F1tenth Autonomous Racing With Offline Reinforcement Learning Methods

0

Sign in to get full access
Overview
- This paper explores the use of offline reinforcement learning (RL) methods for autonomous racing in the F1TENTH competition.
- The researchers developed an end-to-end RL-based agent that can learn racing policies solely from expert demonstration data, without requiring any online interaction.
- The proposed approach was evaluated on a simulated F1TENTH racetrack and showed strong performance compared to baseline methods.
Plain English Explanation
The paper describes a new way to train autonomous cars to race around a track without needing to actually drive the car during the training process. Instead, the researchers used a technique called offline reinforcement learning that allows the car to learn from pre-recorded expert demonstrations of skilled human drivers.
The key idea is that the car can observe and learn from the actions of expert drivers, without having to explore the track itself and potentially make mistakes. This "offline" learning approach is more efficient and safer than the traditional "online" reinforcement learning, where the car would have to actively explore the track and learn from its own trial-and-error experiences.
The researchers evaluated their offline RL-based agent on a simulated version of the F1TENTH autonomous racing competition. They found that their approach was able to achieve strong racing performance, comparable to or even exceeding that of baseline methods that require online interaction with the environment.
Technical Explanation
The paper presents an offline RL-based approach for training autonomous racing agents in the F1TENTH competition. The key components of their method include:
-
Data Collection: The researchers collected a dataset of expert demonstrations by having skilled human drivers navigate the F1TENTH racetrack. This provided the training data for the offline RL agent.
-
RL Agent Architecture: The researchers developed an end-to-end RL agent that takes in sensory inputs (e.g., camera images, lidar scans) and outputs steering and throttle commands to control the vehicle. The agent was built using a deep neural network architecture.
-
Offline RL Training: Instead of training the agent through online interaction with the environment, the researchers used offline RL techniques to learn the racing policy solely from the expert demonstration data. This included using algorithms like behavior cloning and model-based RL.
-
Evaluation: The trained RL agent was evaluated on a simulated F1TENTH racetrack and its performance was compared to baseline methods, including those that require online interaction. The results showed that the offline RL agent was able to achieve strong racing performance, on par with or exceeding the baselines.
Critical Analysis
The paper presents an interesting and promising approach for training autonomous racing agents using offline RL methods. Some key strengths of the work include:
- Data Efficiency: By leveraging expert demonstration data, the RL agent can learn effective racing policies without the need for costly and potentially dangerous online exploration of the environment.
- Scalability: The offline RL approach could potentially scale to more complex racing environments or tasks, as long as the necessary expert demonstration data is available.
- Safety: Avoiding online exploration during training makes the approach more suitable for real-world deployment, where safety is a critical concern.
However, the paper also acknowledges some limitations and areas for further research:
- Generalization: It's unclear how well the trained RL agent would generalize to novel racetrack layouts or environmental conditions that were not present in the expert demonstration data.
- Exploration-Exploitation Trade-off: Offline RL methods may struggle to balance exploration and exploitation, as the agent is limited to the actions observed in the demonstration data.
- Robustness: The paper does not address potential issues with the RL agent's robustness to sensor noise, system failures, or other real-world challenges.
Future research could explore ways to address these limitations, such as incorporating techniques for learning from diverse demonstrations or enhancing the RL agent's ability to handle uncertainties and disturbances.
Conclusion
This paper presents a novel approach for training autonomous racing agents using offline reinforcement learning methods. By leveraging expert demonstration data, the researchers were able to develop an end-to-end RL agent that can achieve strong racing performance without the need for online exploration of the environment.
The offline RL approach offers several advantages, including data efficiency, scalability, and improved safety. While the paper acknowledges some limitations, the proposed method represents an important step towards more practical and deployable autonomous racing systems.
The findings of this research could have broader implications for the development of safe and reliable autonomous vehicles, as the offline RL techniques could potentially be applied to a wide range of robotic control tasks beyond just racing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
F1tenth Autonomous Racing With Offline Reinforcement Learning Methods
Prajwal Koirala, Cody Fleming
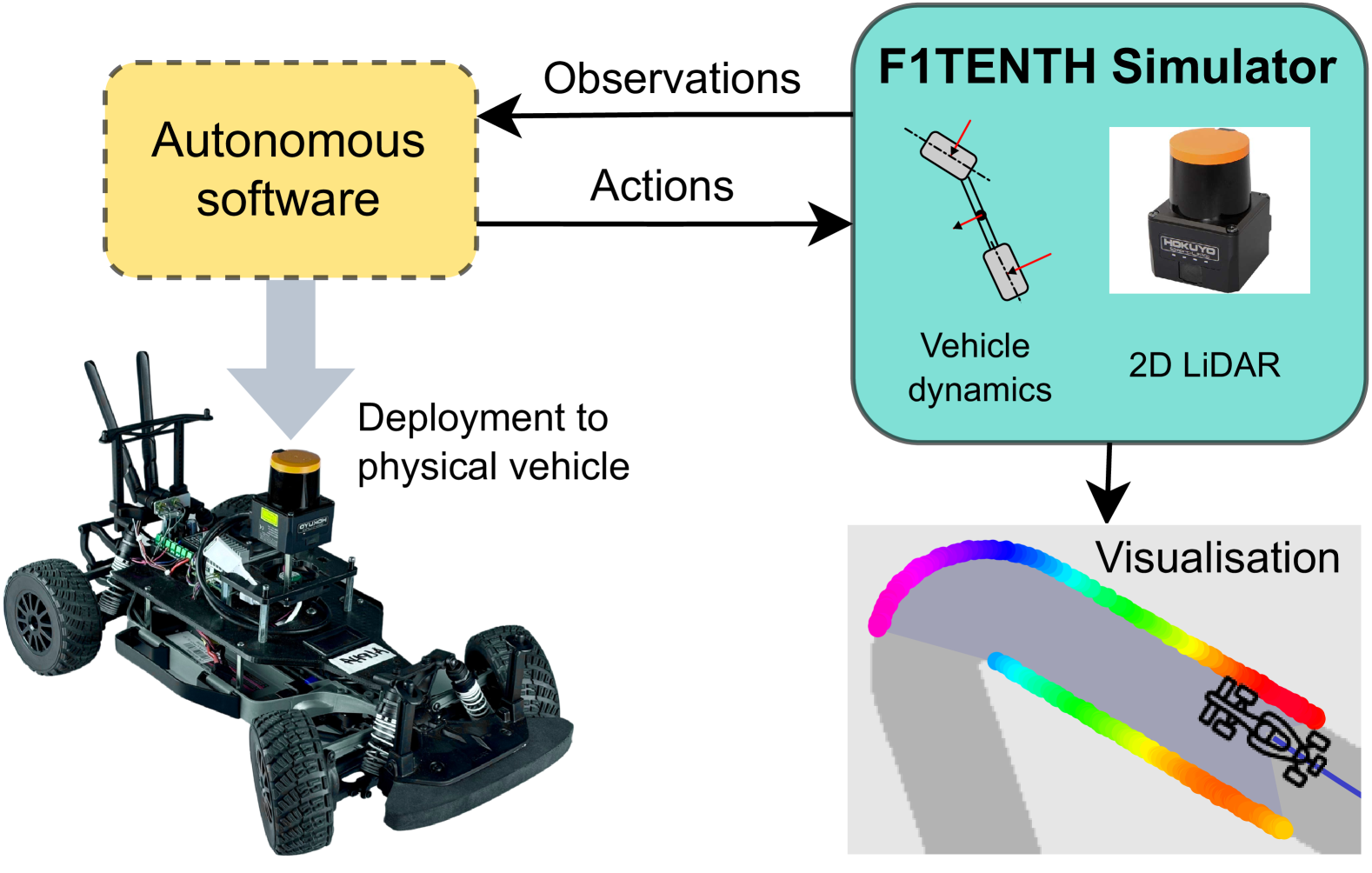
Autonomous racing serves as a critical platform for evaluating automated driving systems and enhancing vehicle mobility intelligence. This work investigates offline reinforcement learning methods to train agents within the dynamic F1tenth racing environment. The study begins by exploring the challenges of online training in the Austria race track environment, where agents consistently fail to complete the laps. Consequently, this research pivots towards an offline strategy, leveraging `expert' demonstration dataset to facilitate agent training. A waypoint-based suboptimal controller is developed to gather data with successful lap episodes. This data is then employed to train offline learning-based algorithms, with a subsequent analysis of the agents' cross-track performance, evaluating their zero-shot transferability from seen to unseen scenarios and their capacity to adapt to changes in environment dynamics. Beyond mere algorithm benchmarking in autonomous racing scenarios, this study also introduces and describes the machinery of our return-conditioned decision tree-based policy, comparing its performance with methods that employ fully connected neural networks, Transformers, and Diffusion Policies and highlighting some insights into method selection for training autonomous agents in driving interactions.
Read more8/9/2024
0
Unifying F1TENTH Autonomous Racing: Survey, Methods and Benchmarks
Benjamin David Evans, Raphael Trumpp, Marco Caccamo, Felix Jahncke, Johannes Betz, Hendrik Willem Jordaan, Herman Arnold Engelbrecht
The F1TENTH autonomous driving platform, consisting of 1:10-scale remote-controlled cars, has evolved into a well-established education and research platform. The many publications and real-world competitions span many domains, from classical path planning to novel learning-based algorithms. Consequently, the field is wide and disjointed, hindering direct comparison of developed methods and making it difficult to assess the state-of-the-art. Therefore, we aim to unify the field by surveying current approaches, describing common methods, and providing benchmark results to facilitate clear comparisons and establish a baseline for future work. This research aims to survey past and current work with F1TENTH vehicles in the classical and learning categories and explain the different solution approaches. We describe particle filter localisation, trajectory optimisation and tracking, model predictive contouring control, follow-the-gap, and end-to-end reinforcement learning. We provide an open-source evaluation of benchmark methods and investigate overlooked factors of control frequency and localisation accuracy for classical methods as well as reward signal and training map for learning methods. The evaluation shows that the optimisation and tracking method achieves the fastest lap times, followed by the online planning approach. Finally, our work identifies and outlines the relevant research aspects to help motivate future work in the F1TENTH domain.
Read more4/26/2024

0
A Benchmark Environment for Offline Reinforcement Learning in Racing Games
Girolamo Macaluso, Alessandro Sestini, Andrew D. Bagdanov
Offline Reinforcement Learning (ORL) is a promising approach to reduce the high sample complexity of traditional Reinforcement Learning (RL) by eliminating the need for continuous environmental interactions. ORL exploits a dataset of pre-collected transitions and thus expands the range of application of RL to tasks in which the excessive environment queries increase training time and decrease efficiency, such as in modern AAA games. This paper introduces OfflineMania a novel environment for ORL research. It is inspired by the iconic TrackMania series and developed using the Unity 3D game engine. The environment simulates a single-agent racing game in which the objective is to complete the track through optimal navigation. We provide a variety of datasets to assess ORL performance. These datasets, created from policies of varying ability and in different sizes, aim to offer a challenging testbed for algorithm development and evaluation. We further establish a set of baselines for a range of Online RL, ORL, and hybrid Offline to Online RL approaches using our environment.
Read more7/15/2024
🔍
0
Autonomous Algorithm for Training Autonomous Vehicles with Minimal Human Intervention
Sang-Hyun Lee, Daehyeok Kwon, Seung-Woo Seo
Reinforcement learning (RL) provides a compelling framework for enabling autonomous vehicles to continue to learn and improve diverse driving behaviors on their own. However, training real-world autonomous vehicles with current RL algorithms presents several challenges. One critical challenge, often overlooked in these algorithms, is the need to reset a driving environment between every episode. While resetting an environment after each episode is trivial in simulated settings, it demands significant human intervention in the real world. In this paper, we introduce a novel autonomous algorithm that allows off-the-shelf RL algorithms to train an autonomous vehicle with minimal human intervention. Our algorithm takes into account the learning progress of the autonomous vehicle to determine when to abort episodes before it enters unsafe states and where to reset it for subsequent episodes in order to gather informative transitions. The learning progress is estimated based on the novelty of both current and future states. We also take advantage of rule-based autonomous driving algorithms to safely reset an autonomous vehicle to an initial state. We evaluate our algorithm against baselines on diverse urban driving tasks. The experimental results show that our algorithm is task-agnostic and achieves better driving performance with fewer manual resets than baselines.
Read more5/24/2024