Expressive and Generalizable Low-rank Adaptation for Large Models via Slow Cascaded Learning

0

Sign in to get full access
Overview
- This paper introduces a novel technique called "Slow Cascaded Learning" (SCL) for efficiently adapting large language models to specific tasks or domains.
- SCL builds on the LORA method, which learns low-rank adaptation modules to fine-tune large models while preserving their general capabilities.
- The key innovation of SCL is to gradually increase the rank of the adaptation modules over the course of training, allowing the model to progressively become more expressive and specialized without forgetting its original knowledge.
Plain English Explanation
The paper describes a new way to fine-tune large language models, like GPT-3 or BERT, to perform specific tasks or adapt to particular domains. The typical approach is to take the pre-trained model and fine-tune it on the target data, but this can cause the model to forget its original broad knowledge and capabilities.
The authors propose a technique called "Slow Cascaded Learning" (SCL) that aims to avoid this issue. The core idea is to start the fine-tuning process with a very simple adaptation of the model, using what's called a "low-rank" approach. This means only modifying a small part of the model's internal parameters, leaving the rest intact. Over time, the authors gradually increase the complexity of the adaptation, allowing the model to become more specialized without completely forgetting its original broad knowledge.
This stepwise approach is like teaching a person a new skill - you start with the basics, then slowly build up their expertise without them losing their existing capabilities. By taking things slow and cascading the learning, the model can become highly adept at the target task or domain while preserving its general intelligence.
The authors show that this SCL technique outperforms traditional fine-tuning methods on a variety of benchmarks, producing models that are both highly expressive and generalizable. This could be very useful for applications where you need to adapt a powerful language model to a specific use case without sacrificing its broad capabilities.
Technical Explanation
The paper builds on the LORA technique, which learns low-rank adaptation modules to fine-tune large language models. LORA modifies only a small subset of the model's parameters, allowing it to specialize without completely forgetting its original knowledge.
The key innovation of the current work is the "Slow Cascaded Learning" (SCL) approach. Instead of learning a single low-rank adaptation module, SCL gradually increases the rank of the adaptation over the course of training. This allows the model to progressively become more expressive and specialized, as captured in the LORA Learns Less, Forgets Less and ALORA works.
The authors demonstrate that SCL outperforms standard fine-tuning and other adaptation techniques on a range of benchmarks, including text classification, question answering, and language generation tasks. The gradual increase in adaptation complexity allows the model to become highly expressive while still preserving its original broad capabilities.
Critical Analysis
The paper provides a compelling approach to adapting large language models to specific tasks or domains. The authors acknowledge the potential computational limits of low-rank adaptation as the model size and task complexity grow, which could limit the scalability of the SCL technique.
Additionally, the paper does not explore the impact of the specific hyperparameters governing the rank increase over training. Further research could investigate the sensitivity of the method to these hyperparameters and provide guidance on how to best configure the cascading adaptation process.
Overall, the SCL technique presents a promising direction for efficient and effective adaptation of large language models. By carefully managing the complexity of the adaptation, the method can produce models that are highly specialized yet still retain their general intelligence and capabilities.
Conclusion
The "Slow Cascaded Learning" (SCL) approach introduced in this paper offers an effective way to fine-tune large language models for specific tasks or domains. By gradually increasing the complexity of the adaptation, SCL allows the model to become highly expressive and specialized without forgetting its original broad capabilities.
The authors demonstrate the effectiveness of SCL on a range of benchmarks, showing that it outperforms standard fine-tuning techniques. This could have important applications in areas where you need to adapt a powerful language model to a particular use case without sacrificing its general intelligence.
While the paper acknowledges potential scalability concerns, the SCL technique presents a promising direction for efficient and generalizable adaptation of large language models. Further research on the method's sensitivity to hyperparameters and its broader applicability could help unlock the full potential of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Expressive and Generalizable Low-rank Adaptation for Large Models via Slow Cascaded Learning
Siwei Li, Yifan Yang, Yifei Shen, Fangyun Wei, Zongqing Lu, Lili Qiu, Yuqing Yang
Efficient fine-tuning plays a fundamental role in modern large models, with low-rank adaptation emerging as a particularly promising approach. However, the existing variants of LoRA are hampered by limited expressiveness, a tendency to overfit, and sensitivity to hyperparameter settings. This paper presents LoRA Slow Cascade Learning (LoRASC), an innovative technique designed to enhance LoRA's expressiveness and generalization capabilities while preserving its training efficiency. Our approach augments expressiveness through a cascaded learning strategy that enables a mixture-of-low-rank adaptation, thereby increasing the model's ability to capture complex patterns. Additionally, we introduce a slow-fast update mechanism and cascading noisy tuning to bolster generalization. The extensive experiments on various language and vision datasets, as well as robustness benchmarks, demonstrate that the proposed method not only significantly outperforms existing baselines, but also mitigates overfitting, enhances model stability, and improves OOD robustness. Code will be release in https://github.com/microsoft/LoRASC very soon.
Read more7/2/2024

0
A Survey on LoRA of Large Language Models
Yuren Mao, Yuhang Ge, Yijiang Fan, Wenyi Xu, Yu Mi, Zhonghao Hu, Yunjun Gao
Low-Rank Adaptation~(LoRA), which updates the dense neural network layers with pluggable low-rank matrices, is one of the best performed parameter efficient fine-tuning paradigms. Furthermore, it has significant advantages in cross-task generalization and privacy-preserving. Hence, LoRA has gained much attention recently, and the number of related literature demonstrates exponential growth. It is necessary to conduct a comprehensive overview of the current progress on LoRA. This survey categorizes and reviews the progress from the perspectives of (1) downstream adaptation improving variants that improve LoRA's performance on downstream tasks; (2) cross-task generalization methods that mix multiple LoRA plugins to achieve cross-task generalization; (3) efficiency-improving methods that boost the computation-efficiency of LoRA; (4) data privacy-preserving methods that use LoRA in federated learning; (5) application. Besides, this survey also discusses the future directions in this field. At last, we provide a Github page~footnote{href{https://github.com/ZJU-LLMs/Awesome-LoRAs.git}{https://github.com/ZJU-LLMs/Awesome-LoRAs.git}} for readers to check the updates and initiate discussions on this survey paper.
Read more8/13/2024
📶
130
LoRA+: Efficient Low Rank Adaptation of Large Models
Soufiane Hayou, Nikhil Ghosh, Bin Yu
In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $%$ improvements) and finetuning speed (up to $sim$ 2X SpeedUp), at the same computational cost as LoRA.
Read more7/8/2024
0
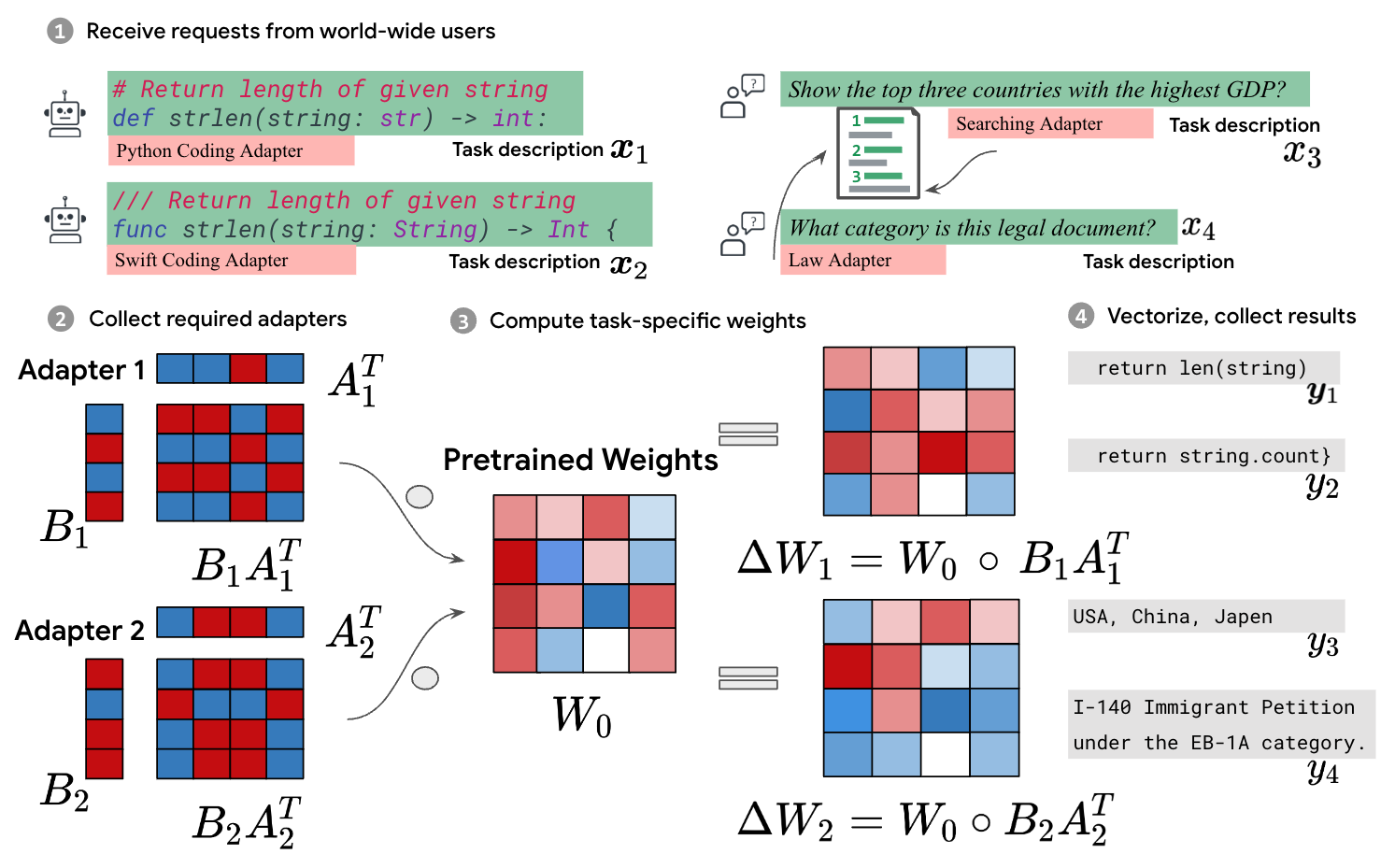
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Read more4/29/2024