Beyond Human Vision: The Role of Large Vision Language Models in Microscope Image Analysis

0
Sign in to get full access
Overview
- This paper explores the use of large vision language models (VLMs) in the analysis of microscope images, particularly in materials science and biology.
- The researchers investigate the capabilities of VLMs in tasks such as zero-shot evaluation, where models are asked to analyze images without any prior training.
- The paper provides insights into the potential of VLMs to augment and enhance human expertise in microscope image analysis, going "beyond human vision."
Plain English Explanation
Large vision language models are advanced AI systems that can understand and process both visual and textual information. In this paper, the researchers explore how these powerful models can be used to analyze microscope images, which are essential for studying materials science and biology.
Traditionally, microscope image analysis has relied heavily on human experts, who use their knowledge and experience to interpret the images. However, this process can be time-consuming and prone to human bias or error. The researchers investigate whether VLMs can supplement or even surpass human capabilities in this domain.
One key aspect they explore is zero-shot evaluation, where the models are asked to analyze images without any prior training. This is a challenging task, but the researchers find that VLMs can often perform surprisingly well, potentially going "beyond human vision" in their understanding of the microscope images.
The paper also discusses how VLMs could be used to generate synthetic data to augment existing datasets, or to assist human experts in their analysis by providing additional insights and interpretations.
Overall, the research suggests that large vision language models have the potential to revolutionize the field of microscope image analysis, making it more efficient, accurate, and accessible.
Technical Explanation
The paper investigates the use of large vision language models (VLMs) in the analysis of microscope images, particularly in the domains of materials science and biology. The researchers conduct a series of experiments to assess the capabilities of VLMs in tasks such as zero-shot evaluation, where the models are asked to analyze images without any prior training.
The experimental setup involves using several state-of-the-art VLMs, including CLIP and DALL-E, to perform various analysis tasks on a diverse set of microscope images. The researchers evaluate the models' performance on tasks such as material classification, object detection, and image captioning, and compare their results to those of human experts.
The findings suggest that VLMs can often outperform human experts in certain analysis tasks, particularly when it comes to zero-shot evaluation. The models demonstrate a remarkable ability to understand the visual information in the microscope images and generate accurate descriptions and interpretations, even without any prior training on the specific datasets.
The researchers also explore how VLMs could be used to generate synthetic data to augment existing datasets, or to assist human experts in their analysis by providing additional insights and interpretations.
Overall, the paper provides compelling evidence that large vision language models have the potential to revolutionize the field of microscope image analysis, offering a powerful complement to human expertise and potentially going "beyond human vision" in their understanding and interpretation of these important visual datasets.
Critical Analysis
The paper presents a compelling case for the use of large vision language models in microscope image analysis, but it also acknowledges several caveats and limitations. One key concern is the potential for bias and errors in the models' interpretations, particularly when dealing with complex or ambiguous microscope images.
While the researchers demonstrate the models' impressive zero-shot evaluation capabilities, it's important to note that these models are not infallible. They may struggle with rare or unusual image features, or make mistakes in their analysis due to the inherent biases in their training data or architecture.
Additionally, the paper does not delve deeply into the potential impact of these models on human experts in the field. While the researchers suggest that VLMs could be used to assist human experts, there is a risk that over-reliance on these models could lead to a deskilling of human analysts, potentially reducing their own expertise and decision-making abilities.
Further research is needed to explore the long-term implications of integrating VLMs into microscope image analysis workflows, and to ensure that these models are developed and deployed in a responsible and ethical manner.
Conclusion
This paper provides a compelling exploration of the potential for large vision language models to revolutionize the field of microscope image analysis, particularly in the domains of materials science and biology. The researchers demonstrate the impressive zero-shot evaluation capabilities of these models, suggesting that they may be able to go "beyond human vision" in their understanding and interpretation of complex microscope images.
The findings also suggest that VLMs could be used to generate synthetic data to augment existing datasets, or to assist human experts in their analysis by providing additional insights and interpretations.
While the research presents an exciting vision for the future of microscope image analysis, it also highlights the need for further exploration of the potential risks and limitations of these large vision language models. As these powerful AI systems become more integrated into scientific workflows, it will be crucial to ensure that they are developed and deployed in a responsible and ethical manner, preserving and enhancing human expertise rather than replacing it.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Human Vision: The Role of Large Vision Language Models in Microscope Image Analysis
Prateek Verma, Minh-Hao Van, Xintao Wu
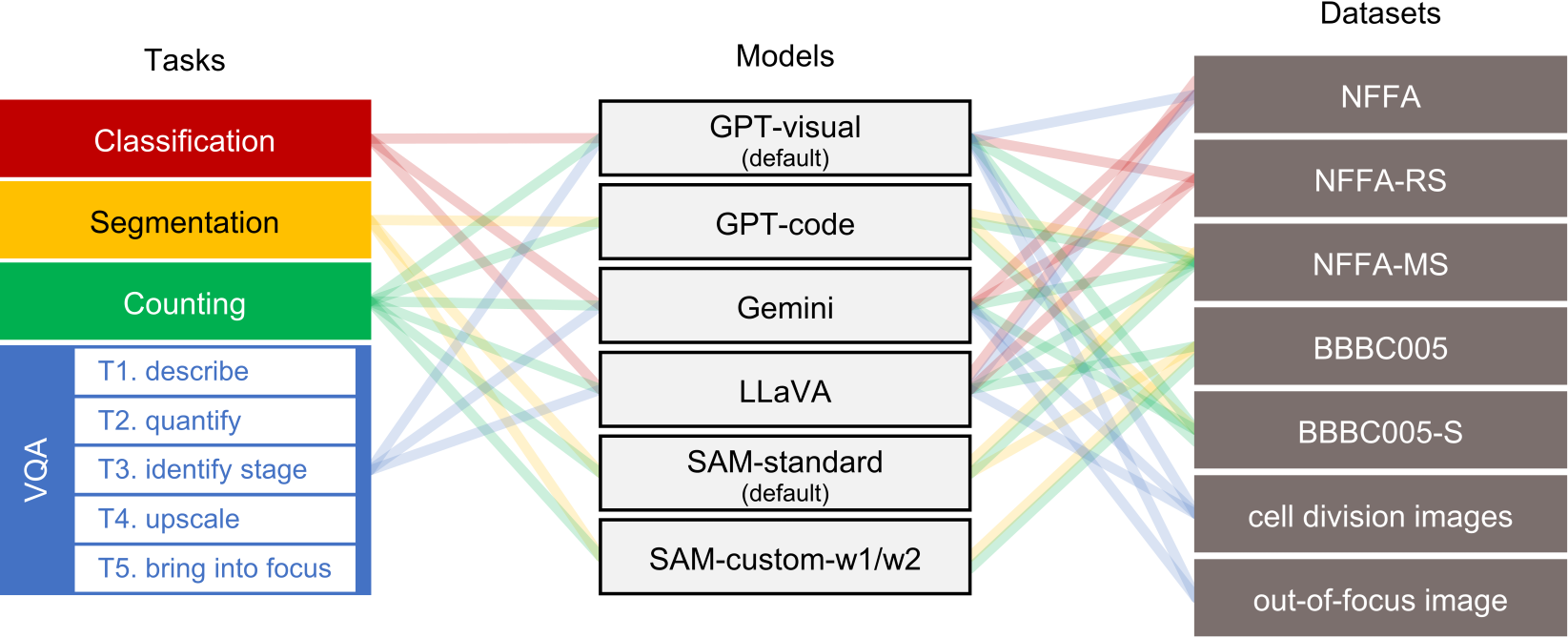
Vision language models (VLMs) have recently emerged and gained the spotlight for their ability to comprehend the dual modality of image and textual data. VLMs such as LLaVA, ChatGPT-4, and Gemini have recently shown impressive performance on tasks such as natural image captioning, visual question answering (VQA), and spatial reasoning. Additionally, a universal segmentation model by Meta AI, Segment Anything Model (SAM) shows unprecedented performance at isolating objects from unforeseen images. Since medical experts, biologists, and materials scientists routinely examine microscopy or medical images in conjunction with textual information in the form of captions, literature, or reports, and draw conclusions of great importance and merit, it is indubitably essential to test the performance of VLMs and foundation models such as SAM, on these images. In this study, we charge ChatGPT, LLaVA, Gemini, and SAM with classification, segmentation, counting, and VQA tasks on a variety of microscopy images. We observe that ChatGPT and Gemini are impressively able to comprehend the visual features in microscopy images, while SAM is quite capable at isolating artefacts in a general sense. However, the performance is not close to that of a domain expert - the models are readily encumbered by the introduction of impurities, defects, artefact overlaps and diversity present in the images.
Read more5/3/2024
0
Effectiveness Assessment of Recent Large Vision-Language Models
Yao Jiang, Xinyu Yan, Ge-Peng Ji, Keren Fu, Meijun Sun, Huan Xiong, Deng-Ping Fan, Fahad Shahbaz Khan
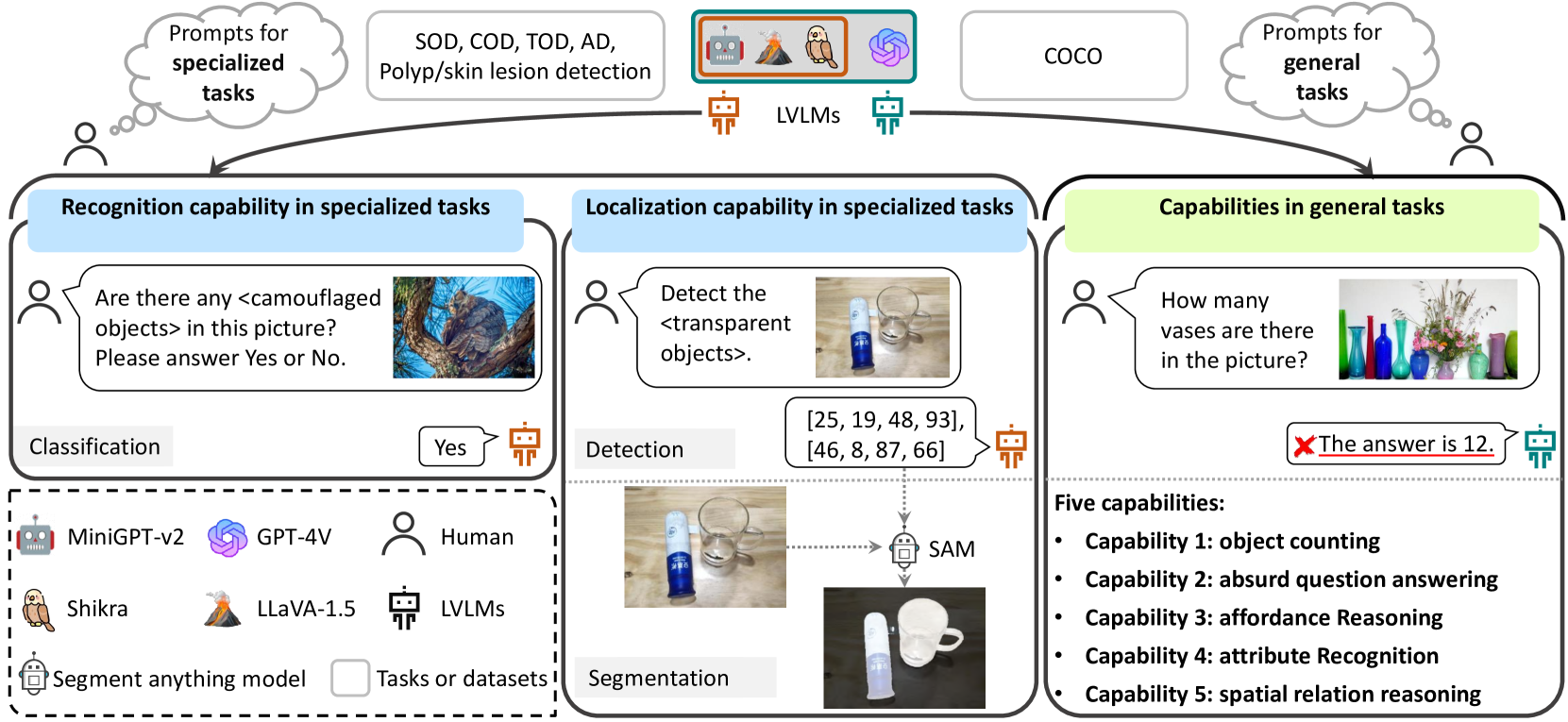
The advent of large vision-language models (LVLMs) represents a remarkable advance in the quest for artificial general intelligence. However, the model's effectiveness in both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their effectiveness in specialized tasks, we employ six challenging tasks in three different application scenarios: natural, healthcare, and industrial. These six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization in these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope that this study can provide useful insights for the future development of LVLMs, helping researchers improve LVLMs for both general and specialized applications.
Read more6/12/2024

2
Vision language models are blind
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, Anh Totti Nguyen
While large language models with vision capabilities (VLMs), e.g., GPT-4o and Gemini 1.5 Pro, are powering various image-text applications and scoring high on many vision-understanding benchmarks, we find that they are surprisingly still struggling with low-level vision tasks that are easy to humans. Specifically, on BlindTest, our suite of 7 very simple tasks such as identifying (a) whether two circles overlap; (b) whether two lines intersect; (c) which letter is being circled in a word; and (d) counting circles in an Olympic-like logo, four state-of-the-art VLMs are only 58.57% accurate on average. Claude 3.5 Sonnet performs the best at 74.94% accuracy, but this is still far from the human expected accuracy of 100%. Across different image resolutions and line widths, VLMs consistently struggle with tasks that require precise spatial information and recognizing geometric primitives that overlap or are close together. Code and data are available at: https://vlmsareblind.github.io
Read more7/29/2024

0
Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
Read more4/16/2024