FABULA: Intelligence Report Generation Using Retrieval-Augmented Narrative Construction

0
🛸
Sign in to get full access
Overview
- The paper introduces a Retrieval Augmented Generation (RAG) approach to aid in the generation of intelligence reports.
- The proposed framework, called FABULA, allows analysts to query an Event Plot Graph (EPG) to retrieve relevant event plot points, which are then used to augment the prompting of a Large Language Model (LLM) during the report generation process.
- The evaluation studies show that the generated reports have high semantic relevance, coherency, and low data redundancy.
Plain English Explanation
The paper describes a system that helps analysts create more comprehensive intelligence reports by automating parts of the process. Generating these reports is often challenging because analysts need to integrate large amounts of constantly changing information, write detailed queries, and fill in missing data.
The Retrieval Augmented Generation (RAG) approach used in this system retrieves relevant information from a knowledge graph and incorporates it into the report generation process. Analysts can query an Event Plot Graph (EPG) to find key events and details, which are then used to guide a Large Language Model (LLM) in generating the final report.
The researchers found that the reports produced by this FABULA framework are highly relevant, coherent, and avoid redundant information, making them more useful for intelligence analysts.
Technical Explanation
The paper proposes a Retrieval Augmented Generation (RAG) approach to address the challenges of manual intelligence report generation. The key elements of the system include:
- Event Plot Graph (EPG): A knowledge graph that stores structured information about events, their relationships, and key details.
- Retrieval Module: Allows analysts to query the EPG and retrieve relevant event plot points to guide the report generation.
- Language Model: A Large Language Model (LLM) that generates the final intelligence report, with the retrieved event plot points used to augment the prompting.
The FABULA framework integrates these components to support the intelligence analysis workflow. Analysts can use FABULA to query the EPG, retrieve relevant event information, and then use this to prompt the LLM to generate a comprehensive report.
The researchers evaluated the FABULA system and found that the generated reports had high semantic relevance, coherency, and low data redundancy, indicating that the RAG approach effectively supports the intelligence report generation process.
Critical Analysis
The paper presents a promising approach to address the challenges of manual intelligence report generation. By leveraging a knowledge graph and a retrieval-augmented language model, the FABULA framework can help analysts produce more comprehensive and accurate reports.
However, the paper does not discuss the potential limitations or challenges in building and maintaining the Event Plot Graph (EPG). Ensuring the accuracy and completeness of the knowledge graph, as well as keeping it up-to-date with evolving events, could be an ongoing challenge.
Additionally, the paper does not explore the potential biases or inaccuracies that could arise from the language model's generation process, even with the retrieval-based augmentation. Further research may be needed to understand the model's limitations and ensure the reliability of the generated reports.
Lastly, the paper could have provided more details on the specific evaluation metrics and the comparison to alternative approaches, to better contextualize the performance of the FABULA system.
Conclusion
The paper introduces a novel Retrieval Augmented Generation (RAG) approach to support the generation of intelligence reports, a critical task for analysts. The proposed FABULA framework allows analysts to query an Event Plot Graph (EPG) and use the retrieved information to guide a Large Language Model (LLM) in generating the final report.
The evaluation results demonstrate the effectiveness of this approach, with the generated reports exhibiting high relevance, coherency, and low redundancy. This work represents an important step towards automating and enhancing the intelligence analysis process, potentially leading to more comprehensive and accurate reporting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
FABULA: Intelligence Report Generation Using Retrieval-Augmented Narrative Construction
Priyanka Ranade, Anupam Joshi
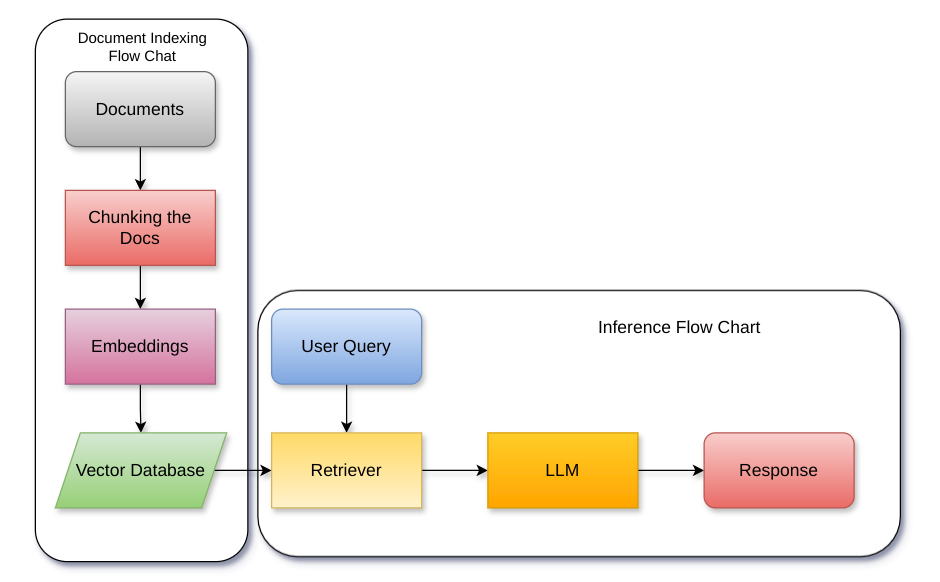
Narrative construction is the process of representing disparate event information into a logical plot structure that models an end to end story. Intelligence analysis is an example of a domain that can benefit tremendously from narrative construction techniques, particularly in aiding analysts during the largely manual and costly process of synthesizing event information into comprehensive intelligence reports. Manual intelligence report generation is often prone to challenges such as integrating dynamic event information, writing fine-grained queries, and closing information gaps. This motivates the development of a system that retrieves and represents critical aspects of events in a form that aids in automatic generation of intelligence reports. We introduce a Retrieval Augmented Generation (RAG) approach to augment prompting of an autoregressive decoder by retrieving structured information asserted in a knowledge graph to generate targeted information based on a narrative plot model. We apply our approach to the problem of neural intelligence report generation and introduce FABULA, framework to augment intelligence analysis workflows using RAG. An analyst can use FABULA to query an Event Plot Graph (EPG) to retrieve relevant event plot points, which can be used to augment prompting of a Large Language Model (LLM) during intelligence report generation. Our evaluation studies show that the plot points included in the generated intelligence reports have high semantic relevance, high coherency, and low data redundancy.
Read more6/4/2024
2
Context-augmented Retrieval: A Novel Framework for Fast Information Retrieval based Response Generation using Large Language Model
Sai Ganesh, Anupam Purwar, Gautam B
Generating high-quality answers consistently by providing contextual information embedded in the prompt passed to the Large Language Model (LLM) is dependent on the quality of information retrieval. As the corpus of contextual information grows, the answer/inference quality of Retrieval Augmented Generation (RAG) based Question Answering (QA) systems declines. This work solves this problem by combining classical text classification with the Large Language Model (LLM) to enable quick information retrieval from the vector store and ensure the relevancy of retrieved information. For the same, this work proposes a new approach Context Augmented retrieval (CAR), where partitioning of vector database by real-time classification of information flowing into the corpus is done. CAR demonstrates good quality answer generation along with significant reduction in information retrieval and answer generation time.
Read more8/1/2024

0
R^2AG: Incorporating Retrieval Information into Retrieval Augmented Generation
Fuda Ye, Shuangyin Li, Yongqi Zhang, Lei Chen
Retrieval augmented generation (RAG) has been applied in many scenarios to augment large language models (LLMs) with external documents provided by retrievers. However, a semantic gap exists between LLMs and retrievers due to differences in their training objectives and architectures. This misalignment forces LLMs to passively accept the documents provided by the retrievers, leading to incomprehension in the generation process, where the LLMs are burdened with the task of distinguishing these documents using their inherent knowledge. This paper proposes R$^2$AG, a novel enhanced RAG framework to fill this gap by incorporating Retrieval information into Retrieval Augmented Generation. Specifically, R$^2$AG utilizes the nuanced features from the retrievers and employs a R$^2$-Former to capture retrieval information. Then, a retrieval-aware prompting strategy is designed to integrate retrieval information into LLMs' generation. Notably, R$^2$AG suits low-source scenarios where LLMs and retrievers are frozen. Extensive experiments across five datasets validate the effectiveness, robustness, and efficiency of R$^2$AG. Our analysis reveals that retrieval information serves as an anchor to aid LLMs in the generation process, thereby filling the semantic gap.
Read more6/21/2024

0
Graph Retrieval-Augmented Generation: A Survey
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, Siliang Tang
Recently, Retrieval-Augmented Generation (RAG) has achieved remarkable success in addressing the challenges of Large Language Models (LLMs) without necessitating retraining. By referencing an external knowledge base, RAG refines LLM outputs, effectively mitigating issues such as ``hallucination'', lack of domain-specific knowledge, and outdated information. However, the complex structure of relationships among different entities in databases presents challenges for RAG systems. In response, GraphRAG leverages structural information across entities to enable more precise and comprehensive retrieval, capturing relational knowledge and facilitating more accurate, context-aware responses. Given the novelty and potential of GraphRAG, a systematic review of current technologies is imperative. This paper provides the first comprehensive overview of GraphRAG methodologies. We formalize the GraphRAG workflow, encompassing Graph-Based Indexing, Graph-Guided Retrieval, and Graph-Enhanced Generation. We then outline the core technologies and training methods at each stage. Additionally, we examine downstream tasks, application domains, evaluation methodologies, and industrial use cases of GraphRAG. Finally, we explore future research directions to inspire further inquiries and advance progress in the field. In order to track recent progress in this field, we set up a repository at url{https://github.com/pengboci/GraphRAG-Survey}.
Read more9/11/2024