Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual Segmentation

0
Sign in to get full access
Overview
- The paper explores the use of multi-order bilateral relations for audio-visual segmentation, demonstrating the importance of cooperation between different modalities.
- It proposes a novel audio-visual segmentation model that leverages both low-level and high-level cross-modal interactions to achieve improved performance.
- The model is evaluated on various audio-visual datasets, showcasing its effectiveness compared to state-of-the-art methods.
Plain English Explanation
The paper explores how using information from both audio and visual inputs can improve the process of segmenting objects or regions in a scene. It proposes a new model that takes advantage of the relationships between audio and visual data at different levels of detail, rather than just considering them separately.
For example, the low-level features of the audio (like frequency and volume) can be used to guide the analysis of the visual features (like edges and textures), and vice versa. And the high-level semantic information from both modalities can also be combined to better understand what's happening in the scene.
By capturing these multi-order bilateral relations between audio and visual data, the model is able to perform audio-visual segmentation more effectively than previous approaches that treated the modalities independently. The researchers evaluate their model on several standard benchmarks and show that it outperforms other state-of-the-art methods.
The key idea is that cooperation between different sensory inputs, like sight and sound, can lead to better understanding of a complex environment. This aligns with how humans and animals often use multiple senses together to perceive and interact with the world around them.
Technical Explanation
The paper introduces a novel audio-visual segmentation model that leverages multi-order bilateral relations between the audio and visual modalities. In contrast to prior work that treated the modalities independently, this model exploits both low-level and high-level cross-modal interactions to achieve improved performance.
At the low level, the model learns to align the audio and visual features, enabling the audio information to guide the segmentation of visual objects and vice versa. This is achieved through a multi-layer cross-attention fusion mechanism that dynamically integrates features from both modalities.
At the high level, the model learns to reason about the semantic relationships between audio and visual concepts, allowing it to better understand the overall context of the scene. This is accomplished by incorporating weakly supervised audio-visual learning techniques that leverage naturally occurring audio-visual correspondences.
The effectiveness of the proposed approach is demonstrated through extensive experiments on various audio-visual datasets, where it outperforms state-of-the-art methods like T-VSL and UNIAV. The results highlight the importance of modeling the rich multi-order bilateral relations between audio and visual data for improved audio-visual segmentation.
Critical Analysis
The paper presents a compelling approach for audio-visual segmentation, but there are a few potential limitations and areas for further research:
-
The model's performance may be dependent on the quality and diversity of the audio-visual training data, which can be challenging to acquire in large quantities for many real-world scenarios.
-
The paper does not provide a detailed analysis of the model's robustness to noisy or incomplete audio-visual inputs, which would be important for real-world deployment.
-
While the high-level semantic reasoning capabilities of the model are promising, the paper does not explore how these could be extended to support more complex audio-visual understanding tasks, such as joint multimodal transformer-based emotion recognition.
-
The computational complexity of the model, especially the multi-layer cross-attention fusion mechanism, may limit its applicability to resource-constrained environments, such as embedded systems or mobile devices.
Overall, the paper makes a valuable contribution to the field of audio-visual perception by demonstrating the benefits of modeling multi-order bilateral relations between modalities. Further research addressing the identified limitations could lead to even more robust and versatile audio-visual segmentation solutions.
Conclusion
The paper presents a novel audio-visual segmentation model that exploits the cooperation between audio and visual modalities at both low and high levels. By capturing multi-order bilateral relations, the model achieves state-of-the-art performance on various benchmarks, highlighting the importance of cross-modal interactions for understanding complex environments.
The research provides a promising direction for advancing audio-visual perception capabilities, with potential applications in areas such as robotics, augmented reality, and human-computer interaction. As the field continues to evolve, further exploration of the interplay between different sensory inputs and higher-level reasoning could lead to even more intelligent and adaptable systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual Segmentation
Qi Yang, Xing Nie, Tong Li, Pengfei Gao, Ying Guo, Cheng Zhen, Pengfei Yan, Shiming Xiang
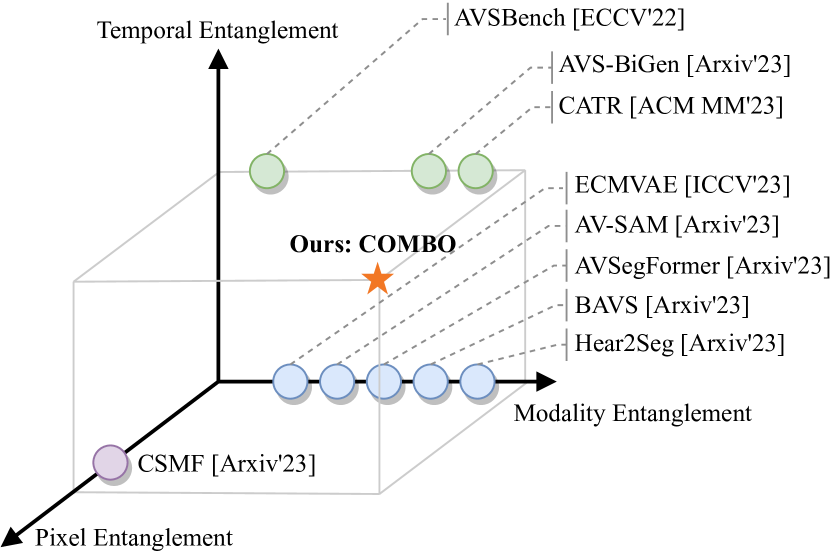
Recently, an audio-visual segmentation (AVS) task has been introduced, aiming to group pixels with sounding objects within a given video. This task necessitates a first-ever audio-driven pixel-level understanding of the scene, posing significant challenges. In this paper, we propose an innovative audio-visual transformer framework, termed COMBO, an acronym for COoperation of Multi-order Bilateral relatiOns. For the first time, our framework explores three types of bilateral entanglements within AVS: pixel entanglement, modality entanglement, and temporal entanglement. Regarding pixel entanglement, we employ a Siam-Encoder Module (SEM) that leverages prior knowledge to generate more precise visual features from the foundational model. For modality entanglement, we design a Bilateral-Fusion Module (BFM), enabling COMBO to align corresponding visual and auditory signals bi-directionally. As for temporal entanglement, we introduce an innovative adaptive inter-frame consistency loss according to the inherent rules of temporal. Comprehensive experiments and ablation studies on AVSBench-object (84.7 mIoU on S4, 59.2 mIou on MS3) and AVSBench-semantic (42.1 mIoU on AVSS) datasets demonstrate that COMBO surpasses previous state-of-the-art methods. Code and more results will be publicly available at https://yannqi.github.io/AVS-COMBO/.
Read more4/9/2024

0
Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Zhaofeng Shi, Qingbo Wu, Fanman Meng, Linfeng Xu, Hongliang Li
Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask for application scenarios such as multi-modal video editing, augmented reality, and intelligent robot systems. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a Global semantic label in each sequence, but the video frame covers multiple semantic objects across different Local regions, which leads to mislocalization of the representationally similar but semantically different object. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-agnostic label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance. Code is available at https://github.com/ZhaofengSHI/AVS-C3N.
Read more7/18/2024

0
MA-AVT: Modality Alignment for Parameter-Efficient Audio-Visual Transformers
Tanvir Mahmud, Shentong Mo, Yapeng Tian, Diana Marculescu
Recent advances in pre-trained vision transformers have shown promise in parameter-efficient audio-visual learning without audio pre-training. However, few studies have investigated effective methods for aligning multimodal features in parameter-efficient audio-visual transformers. In this paper, we propose MA-AVT, a new parameter-efficient audio-visual transformer employing deep modality alignment for corresponding multimodal semantic features. Specifically, we introduce joint unimodal and multimodal token learning for aligning the two modalities with a frozen modality-shared transformer. This allows the model to learn separate representations for each modality, while also attending to the cross-modal relationships between them. In addition, unlike prior work that only aligns coarse features from the output of unimodal encoders, we introduce blockwise contrastive learning to align coarse-to-fine-grain hierarchical features throughout the encoding phase. Furthermore, to suppress the background features in each modality from foreground matched audio-visual features, we introduce a robust discriminative foreground mining scheme. Through extensive experiments on benchmark AVE, VGGSound, and CREMA-D datasets, we achieve considerable performance improvements over SOTA methods.
Read more6/10/2024
📈
0
Extending Segment Anything Model into Auditory and Temporal Dimensions for Audio-Visual Segmentation
Juhyeong Seon, Woobin Im, Sebin Lee, Jumin Lee, Sung-Eui Yoon
Audio-visual segmentation (AVS) aims to segment sound sources in the video sequence, requiring a pixel-level understanding of audio-visual correspondence. As the Segment Anything Model (SAM) has strongly impacted extensive fields of dense prediction problems, prior works have investigated the introduction of SAM into AVS with audio as a new modality of the prompt. Nevertheless, constrained by SAM's single-frame segmentation scheme, the temporal context across multiple frames of audio-visual data remains insufficiently utilized. To this end, we study the extension of SAM's capabilities to the sequence of audio-visual scenes by analyzing contextual cross-modal relationships across the frames. To achieve this, we propose a Spatio-Temporal, Bidirectional Audio-Visual Attention (ST-BAVA) module integrated into the middle of SAM's image encoder and mask decoder. It adaptively updates the audio-visual features to convey the spatio-temporal correspondence between the video frames and audio streams. Extensive experiments demonstrate that our proposed model outperforms the state-of-the-art methods on AVS benchmarks, especially with an 8.3% mIoU gain on a challenging multi-sources subset.
Read more6/11/2024