Exploring Context Window of Large Language Models via Decomposed Positional Vectors
2405.18009
0
0
Abstract
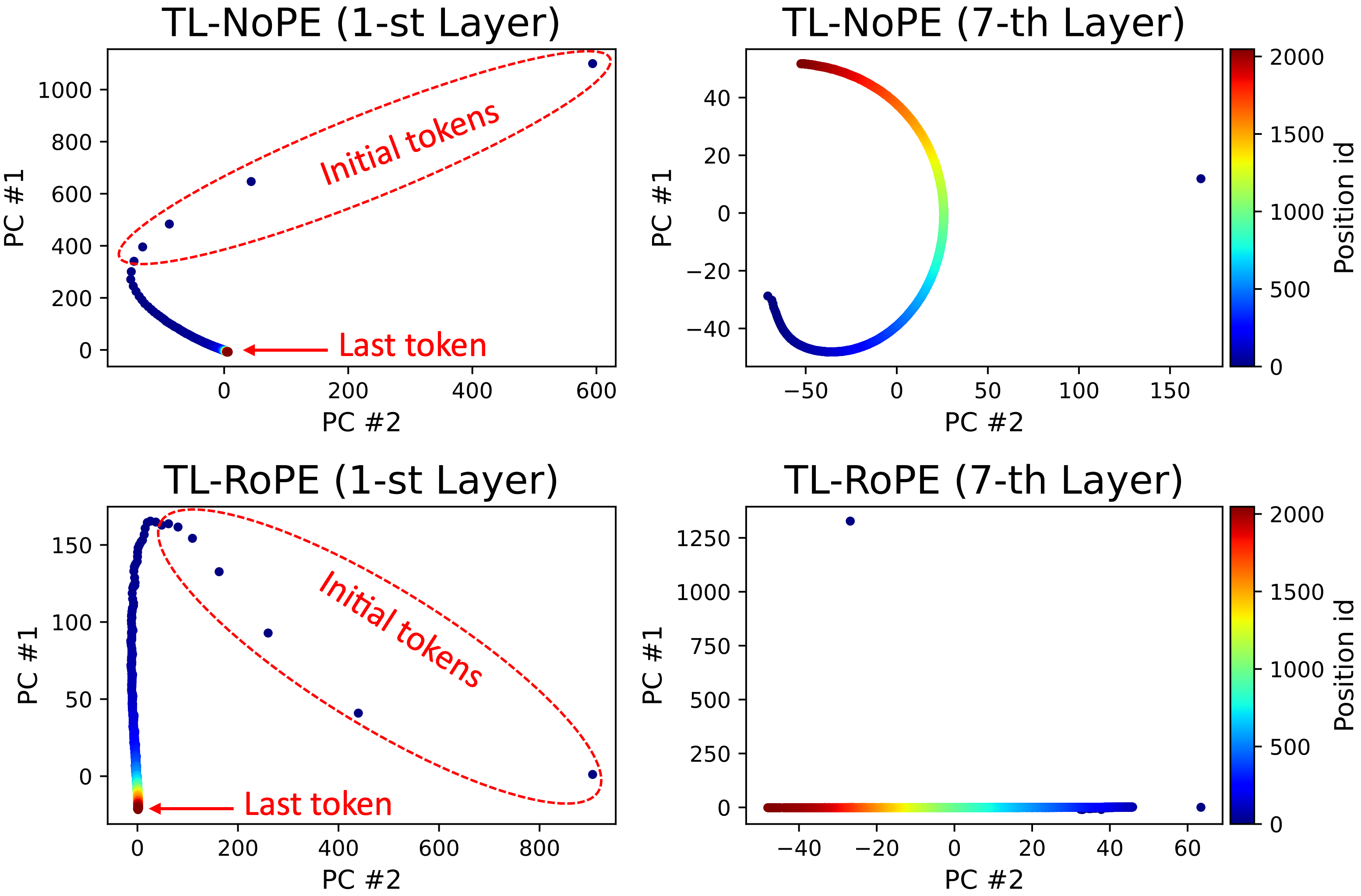
Transformer-based large language models (LLMs) typically have a limited context window, resulting in significant performance degradation when processing text beyond the length of the context window. Extensive studies have been proposed to extend the context window and achieve length extrapolation of LLMs, but there is still a lack of in-depth interpretation of these approaches. In this study, we explore the positional information within and beyond the context window for deciphering the underlying mechanism of LLMs. By using a mean-based decomposition method, we disentangle positional vectors from hidden states of LLMs and analyze their formation and effect on attention. Furthermore, when texts exceed the context window, we analyze the change of positional vectors in two settings, i.e., direct extrapolation and context window extension. Based on our findings, we design two training-free context window extension methods, positional vector replacement and attention window extension. Experimental results show that our methods can effectively extend the context window length.
Create account to get full access
Overview
• This paper explores the context window of large language models (LLMs) by decomposing their positional vectors.
• The researchers investigate how LLMs leverage and encode positional information to understand and generate text.
• They propose a novel technique to analyze the context window of LLMs, which could lead to insights about their inner workings and potentially enable improvements to their performance.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models rely on positional information - the location of each word in a sequence - to make sense of the text.
The researchers in this paper wanted to take a closer look at how LLMs use positional information. They developed a new way to "decompose" or break down the positional vectors that LLMs use. By analyzing these decomposed vectors, they could gain insights into the models' context window - how much information the models consider when processing a given word.
Understanding the context window is important because it reveals how LLMs capture and leverage the structure of language. This could lead to improvements in areas like long-context retrieval and extending the context window of these powerful models.
Technical Explanation
The researchers propose a novel technique called "Decomposed Positional Vectors" (DPV) to analyze the context window of LLMs. They start by extracting the positional vectors from a pre-trained LLM, which encode the location of each word in the input sequence.
They then decompose these positional vectors into a set of basis vectors, which represent different aspects of the positional information. By examining how the model's attention weights interact with these basis vectors, the researchers can gain insights into the model's understanding of positional context.
The team evaluates their DPV technique on several LLMs, including GPT-2 and BERT. Their analysis reveals that LLMs tend to have a relatively limited context window, focusing more on local positional information rather than long-range dependencies. This finding aligns with other research on the limitations of transformer models in capturing long-range contexts.
The researchers also demonstrate how their DPV approach can be used for fine-tuning LLMs in a position-aware manner, potentially improving the models' performance on tasks that require a deeper understanding of positional context.
Critical Analysis
The paper provides a novel and insightful approach to analyzing the context window of large language models. By decomposing the positional vectors, the researchers are able to gain a more nuanced understanding of how these models leverage positional information, which is a crucial aspect of their inner workings.
One potential limitation of the study is that it focuses primarily on analyzing the context window, without delving deeper into the implications for model performance and generalization. While the findings about the relatively limited context window of LLMs are interesting, the paper could have explored how this limitation might impact the models' ability to handle long-range dependencies or complex linguistic structures.
Additionally, the paper does not address potential biases or artifacts that might arise from the decomposition process itself. It would be valuable to understand the robustness of the DPV approach and how it might be affected by factors like model architecture, training data, or task-specific fine-tuning.
Overall, the research presented in this paper is a valuable contribution to the understanding of large language models and their positional encoding mechanisms. The DPV technique offers a promising avenue for further exploration and could lead to improvements in areas like long-context retrieval and position-aware fine-tuning.
Conclusion
This paper introduces a novel technique called Decomposed Positional Vectors (DPV) to analyze the context window of large language models (LLMs). The researchers use DPV to gain insights into how LLMs leverage and encode positional information, which is a crucial aspect of their ability to understand and generate human-like text.
The study reveals that LLMs tend to have a relatively limited context window, focusing more on local positional information rather than long-range dependencies. This finding aligns with other research on the limitations of transformer models in capturing long-range contexts.
The DPV approach offers a promising way to analyze and potentially improve the performance of LLMs, particularly in areas like long-context retrieval and position-aware fine-tuning. By better understanding the inner workings of these powerful AI systems, researchers can work towards unlocking their full potential and addressing their limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Mitigate Position Bias in Large Language Models via Scaling a Single Dimension
Yijiong Yu, Huiqiang Jiang, Xufang Luo, Qianhui Wu, Chin-Yew Lin, Dongsheng Li, Yuqing Yang, Yongfeng Huang, Lili Qiu
0
0
Large Language Models (LLMs) are increasingly applied in various real-world scenarios due to their excellent generalization capabilities and robust generative abilities. However, they exhibit position bias, also known as lost in the middle, a phenomenon that is especially pronounced in long-context scenarios, which indicates the placement of the key information in different positions of a prompt can significantly affect accuracy. This paper first explores the micro-level manifestations of position bias, concluding that attention weights are a micro-level expression of position bias. It further identifies that, in addition to position embeddings, causal attention mask also contributes to position bias by creating position-specific hidden states. Based on these insights, we propose a method to mitigate position bias by scaling this positional hidden states. Experiments on the NaturalQuestions Multi-document QA, KV retrieval, LongBench and timeline reorder tasks, using various models including RoPE models, context windowextended models, and Alibi models, demonstrate the effectiveness and generalizability of our approach. Our method can improve performance by up to 15.2% by modifying just one dimension of hidden states. Our code is available at https://aka.ms/PositionalHidden.
6/5/2024
💬
Beyond the Limits: A Survey of Techniques to Extend the Context Length in Large Language Models
Xindi Wang, Mahsa Salmani, Parsa Omidi, Xiangyu Ren, Mehdi Rezagholizadeh, Armaghan Eshaghi
0
0
Recently, large language models (LLMs) have shown remarkable capabilities including understanding context, engaging in logical reasoning, and generating responses. However, this is achieved at the expense of stringent computational and memory requirements, hindering their ability to effectively support long input sequences. This survey provides an inclusive review of the recent techniques and methods devised to extend the sequence length in LLMs, thereby enhancing their capacity for long-context understanding. In particular, we review and categorize a wide range of techniques including architectural modifications, such as modified positional encoding and altered attention mechanisms, which are designed to enhance the processing of longer sequences while avoiding a proportional increase in computational requirements. The diverse methodologies investigated in this study can be leveraged across different phases of LLMs, i.e., training, fine-tuning and inference. This enables LLMs to efficiently process extended sequences. The limitations of the current methodologies is discussed in the last section along with the suggestions for future research directions, underscoring the importance of sequence length in the continued advancement of LLMs.
5/30/2024
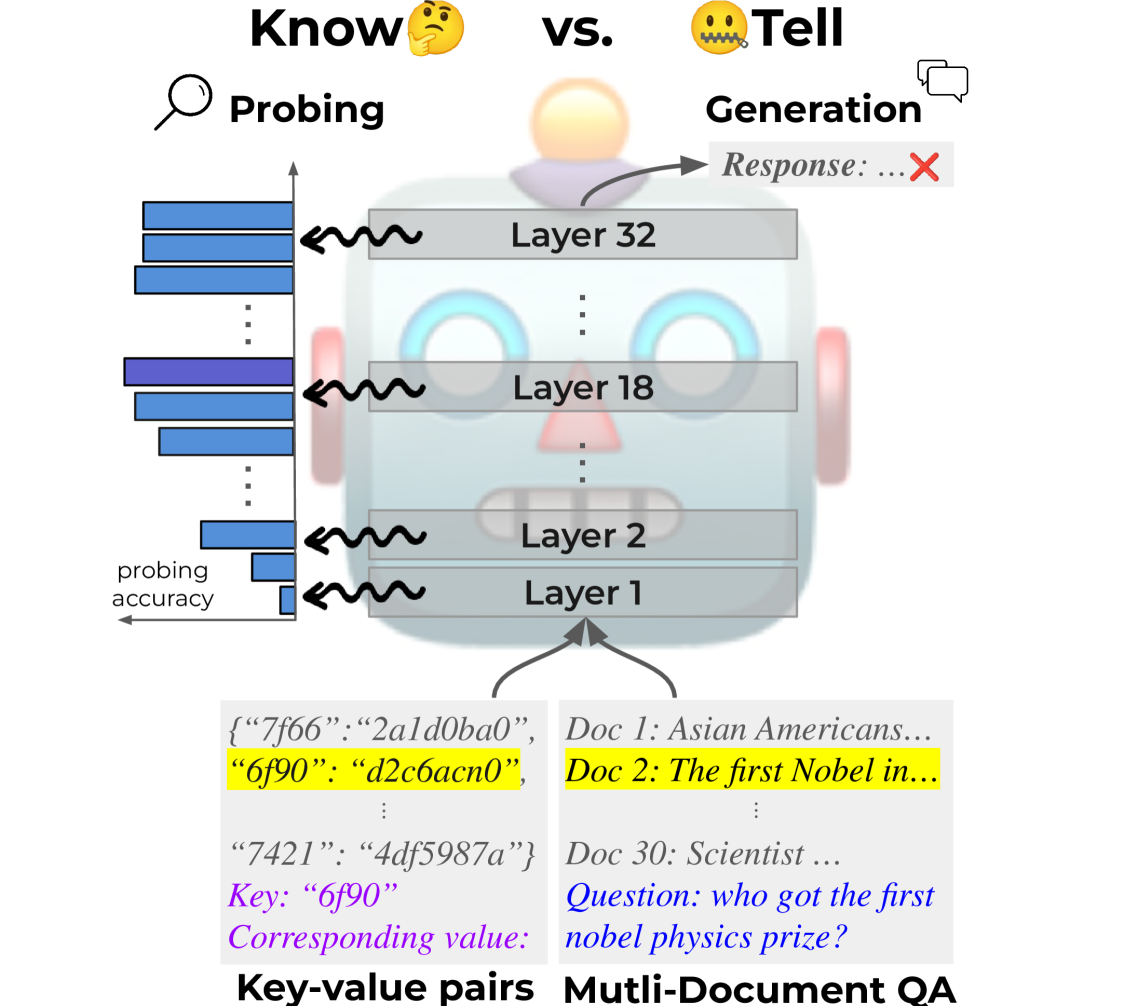
Insights into LLM Long-Context Failures: When Transformers Know but Don't Tell
Taiming Lu, Muhan Gao, Kuai Yu, Adam Byerly, Daniel Khashabi
0
0
Large Language Models (LLMs) exhibit positional bias, struggling to utilize information from the middle or end of long contexts. Our study explores LLMs' long-context reasoning by probing their hidden representations. We find that while LLMs encode the position of target information, they often fail to leverage this in generating accurate responses. This reveals a disconnect between information retrieval and utilization, a know but don't tell phenomenon. We further analyze the relationship between extraction time and final accuracy, offering insights into the underlying mechanics of transformer models.
6/24/2024
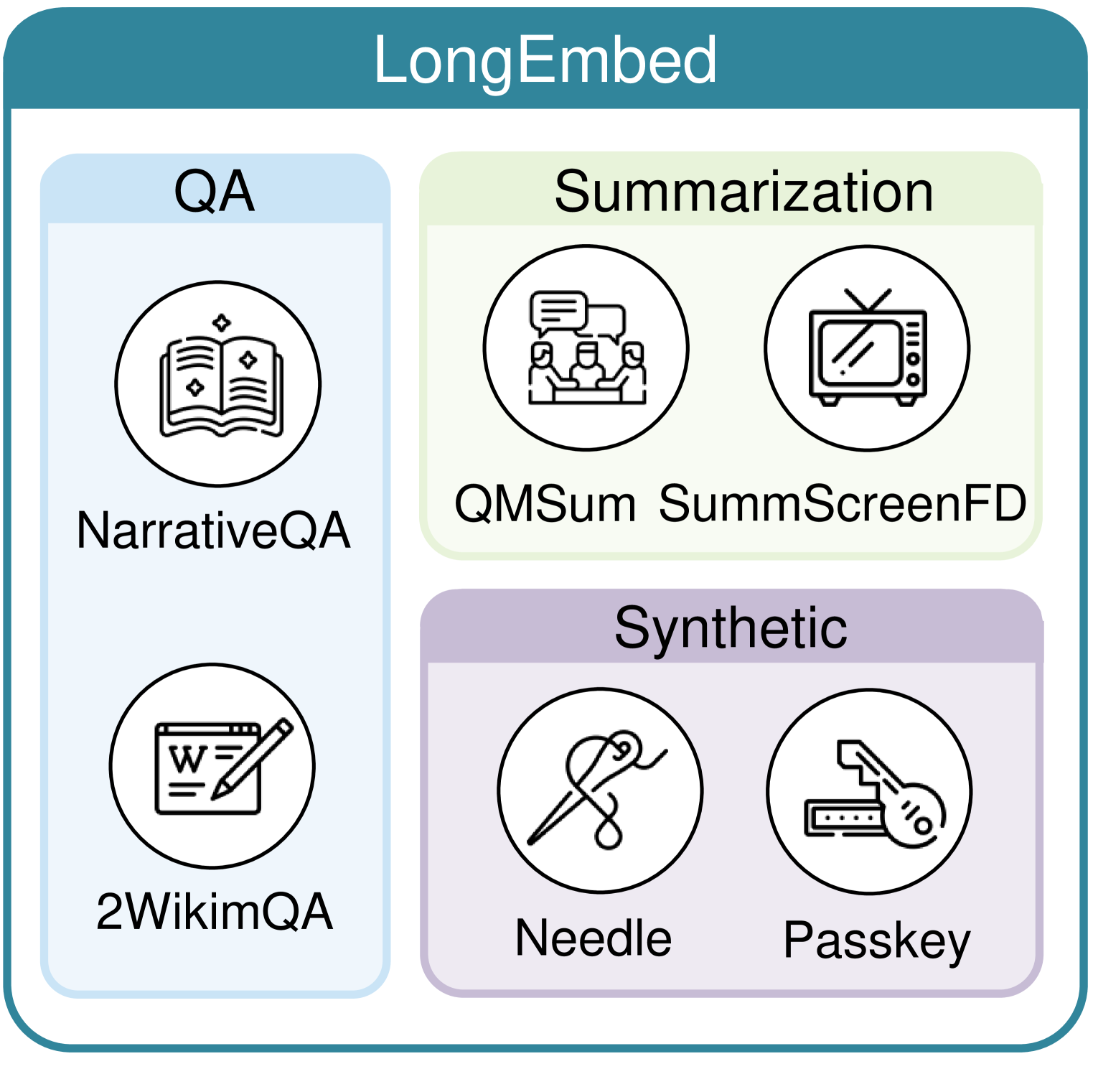
LongEmbed: Extending Embedding Models for Long Context Retrieval
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li
0
0
Embedding models play a pivot role in modern NLP applications such as IR and RAG. While the context limit of LLMs has been pushed beyond 1 million tokens, embedding models are still confined to a narrow context window not exceeding 8k tokens, refrained from application scenarios requiring long inputs such as legal contracts. This paper explores context window extension of existing embedding models, pushing the limit to 32k without requiring additional training. First, we examine the performance of current embedding models for long context retrieval on our newly constructed LongEmbed benchmark. LongEmbed comprises two synthetic tasks and four carefully chosen real-world tasks, featuring documents of varying length and dispersed target information. Benchmarking results underscore huge room for improvement in these models. Based on this, comprehensive experiments show that training-free context window extension strategies like position interpolation can effectively extend the context window of existing embedding models by several folds, regardless of their original context being 512 or beyond 4k. Furthermore, for models employing absolute position encoding (APE), we show the possibility of further fine-tuning to harvest notable performance gains while strictly preserving original behavior for short inputs. For models using rotary position embedding (RoPE), significant enhancements are observed when employing RoPE-specific methods, such as NTK and SelfExtend, indicating RoPE's superiority over APE for context window extension. To facilitate future research, we release E5-Base-4k and E5-RoPE-Base, along with the LongEmbed benchmark.
4/26/2024