Extending Segment Anything Model into Auditory and Temporal Dimensions for Audio-Visual Segmentation

0
📈
Sign in to get full access
Overview
- Audio-visual segmentation (AVS) aims to segment sound sources in video sequences, requiring understanding of audio-visual correspondence.
- The Segment Anything Model (SAM) has been explored for AVS, but its single-frame segmentation limits the use of temporal context across video frames.
- This paper proposes extending SAM's capabilities to audio-visual sequences by analyzing cross-modal relationships across frames.
Plain English Explanation
The goal of audio-visual segmentation (AVS) is to identify the different sound sources within a video, like separating the voice of a speaker from background music. This requires understanding how the audio and visual elements in the video are connected.
The Segment Anything Model (SAM) is a powerful AI tool that can segment objects in individual images. Some prior work has tried to use SAM for AVS by adding audio as an additional input. However, SAM is limited to processing one frame at a time, so it doesn't fully take advantage of the temporal information across multiple frames of a video.
To address this, the researchers in this paper developed a new module called Spatio-Temporal, Bidirectional Audio-Visual Attention (ST-BAVA) that can be integrated into SAM. This module allows SAM to better understand the relationship between the audio and visual elements as they change over time in the video sequence. By incorporating this temporal context, the model can segment sound sources more accurately, especially in complex scenes with multiple audio sources.
Technical Explanation
The key innovation in this paper is the Spatio-Temporal, Bidirectional Audio-Visual Attention (ST-BAVA) module, which is integrated into the middle of the Segment Anything Model's (SAM) image encoder and mask decoder.
This module adaptively updates the audio-visual features to convey the spatio-temporal correspondence between the video frames and audio streams. It does this by:
- Capturing the bidirectional relationships between the audio and visual features across multiple video frames.
- Modeling the temporal context to understand how the audio-visual correspondence evolves over time.
By incorporating this spatio-temporal, cross-modal attention mechanism, the model can better leverage the temporal information in the audio-visual data, going beyond SAM's single-frame segmentation approach.
The researchers extensively evaluated their proposed model on audio-visual segmentation benchmarks, showing it outperforms state-of-the-art methods, particularly with an 8.3% mIoU gain on a challenging multi-source subset.
Critical Analysis
The paper makes a compelling case for extending the Segment Anything Model (SAM) to handle audio-visual sequences, rather than just single image frames. The proposed ST-BAVA module is a sensible approach to capture the temporal and cross-modal relationships that are crucial for accurate audio-visual segmentation.
That said, the paper doesn't delve into potential limitations or future research directions. For example, it's unclear how the model would perform on even more complex audio-visual scenes, such as those with highly overlapping or rapidly changing sound sources. Additionally, the computational cost and inference speed of the ST-BAVA module are not discussed, which could be important considerations for real-world applications.
Further research could explore ways to make the model more robust and efficient, potentially by integrating techniques from other audio-visual segmentation approaches or leveraging unsupervised pretraining. The authors could also investigate how the model's performance varies across different types of audio-visual content or explore ways to improve the model's ability to handle multiple sound sources.
Conclusion
This paper presents a novel approach to extend the Segment Anything Model (SAM) for audio-visual segmentation by introducing a Spatio-Temporal, Bidirectional Audio-Visual Attention (ST-BAVA) module. This module allows the model to better understand the evolving relationship between audio and visual elements across video frames, leading to more accurate segmentation of sound sources, especially in challenging multi-source scenarios.
The proposed solution demonstrates the potential for adapting powerful image segmentation models like SAM to handle more complex, multi-modal data. As audio-visual understanding becomes increasingly important for applications like video analysis and human-computer interaction, this research represents a valuable step forward in the field of audio-visual segmentation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Extending Segment Anything Model into Auditory and Temporal Dimensions for Audio-Visual Segmentation
Juhyeong Seon, Woobin Im, Sebin Lee, Jumin Lee, Sung-Eui Yoon
Audio-visual segmentation (AVS) aims to segment sound sources in the video sequence, requiring a pixel-level understanding of audio-visual correspondence. As the Segment Anything Model (SAM) has strongly impacted extensive fields of dense prediction problems, prior works have investigated the introduction of SAM into AVS with audio as a new modality of the prompt. Nevertheless, constrained by SAM's single-frame segmentation scheme, the temporal context across multiple frames of audio-visual data remains insufficiently utilized. To this end, we study the extension of SAM's capabilities to the sequence of audio-visual scenes by analyzing contextual cross-modal relationships across the frames. To achieve this, we propose a Spatio-Temporal, Bidirectional Audio-Visual Attention (ST-BAVA) module integrated into the middle of SAM's image encoder and mask decoder. It adaptively updates the audio-visual features to convey the spatio-temporal correspondence between the video frames and audio streams. Extensive experiments demonstrate that our proposed model outperforms the state-of-the-art methods on AVS benchmarks, especially with an 8.3% mIoU gain on a challenging multi-sources subset.
Read more6/11/2024
0
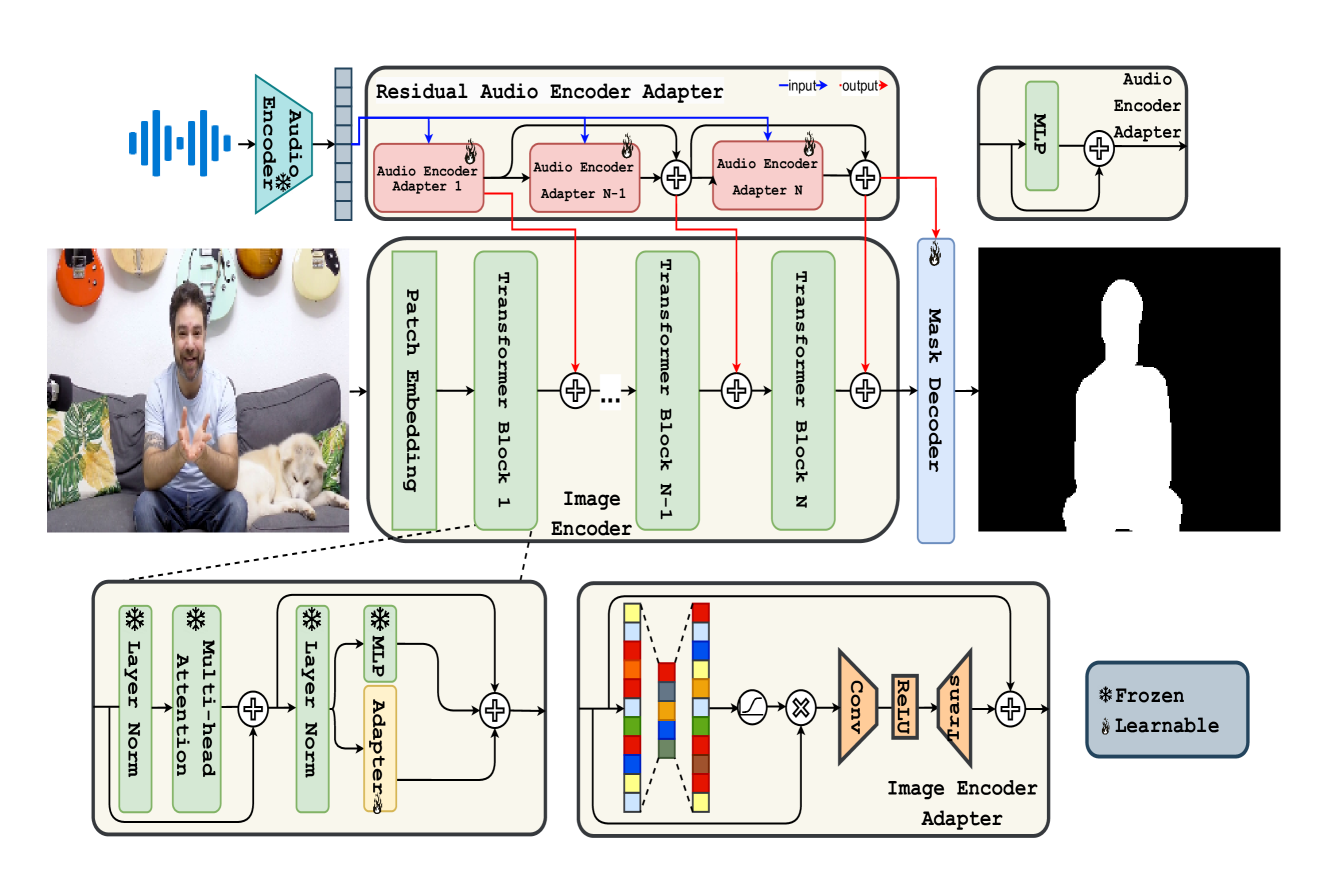
SAVE: Segment Audio-Visual Easy way using Segment Anything Model
Khanh-Binh Nguyen, Chae Jung Park
The primary aim of Audio-Visual Segmentation (AVS) is to precisely identify and locate auditory elements within visual scenes by accurately predicting segmentation masks at the pixel level. Achieving this involves comprehensively considering data and model aspects to address this task effectively. This study presents a lightweight approach, SAVE, which efficiently adapts the pre-trained segment anything model (SAM) to the AVS task. By incorporating an image encoder adapter into the transformer blocks to better capture the distinct dataset information and proposing a residual audio encoder adapter to encode the audio features as a sparse prompt, our proposed model achieves effective audio-visual fusion and interaction during the encoding stage. Our proposed method accelerates the training and inference speed by reducing the input resolution from 1024 to 256 pixels while achieving higher performance compared with the previous SOTA. Extensive experimentation validates our approach, demonstrating that our proposed model outperforms other SOTA methods significantly. Moreover, leveraging the pre-trained model on synthetic data enhances performance on real AVSBench data, achieving 84.59 mIoU on the S4 (V1S) subset and 70.28 mIoU on the MS3 (V1M) set with only 256 pixels for input images. This increases up to 86.16 mIoU on the S4 (V1S) and 70.83 mIoU on the MS3 (V1M) with inputs of 1024 pixels.
Read more7/8/2024

0
Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Zhaofeng Shi, Qingbo Wu, Fanman Meng, Linfeng Xu, Hongliang Li
Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask for application scenarios such as multi-modal video editing, augmented reality, and intelligent robot systems. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a Global semantic label in each sequence, but the video frame covers multiple semantic objects across different Local regions, which leads to mislocalization of the representationally similar but semantically different object. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-agnostic label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance. Code is available at https://github.com/ZhaofengSHI/AVS-C3N.
Read more7/18/2024

0
RefSAM: Efficiently Adapting Segmenting Anything Model for Referring Video Object Segmentation
Yonglin Li, Jing Zhang, Xiao Teng, Long Lan, Xinwang Liu
The Segment Anything Model (SAM) has gained significant attention for its impressive performance in image segmentation. However, it lacks proficiency in referring video object segmentation (RVOS) due to the need for precise user-interactive prompts and a limited understanding of different modalities, such as language and vision. This paper presents the RefSAM model, which explores the potential of SAM for RVOS by incorporating multi-view information from diverse modalities and successive frames at different timestamps in an online manner. Our proposed approach adapts the original SAM model to enhance cross-modality learning by employing a lightweight Cross-Modal MLP that projects the text embedding of the referring expression into sparse and dense embeddings, serving as user-interactive prompts. Additionally, we have introduced the hierarchical dense attention module to fuse hierarchical visual semantic information with sparse embeddings to obtain fine-grained dense embeddings, and an implicit tracking module to generate a tracking token and provide historical information for the mask decoder. Furthermore, we employ a parameter-efficient tuning strategy to align and fuse the language and vision features effectively. Through comprehensive ablation studies, we demonstrate our model's practical and effective design choices. Extensive experiments conducted on Refer-Youtube-VOS, Ref-DAVIS17, and three referring image segmentation datasets validate the superiority and effectiveness of our RefSAM model over existing methods.
Read more9/4/2024