FaceLift: Semi-supervised 3D Facial Landmark Localization

0

Sign in to get full access
Overview
- This research paper presents a semi-supervised approach called FaceLift for 3D facial landmark localization, which aims to accurately identify key points on a person's face in 3D space.
- The method leverages both labeled and unlabeled facial data to train a model, reducing the need for extensive manual labeling.
- FaceLift demonstrates improved performance compared to existing 3D facial landmark detection techniques, making it a promising approach for applications like face recognition, animation, and analysis.
Plain English Explanation
Facial landmark detection is the process of identifying important points on a person's face, like the corners of the eyes, tips of the nose, and edges of the mouth. This information is useful for a variety of applications, such as face recognition, facial animation, and facial analysis.
Traditional methods for 3D facial landmark detection often require extensive manual labeling of training data, which can be time-consuming and expensive. The FaceLift approach presented in this paper aims to address this issue by using a semi-supervised learning technique. This means the model can learn from both labeled facial data, where the landmarks are already identified, as well as unlabeled facial data, where the landmarks are not pre-determined.
By leveraging both types of data, FaceLift can achieve accurate 3D facial landmark detection while reducing the need for manual labeling. The researchers show that FaceLift outperforms existing 3D landmark detection methods, making it a promising tool for applications that rely on understanding the 3D structure of the human face.
Technical Explanation
The FaceLift method uses a semi-supervised learning approach to train a 3D facial landmark detection model. The model consists of a self-supervised representation learning component and a supervised 3D landmark prediction component.
The self-supervised representation learning component aims to extract meaningful features from both labeled and unlabeled facial data. This is achieved through a contrastive learning objective, where the model learns to distinguish between real and augmented facial images. The learned representations are then used as input to the supervised 3D landmark prediction component.
The supervised 3D landmark prediction component is a neural network that takes the learned facial representations and predicts the 3D coordinates of facial landmarks. This component is trained on the labeled facial data, which provides the ground truth landmark locations.
By combining these two components, FaceLift can leverage both labeled and unlabeled data to accurately predict the 3D locations of facial landmarks, outperforming existing 3D landmark detection methods on several benchmark datasets.
Critical Analysis
The FaceLift paper presents a promising approach for 3D facial landmark detection, but it also acknowledges some limitations and areas for further research.
One potential limitation is the reliance on the availability of labeled facial data for the supervised component of the model. While the semi-supervised approach reduces the need for extensive manual labeling, some labeled data is still required. Strategies for further reducing or even eliminating the need for labeled data could be an area for future investigation.
Additionally, the paper focuses on the task of 3D facial landmark detection, but the applicability of the FaceLift method to other facial analysis tasks, such as facial expression recognition or head pose estimation, is not explicitly explored. Exploring the broader applicability of the FaceLift approach could be a valuable avenue for future research.
Overall, the FaceLift paper presents a notable contribution to the field of 3D facial landmark detection, demonstrating the potential of semi-supervised learning techniques to improve the performance and efficiency of these types of models.
Conclusion
The FaceLift paper introduces a semi-supervised approach for 3D facial landmark localization that leverages both labeled and unlabeled facial data to train an accurate model. By reducing the need for extensive manual labeling, FaceLift offers a more efficient and cost-effective solution compared to traditional 3D landmark detection methods.
The results presented in the paper show that FaceLift outperforms existing 3D landmark detection techniques, making it a promising tool for applications that rely on understanding the 3D structure of the human face, such as face recognition, facial animation, and facial analysis. While the paper acknowledges some limitations, the semi-supervised approach demonstrated by FaceLift represents an important step forward in the field of 3D facial landmark localization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FaceLift: Semi-supervised 3D Facial Landmark Localization
David Ferman, Pablo Garrido, Gaurav Bharaj
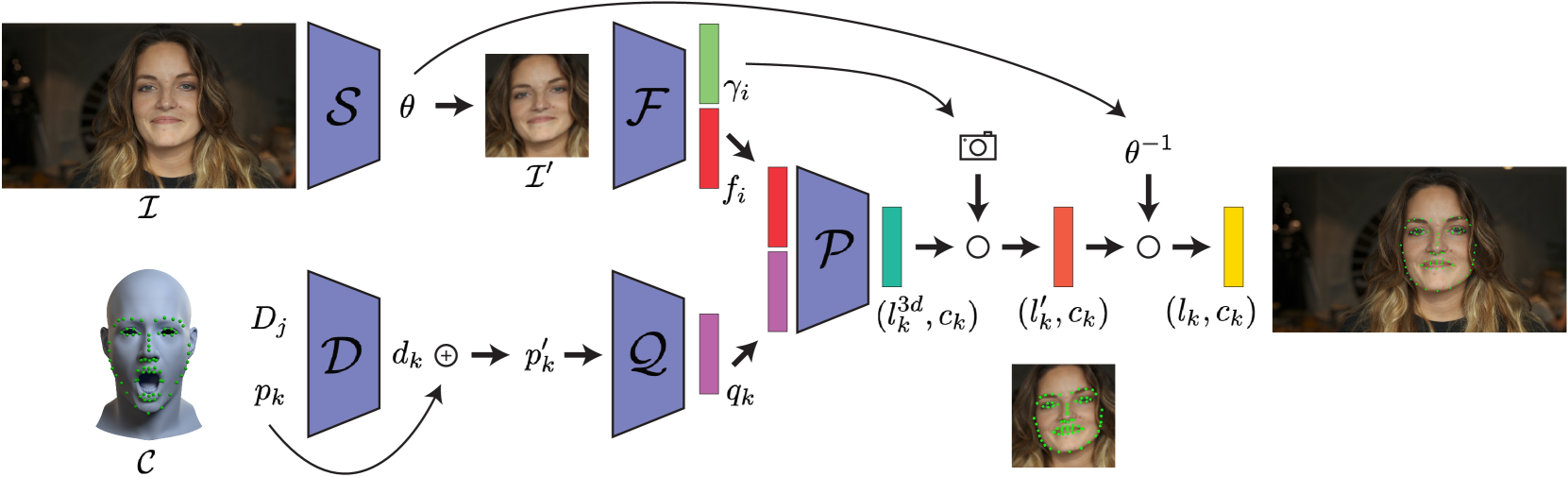
3D facial landmark localization has proven to be of particular use for applications, such as face tracking, 3D face modeling, and image-based 3D face reconstruction. In the supervised learning case, such methods usually rely on 3D landmark datasets derived from 3DMM-based registration that often lack spatial definition alignment, as compared with that chosen by hand-labeled human consensus, e.g., how are eyebrow landmarks defined? This creates a gap between landmark datasets generated via high-quality 2D human labels and 3DMMs, and it ultimately limits their effectiveness. To address this issue, we introduce a novel semi-supervised learning approach that learns 3D landmarks by directly lifting (visible) hand-labeled 2D landmarks and ensures better definition alignment, without the need for 3D landmark datasets. To lift 2D landmarks to 3D, we leverage 3D-aware GANs for better multi-view consistency learning and in-the-wild multi-frame videos for robust cross-generalization. Empirical experiments demonstrate that our method not only achieves better definition alignment between 2D-3D landmarks but also outperforms other supervised learning 3D landmark localization methods on both 3DMM labeled and photogrammetric ground truth evaluation datasets. Project Page: https://davidcferman.github.io/FaceLift
Read more5/31/2024
0
Infinite 3D Landmarks: Improving Continuous 2D Facial Landmark Detection
Prashanth Chandran, Gaspard Zoss, Paulo Gotardo, Derek Bradley
In this paper, we examine 3 important issues in the practical use of state-of-the-art facial landmark detectors and show how a combination of specific architectural modifications can directly improve their accuracy and temporal stability. First, many facial landmark detectors require face normalization as a preprocessing step, which is accomplished by a separately-trained neural network that crops and resizes the face in the input image. There is no guarantee that this pre-trained network performs the optimal face normalization for landmark detection. We instead analyze the use of a spatial transformer network that is trained alongside the landmark detector in an unsupervised manner, and jointly learn optimal face normalization and landmark detection. Second, we show that modifying the output head of the landmark predictor to infer landmarks in a canonical 3D space can further improve accuracy. To convert the predicted 3D landmarks into screen-space, we additionally predict the camera intrinsics and head pose from the input image. As a side benefit, this allows to predict the 3D face shape from a given image only using 2D landmarks as supervision, which is useful in determining landmark visibility among other things. Finally, when training a landmark detector on multiple datasets at the same time, annotation inconsistencies across datasets forces the network to produce a suboptimal average. We propose to add a semantic correction network to address this issue. This additional lightweight neural network is trained alongside the landmark detector, without requiring any additional supervision. While the insights of this paper can be applied to most common landmark detectors, we specifically target a recently-proposed continuous 2D landmark detector to demonstrate how each of our additions leads to meaningful improvements over the state-of-the-art on standard benchmarks.
Read more5/31/2024
0
3D-LFM: Lifting Foundation Model
Mosam Dabhi, Laszlo A. Jeni, Simon Lucey
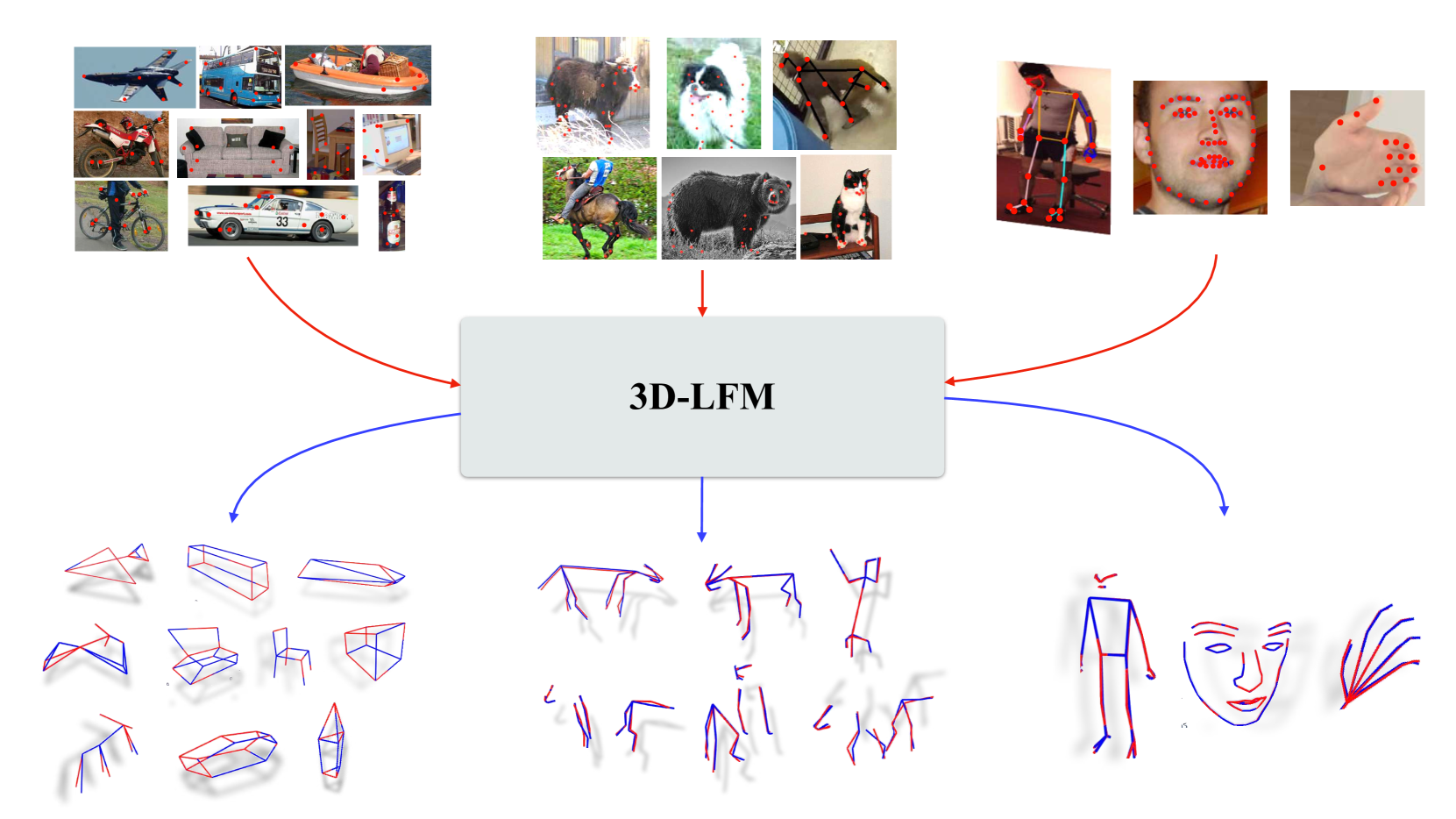
The lifting of 3D structure and camera from 2D landmarks is at the cornerstone of the entire discipline of computer vision. Traditional methods have been confined to specific rigid objects, such as those in Perspective-n-Point (PnP) problems, but deep learning has expanded our capability to reconstruct a wide range of object classes (e.g. C3DPO and PAUL) with resilience to noise, occlusions, and perspective distortions. All these techniques, however, have been limited by the fundamental need to establish correspondences across the 3D training data -- significantly limiting their utility to applications where one has an abundance of in-correspondence 3D data. Our approach harnesses the inherent permutation equivariance of transformers to manage varying number of points per 3D data instance, withstands occlusions, and generalizes to unseen categories. We demonstrate state of the art performance across 2D-3D lifting task benchmarks. Since our approach can be trained across such a broad class of structures we refer to it simply as a 3D Lifting Foundation Model (3D-LFM) -- the first of its kind.
Read more4/29/2024

0
Generalizable Face Landmarking Guided by Conditional Face Warping
Jiayi Liang, Haotian Liu, Hongteng Xu, Dixin Luo
As a significant step for human face modeling, editing, and generation, face landmarking aims at extracting facial keypoints from images. A generalizable face landmarker is required in practice because real-world facial images, e.g., the avatars in animations and games, are often stylized in various ways. However, achieving generalizable face landmarking is challenging due to the diversity of facial styles and the scarcity of labeled stylized faces. In this study, we propose a simple but effective paradigm to learn a generalizable face landmarker based on labeled real human faces and unlabeled stylized faces. Our method learns the face landmarker as the key module of a conditional face warper. Given a pair of real and stylized facial images, the conditional face warper predicts a warping field from the real face to the stylized one, in which the face landmarker predicts the ending points of the warping field and provides us with high-quality pseudo landmarks for the corresponding stylized facial images. Applying an alternating optimization strategy, we learn the face landmarker to minimize $i)$ the discrepancy between the stylized faces and the warped real ones and $ii)$ the prediction errors of both real and pseudo landmarks. Experiments on various datasets show that our method outperforms existing state-of-the-art domain adaptation methods in face landmarking tasks, leading to a face landmarker with better generalizability. Code is available at https://plustwo0.github.io/project-face-landmarker.
Read more4/23/2024