QDFormer: Towards Robust Audiovisual Segmentation in Complex Environments with Quantization-based Semantic Decomposition

0

Sign in to get full access
Overview
- This paper proposes a novel approach to audiovisual segmentation that involves semantic quantization and decomposition.
- The method aims to improve upon traditional approaches by better capturing the semantic relationships between audio and visual information.
- Key innovations include the use of semantic quantization to encode audio-visual relationships and a decomposition module to separate semantic and low-level features.
Plain English Explanation
The paper introduces a new way to analyze and segment audiovisual data, such as videos. Traditional methods often struggle to fully capture the semantic connections between the audio (sound) and visual (image) components. This new approach tries to address that by semantically quantizing the audio-visual information, which means encoding the relationships between them in a more meaningful way.
It also includes a decomposition module that separates the data into two parts: the semantic features (the high-level meaning) and the low-level features (the raw details). This allows the system to better understand the underlying structure of the audiovisual content.
The goal is to create a more unified audio-visual perception that can more accurately segment and understand videos compared to existing techniques. This could have applications in areas like overcoming biases in audio-visual understanding or improving audio-visual source separation.
Technical Explanation
The key innovation in this paper is the introduction of semantic quantization and a decomposition module for audiovisual segmentation. Semantic quantization encodes the relationships between audio and visual features in a more meaningful way, going beyond simple low-level feature matching.
The decomposition module separates the input data into semantic and low-level features. The semantic features capture the high-level meaning and relationships, while the low-level features represent the raw details. This allows the system to better understand the underlying structure of the audiovisual content.
The authors design a neural network architecture that incorporates these two key components. They evaluate the approach on several audiovisual datasets and demonstrate improved performance compared to existing segmentation methods. The results suggest this new technique can more effectively capture the complex semantic connections between audio and visual information.
Critical Analysis
The paper presents a novel and promising approach to audiovisual segmentation. By incorporating semantic quantization and feature decomposition, the method aims to overcome limitations of traditional techniques that struggle to fully capture the semantic relationships between audio and visual data.
However, the paper does not extensively discuss potential limitations or areas for further research. For example, it is unclear how the approach would scale to large-scale, unconstrained audiovisual data, or how robust it would be to noisy or challenging inputs.
Additionally, the paper could have provided more analysis on the specific types of semantic relationships the method is able to encode, and how these relate to downstream tasks like video understanding or audio-visual source separation.
Overall, this work represents an interesting step forward in audiovisual segmentation, but further research is needed to fully understand the capabilities and limitations of the proposed approach.
Conclusion
This paper introduces a novel technique for audiovisual segmentation that incorporates semantic quantization and feature decomposition. By better capturing the semantic relationships between audio and visual data, the method aims to outperform traditional segmentation approaches.
The results demonstrate improved performance on several benchmark datasets, suggesting this new technique can more effectively model the complex interplay between audio and visual information. This could have important implications for a variety of applications, from overcoming biases in audio-visual understanding to improving audio-visual source separation.
While further research is needed to fully understand the capabilities and limitations of this approach, the paper presents an interesting and promising step forward in the field of audiovisual perception and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
QDFormer: Towards Robust Audiovisual Segmentation in Complex Environments with Quantization-based Semantic Decomposition
Xiang Li, Jinglu Wang, Xiaohao Xu, Xiulian Peng, Rita Singh, Yan Lu, Bhiksha Raj
Audiovisual segmentation (AVS) is a challenging task that aims to segment visual objects in videos according to their associated acoustic cues. With multiple sound sources and background disturbances involved, establishing robust correspondences between audio and visual contents poses unique challenges due to (1) complex entanglement across sound sources and (2) frequent changes in the occurrence of distinct sound events. Assuming sound events occur independently, the multi-source semantic space can be represented as the Cartesian product of single-source sub-spaces. We are motivated to decompose the multi-source audio semantics into single-source semantics for more effective interactions with visual content. We propose a semantic decomposition method based on product quantization, where the multi-source semantics can be decomposed and represented by several disentangled and noise-suppressed single-source semantics. Furthermore, we introduce a global-to-local quantization mechanism, which distills knowledge from stable global (clip-level) features into local (frame-level) ones, to handle frequent changes in audio semantics. Extensive experiments demonstrate that our semantically decomposed audio representation significantly improves AVS performance, e.g., +21.2% mIoU on the challenging AVS-Semantic benchmark with ResNet50 backbone. https://github.com/lxa9867/QSD.
Read more4/22/2024

0
Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Zhaofeng Shi, Qingbo Wu, Fanman Meng, Linfeng Xu, Hongliang Li
Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask for application scenarios such as multi-modal video editing, augmented reality, and intelligent robot systems. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a Global semantic label in each sequence, but the video frame covers multiple semantic objects across different Local regions, which leads to mislocalization of the representationally similar but semantically different object. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-agnostic label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance. Code is available at https://github.com/ZhaofengSHI/AVS-C3N.
Read more7/18/2024

0
Open-Vocabulary Audio-Visual Semantic Segmentation
Ruohao Guo, Liao Qu, Dantong Niu, Yanyu Qi, Wenzhen Yue, Ji Shi, Bowei Xing, Xianghua Ying
Audio-visual semantic segmentation (AVSS) aims to segment and classify sounding objects in videos with acoustic cues. However, most approaches operate on the close-set assumption and only identify pre-defined categories from training data, lacking the generalization ability to detect novel categories in practical applications. In this paper, we introduce a new task: open-vocabulary audio-visual semantic segmentation, extending AVSS task to open-world scenarios beyond the annotated label space. This is a more challenging task that requires recognizing all categories, even those that have never been seen nor heard during training. Moreover, we propose the first open-vocabulary AVSS framework, OV-AVSS, which mainly consists of two parts: 1) a universal sound source localization module to perform audio-visual fusion and locate all potential sounding objects and 2) an open-vocabulary classification module to predict categories with the help of the prior knowledge from large-scale pre-trained vision-language models. To properly evaluate the open-vocabulary AVSS, we split zero-shot training and testing subsets based on the AVSBench-semantic benchmark, namely AVSBench-OV. Extensive experiments demonstrate the strong segmentation and zero-shot generalization ability of our model on all categories. On the AVSBench-OV dataset, OV-AVSS achieves 55.43% mIoU on base categories and 29.14% mIoU on novel categories, exceeding the state-of-the-art zero-shot method by 41.88%/20.61% and open-vocabulary method by 10.2%/11.6%. The code is available at https://github.com/ruohaoguo/ovavss.
Read more8/1/2024
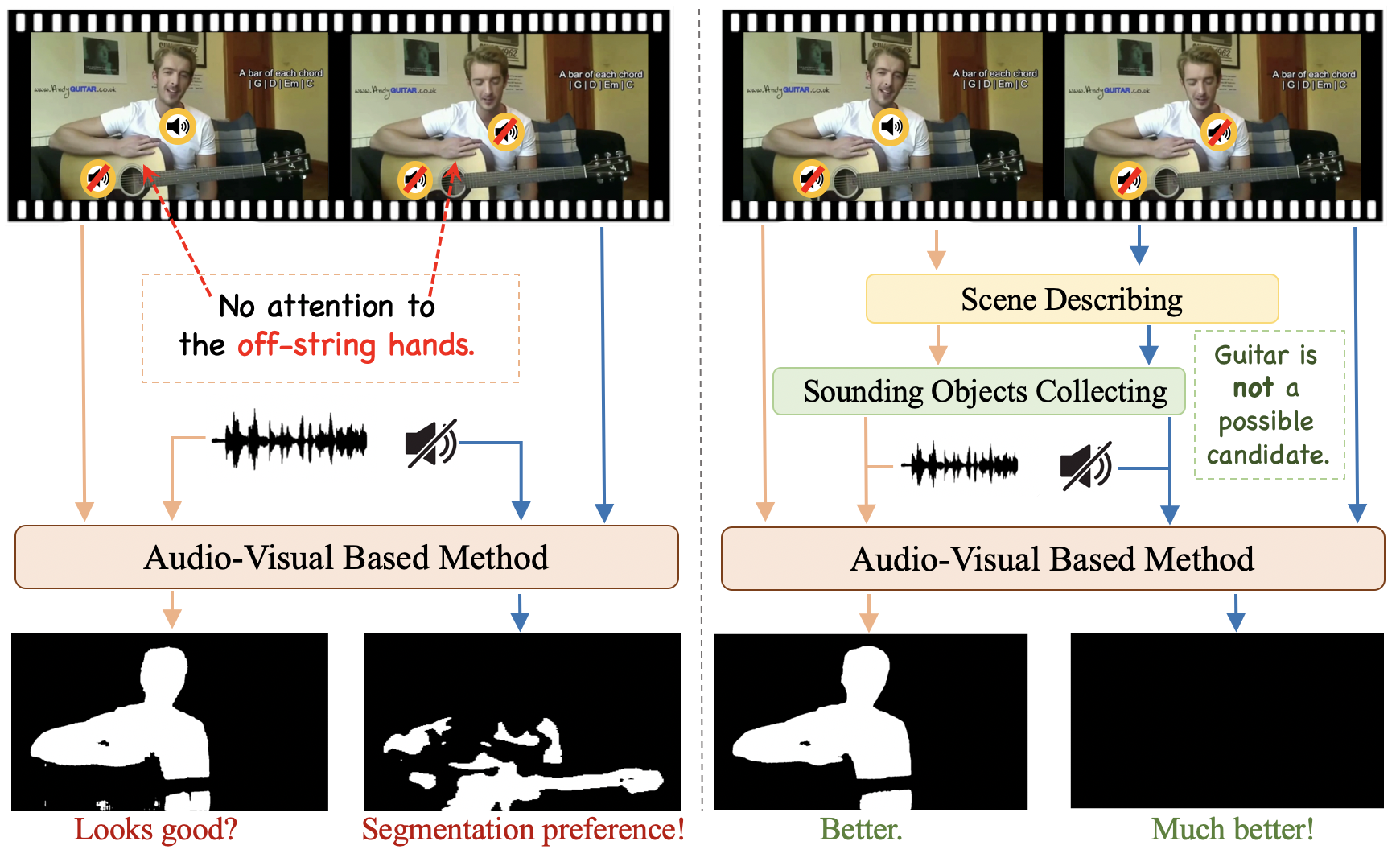
0
Can Textual Semantics Mitigate Sounding Object Segmentation Preference?
Yaoting Wang, Peiwen Sun, Yuanchao Li, Honggang Zhang, Di Hu
The Audio-Visual Segmentation (AVS) task aims to segment sounding objects in the visual space using audio cues. However, in this work, it is recognized that previous AVS methods show a heavy reliance on detrimental segmentation preferences related to audible objects, rather than precise audio guidance. We argue that the primary reason is that audio lacks robust semantics compared to vision, especially in multi-source sounding scenes, resulting in weak audio guidance over the visual space. Motivated by the the fact that text modality is well explored and contains rich abstract semantics, we propose leveraging text cues from the visual scene to enhance audio guidance with the semantics inherent in text. Our approach begins by obtaining scene descriptions through an off-the-shelf image captioner and prompting a frozen large language model to deduce potential sounding objects as text cues. Subsequently, we introduce a novel semantics-driven audio modeling module with a dynamic mask to integrate audio features with text cues, leading to representative sounding object features. These features not only encompass audio cues but also possess vivid semantics, providing clearer guidance in the visual space. Experimental results on AVS benchmarks validate that our method exhibits enhanced sensitivity to audio when aided by text cues, achieving highly competitive performance on all three subsets. Project page: href{https://github.com/GeWu-Lab/Sounding-Object-Segmentation-Preference}{https://github.com/GeWu-Lab/Sounding-Object-Segmentation-Preference}
Read more7/16/2024