Exploring Transfer Learning in Medical Image Segmentation using Vision-Language Models

0
🔄
Sign in to get full access
Overview
- Medical image segmentation allows quantifying target structure size and shape, aiding in disease diagnosis, prognosis, surgery planning, and comprehension.
- Recent advancements in vision-language models (VLMs) have led to the development of vision-language segmentation models (VLSMs) that use language text as an additional input for segmentation tasks.
- VLSMs offer unique opportunities, such as open vocabulary segmentation and potentially more robust segmentation against out-of-distribution data.
- This study explores the transfer of VLSMs to 2D medical images, using carefully curated datasets and language prompts.
Plain English Explanation
Medical image segmentation is the process of identifying and outlining specific structures or regions within medical images, such as MRI or CT scans. This is important for various clinical applications, as it allows doctors to accurately measure the size and shape of target structures, which can aid in disease diagnosis, treatment planning, and understanding the condition of a patient.
Recent advancements in [object Object] have led to the development of [object Object]. These models use both visual information (from medical images) and language information (from text descriptions) to perform segmentation tasks. This combination of visual and language data opens up new possibilities, such as the ability to segment medical images using natural language descriptions, and the potential for more robust segmentation models that can handle a wider range of scenarios.
In this study, the researchers investigate the transfer of VLSMs to 2D medical images, using a diverse set of medical image datasets and carefully crafted language prompts. They aim to understand how well these models can be adapted from natural images to medical images, and how effectively they can utilize the additional language information to improve segmentation performance.
Technical Explanation
The researchers in this study explore the use of [object Object] for 2D medical image segmentation. VLSMs are a type of model that builds upon the recent advancements in [object Object] from the natural image-text domain.
The researchers curated a diverse set of 11 medical image datasets covering various modalities, such as MRI, CT, and X-ray. They then conducted a systematic study on transferring VLSMs to these medical images, using carefully crafted language prompts as additional inputs to the models.
Their findings indicate that although VLSMs can achieve competitive performance compared to image-only segmentation models after fine-tuning on limited medical image datasets, not all VLSMs effectively utilize the additional information from the language prompts. The image features tend to play a dominant role in the segmentation task.
However, the researchers observe that VLSMs exhibit enhanced performance when handling pooled datasets with diverse modalities, and they show potential for improved robustness to domain shifts compared to conventional segmentation models. This suggests that VLSMs could be valuable for handling the heterogeneity and variability often encountered in medical imaging data.
Despite these promising results, the researchers conclude that novel approaches are needed to enable VLSMs to better leverage the various auxiliary information available through language prompts in medical image segmentation tasks.
Critical Analysis
The researchers have conducted a comprehensive study on the transfer of [object Object] to 2D medical images, which is an underexplored area of research. Their findings provide valuable insights into the current capabilities and limitations of these models in the medical domain.
One notable limitation is that not all VLSMs were able to effectively utilize the additional language information to improve segmentation performance. The image features still played a dominant role, suggesting that the current approaches for integrating vision and language representations may not be optimal for medical image segmentation tasks.
Additionally, the researchers acknowledge that while VLSMs exhibit potential for improved robustness to domain shifts, further research is needed to fully realize the benefits of the joint vision-language representation in medical image segmentation. [object Object] may be required to enable VLSMs to better leverage the various auxiliary information available through language prompts.
It would also be interesting to explore the performance of VLSMs in [object Object] tasks, where the combination of visual and language information could be particularly valuable. The researchers' findings on the potential of VLSMs for [object Object] also merit further investigation, as this is a critical concern in medical imaging applications.
Overall, this study lays the foundation for future research on the [object Object], and highlights the need for continued advancements in the effective integration of visual and language representations for medical image analysis tasks.
Conclusion
This study explores the transfer of [object Object] to 2D medical images, building upon the recent advancements in [object Object] from the natural image-text domain.
The researchers' findings demonstrate that while VLSMs can achieve competitive performance in medical image segmentation tasks after fine-tuning, not all VLSMs are able to effectively leverage the additional information provided by language prompts. The image features tend to play a dominant role in the segmentation process.
However, the researchers also observe that VLSMs exhibit enhanced performance when handling pooled datasets with diverse modalities and show potential for improved robustness to domain shifts compared to conventional segmentation models. This suggests that VLSMs could be valuable for addressing the heterogeneity and variability often encountered in medical imaging data.
Overall, this study lays the groundwork for future research on the medical applications of [object Object], highlighting the need for continued advancements in the effective integration of visual and language representations for medical image analysis tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Exploring Transfer Learning in Medical Image Segmentation using Vision-Language Models
Kanchan Poudel, Manish Dhakal, Prasiddha Bhandari, Rabin Adhikari, Safal Thapaliya, Bishesh Khanal
Medical image segmentation allows quantifying target structure size and shape, aiding in disease diagnosis, prognosis, surgery planning, and comprehension.Building upon recent advancements in foundation Vision-Language Models (VLMs) from natural image-text pairs, several studies have proposed adapting them to Vision-Language Segmentation Models (VLSMs) that allow using language text as an additional input to segmentation models. Introducing auxiliary information via text with human-in-the-loop prompting during inference opens up unique opportunities, such as open vocabulary segmentation and potentially more robust segmentation models against out-of-distribution data. Although transfer learning from natural to medical images has been explored for image-only segmentation models, the joint representation of vision-language in segmentation problems remains underexplored. This study introduces the first systematic study on transferring VLSMs to 2D medical images, using carefully curated $11$ datasets encompassing diverse modalities and insightful language prompts and experiments. Our findings demonstrate that although VLSMs show competitive performance compared to image-only models for segmentation after finetuning in limited medical image datasets, not all VLSMs utilize the additional information from language prompts, with image features playing a dominant role. While VLSMs exhibit enhanced performance in handling pooled datasets with diverse modalities and show potential robustness to domain shifts compared to conventional segmentation models, our results suggest that novel approaches are required to enable VLSMs to leverage the various auxiliary information available through language prompts. The code and datasets are available at https://github.com/naamiinepal/medvlsm.
Read more6/21/2024

0
Disease-informed Adaptation of Vision-Language Models
Jiajin Zhang, Ge Wang, Mannudeep K. Kalra, Pingkun Yan
In medical image analysis, the expertise scarcity and the high cost of data annotation limits the development of large artificial intelligence models. This paper investigates the potential of transfer learning with pre-trained vision-language models (VLMs) in this domain. Currently, VLMs still struggle to transfer to the underrepresented diseases with minimal presence and new diseases entirely absent from the pretraining dataset. We argue that effective adaptation of VLMs hinges on the nuanced representation learning of disease concepts. By capitalizing on the joint visual-linguistic capabilities of VLMs, we introduce disease-informed contextual prompting in a novel disease prototype learning framework. This approach enables VLMs to grasp the concepts of new disease effectively and efficiently, even with limited data. Extensive experiments across multiple image modalities showcase notable enhancements in performance compared to existing techniques.
Read more5/27/2024
0
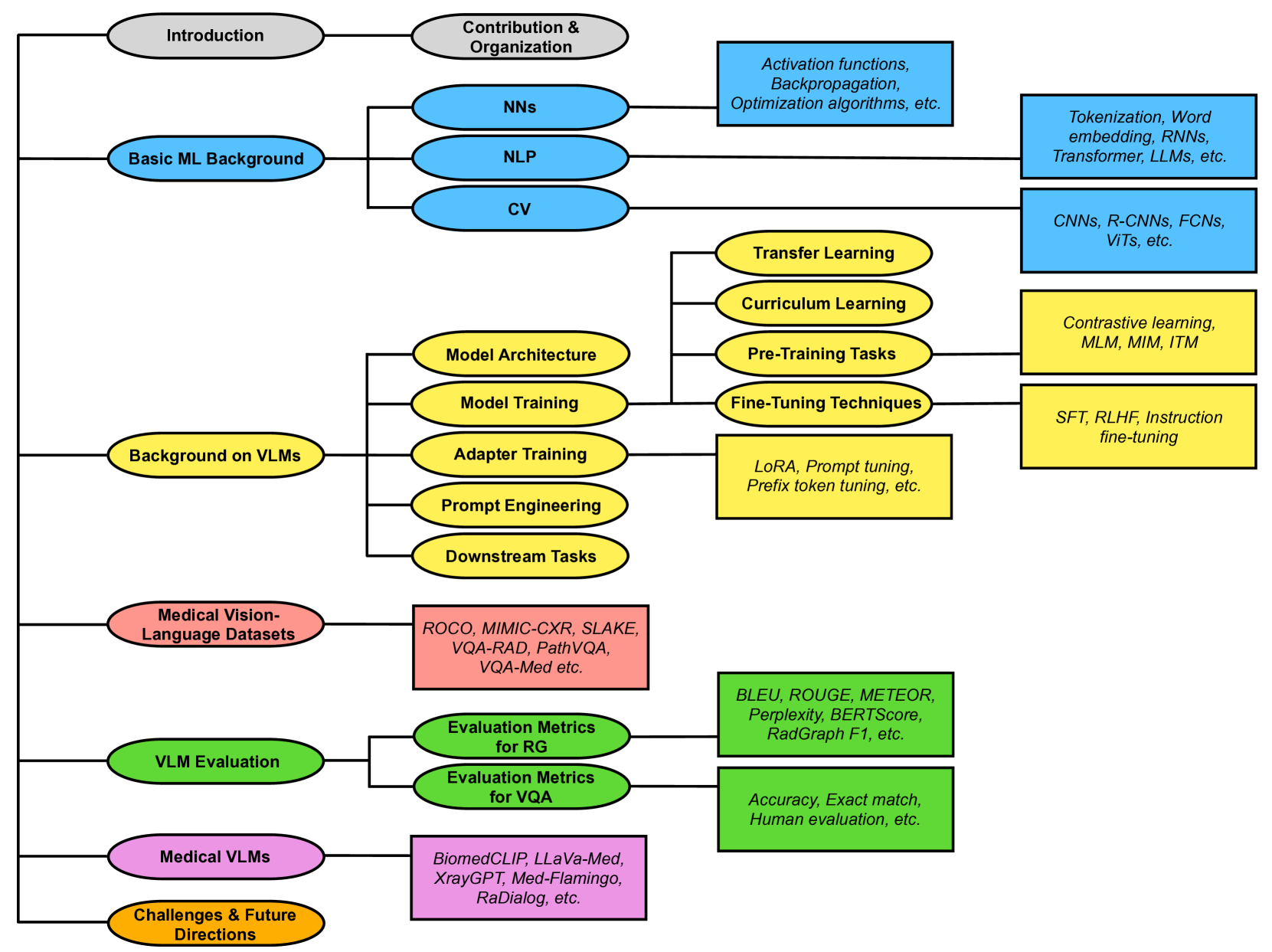
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
Read more4/16/2024
0
VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight Blocks
Manish Dhakal, Rabin Adhikari, Safal Thapaliya, Bishesh Khanal
Foundation Vision-Language Models (VLMs) trained using large-scale open-domain images and text pairs have recently been adapted to develop Vision-Language Segmentation Models (VLSMs) that allow providing text prompts during inference to guide image segmentation. If robust and powerful VLSMs can be built for medical images, it could aid medical professionals in many clinical tasks where they must spend substantial time delineating the target structure of interest. VLSMs for medical images resort to fine-tuning base VLM or VLSM pretrained on open-domain natural image datasets due to fewer annotated medical image datasets; this fine-tuning is resource-consuming and expensive as it usually requires updating all or a significant fraction of the pretrained parameters. Recently, lightweight blocks called adapters have been proposed in VLMs that keep the pretrained model frozen and only train adapters during fine-tuning, substantially reducing the computing resources required. We introduce a novel adapter, VLSM-Adapter, that can fine-tune pretrained vision-language segmentation models using transformer encoders. Our experiments in widely used CLIP-based segmentation models show that with only 3 million trainable parameters, the VLSM-Adapter outperforms state-of-the-art and is comparable to the upper bound end-to-end fine-tuning. The source code is available at: https://github.com/naamiinepal/vlsm-adapter.
Read more6/28/2024