Infinite 3D Landmarks: Improving Continuous 2D Facial Landmark Detection

0
Sign in to get full access
Overview
- This paper presents a method for improving the accuracy and continuity of 2D facial landmark detection by leveraging 3D facial landmark information.
- The proposed approach, called "Infinite 3D Landmarks," utilizes a neural network to learn a continuous 2D-to-3D facial landmark mapping, which is then used to enhance 2D landmark predictions.
- The authors demonstrate that their method outperforms state-of-the-art 2D facial landmark detection techniques on several benchmark datasets.
Plain English Explanation
Facial landmark detection is an important task in computer vision, where the goal is to identify key points on a person's face, such as the corners of the eyes, the tip of the nose, and the edges of the mouth. These landmark points can be used for a variety of applications, such as facial recognition, emotion analysis, and virtual makeup.
The paper introduces a new method called "Infinite 3D Landmarks" that aims to improve the accuracy and continuity of 2D facial landmark detection. The key idea is to leverage information from 3D facial landmarks, which are more stable and informative than 2D landmarks. The authors train a neural network to learn a continuous mapping between 2D and 3D facial landmarks, and then use this mapping to enhance the predictions of a 2D landmark detection model.
By incorporating 3D information, the "Infinite 3D Landmarks" method is able to produce more accurate and consistent 2D landmark predictions, even in challenging scenarios such as large head poses or occlusions. The authors show that their approach outperforms state-of-the-art 2D facial landmark detection techniques on several benchmark datasets.
This research could have important implications for applications that rely on accurate facial landmark detection, such as facial recognition systems, emotion analysis tools, and augmented reality experiences. By improving the accuracy and continuity of 2D landmark predictions, the "Infinite 3D Landmarks" approach could help make these applications more robust and reliable.
Technical Explanation
The key technical innovation in this paper is the "Infinite 3D Landmarks" framework, which leverages 3D facial landmark information to enhance the performance of 2D facial landmark detection.
The authors start by training a neural network to learn a continuous mapping between 2D and 3D facial landmarks. This mapping is learned using a large dataset of facial images with corresponding 2D and 3D landmark annotations. The network is designed to be robust to variations in head pose, expression, and occlusion, which are common challenges in facial landmark detection.
Once the 2D-to-3D mapping is learned, the authors use it to improve the output of a 2D landmark detection model. Specifically, they feed the 2D landmark predictions from the 2D model into the 2D-to-3D mapping network, which then produces a set of corresponding 3D landmark predictions. These 3D landmarks are then projected back to 2D space, and the resulting 2D landmarks are used to refine the original 2D predictions.
The authors evaluate their "Infinite 3D Landmarks" approach on several benchmark datasets for 2D facial landmark detection, including 300-W, COFW, and WFLW. They show that their method outperforms state-of-the-art 2D landmark detection techniques in terms of both accuracy and continuity of the landmark predictions.
Critical Analysis
The "Infinite 3D Landmarks" approach presented in this paper is a promising step towards improving the performance of 2D facial landmark detection. By leveraging 3D facial landmark information, the authors are able to produce more accurate and consistent 2D landmark predictions, which can be valuable for a wide range of applications.
One potential limitation of the approach is the requirement of 3D landmark annotations for training the 2D-to-3D mapping network. While the authors use a large dataset of 3D-annotated facial images, collecting such data can be challenging and time-consuming. It would be interesting to see if the method could be extended to work with more readily available 2D landmark annotations, perhaps through semi-supervised or unsupervised learning techniques.
Additionally, the paper does not provide a detailed analysis of the computational complexity and runtime performance of the "Infinite 3D Landmarks" approach. As real-time facial landmark detection is often required in practical applications, it would be valuable to understand the tradeoffs between the improved accuracy and the additional computational overhead introduced by the 3D landmark mapping.
Overall, the "Infinite 3D Landmarks" method presented in this paper represents an important contribution to the field of facial landmark detection. The authors have demonstrated the potential benefits of leveraging 3D facial information to enhance 2D landmark predictions, and their work may inspire further research in this direction.
Conclusion
In this paper, the authors introduce a novel approach called "Infinite 3D Landmarks" that leverages 3D facial landmark information to improve the accuracy and continuity of 2D facial landmark detection. By training a neural network to learn a continuous mapping between 2D and 3D landmarks, the authors are able to refine the output of a 2D landmark detection model and produce more robust predictions.
The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing that "Infinite 3D Landmarks" outperforms state-of-the-art 2D landmark detection techniques. This research has important implications for applications that rely on accurate facial landmark detection, such as facial recognition, emotion analysis, and augmented reality.
While the current approach has some limitations, such as the requirement of 3D landmark annotations for training, the "Infinite 3D Landmarks" method represents an important step forward in the field of facial landmark detection. As the authors continue to refine and extend their work, it will be exciting to see how this technology could be further developed and deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Infinite 3D Landmarks: Improving Continuous 2D Facial Landmark Detection
Prashanth Chandran, Gaspard Zoss, Paulo Gotardo, Derek Bradley
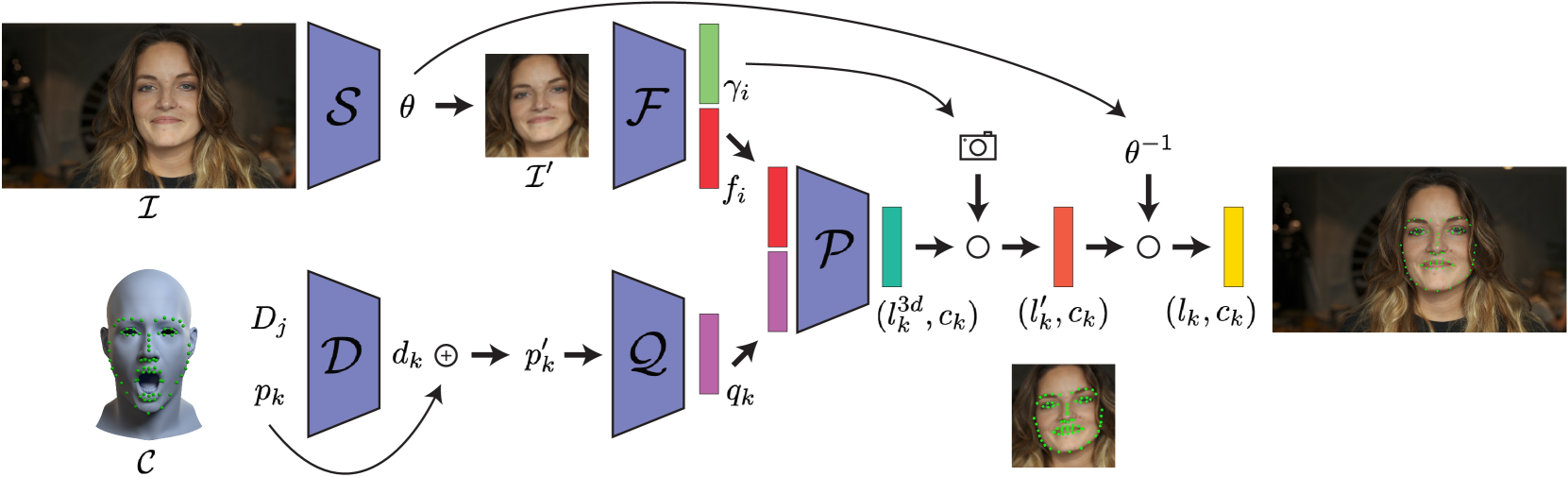
In this paper, we examine 3 important issues in the practical use of state-of-the-art facial landmark detectors and show how a combination of specific architectural modifications can directly improve their accuracy and temporal stability. First, many facial landmark detectors require face normalization as a preprocessing step, which is accomplished by a separately-trained neural network that crops and resizes the face in the input image. There is no guarantee that this pre-trained network performs the optimal face normalization for landmark detection. We instead analyze the use of a spatial transformer network that is trained alongside the landmark detector in an unsupervised manner, and jointly learn optimal face normalization and landmark detection. Second, we show that modifying the output head of the landmark predictor to infer landmarks in a canonical 3D space can further improve accuracy. To convert the predicted 3D landmarks into screen-space, we additionally predict the camera intrinsics and head pose from the input image. As a side benefit, this allows to predict the 3D face shape from a given image only using 2D landmarks as supervision, which is useful in determining landmark visibility among other things. Finally, when training a landmark detector on multiple datasets at the same time, annotation inconsistencies across datasets forces the network to produce a suboptimal average. We propose to add a semantic correction network to address this issue. This additional lightweight neural network is trained alongside the landmark detector, without requiring any additional supervision. While the insights of this paper can be applied to most common landmark detectors, we specifically target a recently-proposed continuous 2D landmark detector to demonstrate how each of our additions leads to meaningful improvements over the state-of-the-art on standard benchmarks.
Read more5/31/2024

0
FaceLift: Semi-supervised 3D Facial Landmark Localization
David Ferman, Pablo Garrido, Gaurav Bharaj
3D facial landmark localization has proven to be of particular use for applications, such as face tracking, 3D face modeling, and image-based 3D face reconstruction. In the supervised learning case, such methods usually rely on 3D landmark datasets derived from 3DMM-based registration that often lack spatial definition alignment, as compared with that chosen by hand-labeled human consensus, e.g., how are eyebrow landmarks defined? This creates a gap between landmark datasets generated via high-quality 2D human labels and 3DMMs, and it ultimately limits their effectiveness. To address this issue, we introduce a novel semi-supervised learning approach that learns 3D landmarks by directly lifting (visible) hand-labeled 2D landmarks and ensures better definition alignment, without the need for 3D landmark datasets. To lift 2D landmarks to 3D, we leverage 3D-aware GANs for better multi-view consistency learning and in-the-wild multi-frame videos for robust cross-generalization. Empirical experiments demonstrate that our method not only achieves better definition alignment between 2D-3D landmarks but also outperforms other supervised learning 3D landmark localization methods on both 3DMM labeled and photogrammetric ground truth evaluation datasets. Project Page: https://davidcferman.github.io/FaceLift
Read more5/31/2024

0
Improving Facial Landmark Detection Accuracy and Efficiency with Knowledge Distillation
Zong-Wei Hong, Yu-Chen Lin
The domain of computer vision has experienced significant advancements in facial-landmark detection, becoming increasingly essential across various applications such as augmented reality, facial recognition, and emotion analysis. Unlike object detection or semantic segmentation, which focus on identifying objects and outlining boundaries, faciallandmark detection aims to precisely locate and track critical facial features. However, deploying deep learning-based facial-landmark detection models on embedded systems with limited computational resources poses challenges due to the complexity of facial features, especially in dynamic settings. Additionally, ensuring robustness across diverse ethnicities and expressions presents further obstacles. Existing datasets often lack comprehensive representation of facial nuances, particularly within populations like those in Taiwan. This paper introduces a novel approach to address these challenges through the development of a knowledge distillation method. By transferring knowledge from larger models to smaller ones, we aim to create lightweight yet powerful deep learning models tailored specifically for facial-landmark detection tasks. Our goal is to design models capable of accurately locating facial landmarks under varying conditions, including diverse expressions, orientations, and lighting environments. The ultimate objective is to achieve high accuracy and real-time performance suitable for deployment on embedded systems. This method was successfully implemented and achieved a top 6th place finish out of 165 participants in the IEEE ICME 2024 PAIR competition.
Read more4/10/2024

0
Neural Localizer Fields for Continuous 3D Human Pose and Shape Estimation
Istv'an S'ar'andi, Gerard Pons-Moll
With the explosive growth of available training data, single-image 3D human modeling is ahead of a transition to a data-centric paradigm. A key to successfully exploiting data scale is to design flexible models that can be supervised from various heterogeneous data sources produced by different researchers or vendors. To this end, we propose a simple yet powerful paradigm for seamlessly unifying different human pose and shape-related tasks and datasets. Our formulation is centered on the ability - both at training and test time - to query any arbitrary point of the human volume, and obtain its estimated location in 3D. We achieve this by learning a continuous neural field of body point localizer functions, each of which is a differently parameterized 3D heatmap-based convolutional point localizer (detector). For generating parametric output, we propose an efficient post-processing step for fitting SMPL-family body models to nonparametric joint and vertex predictions. With this approach, we can naturally exploit differently annotated data sources including mesh, 2D/3D skeleton and dense pose, without having to convert between them, and thereby train large-scale 3D human mesh and skeleton estimation models that outperform the state-of-the-art on several public benchmarks including 3DPW, EMDB and SSP-3D by a considerable margin.
Read more7/11/2024