free and occupied spaces. Both of them can destroy the performance of downstream RL tasks. To address the above challenges, we propose a novel framework that adopts the efficient 3D Gaussian Splatting (3DGS) to learn 3D scene representation for the first time. In brief, we present the Query-based Generalizable 3DGS to bridge the 3DGS technique and scene representations with more geometrical awareness than those in NeRFs. Moreover, we present the Hierarchical Semantics Encoding to ground the fine-grained semantic features to 3D Gaussians and further distilled to the scene representation vectors. We conduct extensive experiments on two RL platforms including Maniskill2 and Robomimic across 10 different tasks. The results show that our method outperforms the other 5 baselines by a large margin. We achieve the best success rates on 8 tasks and the second-best on the other two tasks.
Read more7/30/2024

0
SCARF: Scalable Continual Learning Framework for Memory-efficient Multiple Neural Radiance Fields
Yuze Wang, Junyi Wang, Chen Wang, Wantong Duan, Yongtang Bao, Yue Qi
This paper introduces a novel continual learning framework for synthesising novel views of multiple scenes, learning multiple 3D scenes incrementally, and updating the network parameters only with the training data of the upcoming new scene. We build on Neural Radiance Fields (NeRF), which uses multi-layer perceptron to model the density and radiance field of a scene as the implicit function. While NeRF and its extensions have shown a powerful capability of rendering photo-realistic novel views in a single 3D scene, managing these growing 3D NeRF assets efficiently is a new scientific problem. Very few works focus on the efficient representation or continuous learning capability of multiple scenes, which is crucial for the practical applications of NeRF. To achieve these goals, our key idea is to represent multiple scenes as the linear combination of a cross-scene weight matrix and a set of scene-specific weight matrices generated from a global parameter generator. Furthermore, we propose an uncertain surface knowledge distillation strategy to transfer the radiance field knowledge of previous scenes to the new model. Representing multiple 3D scenes with such weight matrices significantly reduces memory requirements. At the same time, the uncertain surface distillation strategy greatly overcomes the catastrophic forgetting problem and maintains the photo-realistic rendering quality of previous scenes. Experiments show that the proposed approach achieves state-of-the-art rendering quality of continual learning NeRF on NeRF-Synthetic, LLFF, and TanksAndTemples datasets while preserving extra low storage cost.
Read more9/10/2024
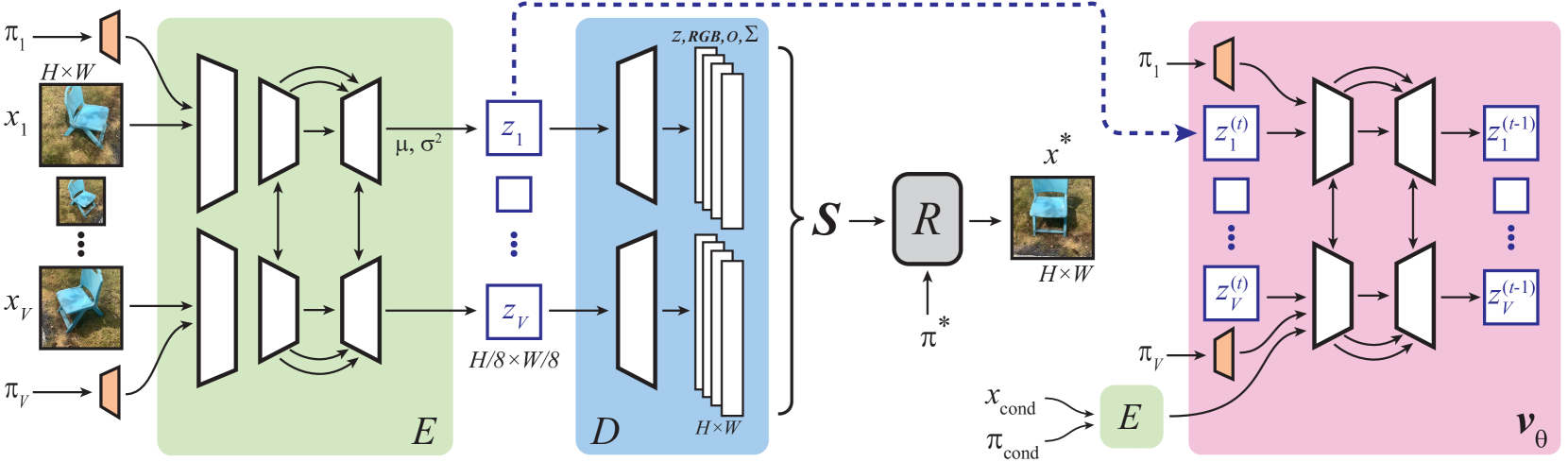
0
Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models
Paul Henderson, Melonie de Almeida, Daniela Ivanova, Titas Anciukeviv{c}ius
We present a latent diffusion model over 3D scenes, that can be trained using only 2D image data. To achieve this, we first design an autoencoder that maps multi-view images to 3D Gaussian splats, and simultaneously builds a compressed latent representation of these splats. Then, we train a multi-view diffusion model over the latent space to learn an efficient generative model. This pipeline does not require object masks nor depths, and is suitable for complex scenes with arbitrary camera positions. We conduct careful experiments on two large-scale datasets of complex real-world scenes -- MVImgNet and RealEstate10K. We show that our approach enables generating 3D scenes in as little as 0.2 seconds, either from scratch, from a single input view, or from sparse input views. It produces diverse and high-quality results while running an order of magnitude faster than non-latent diffusion models and earlier NeRF-based generative models
Read more6/21/2024