FaceMixup: Enhancing Facial Expression Recognition through Mixed Face Regularization

0
👁️
Sign in to get full access
Overview
- This paper explores techniques for adapting unimodal models to handle multimodal data, with a focus on facial expression recognition.
- The authors propose several novel methods, including MMA-DFER, MixCUTA, EMoTIC, and approaches for generating high-quality facial makeup data.
- The research aims to improve the performance and robustness of facial expression recognition models, particularly in dynamic and challenging real-world scenarios.
Plain English Explanation
The paper explores ways to adapt single-input (unimodal) machine learning models to work with multiple types of data (multimodal). The focus is on improving facial expression recognition, which is the task of using machine learning to identify the emotions expressed on a person's face.
The authors propose several new techniques to help unimodal models handle multimodal data more effectively. MMA-DFER is a method for dynamically adapting unimodal facial expression recognition models to work with additional data sources, like body pose or audio. MixCUTA is a data augmentation technique that combines multiple facial expressions to create new, more diverse training examples. EMoTIC is a model that uses a masked autoencoder and attention mechanisms to fuse information from different data modalities.
The paper also explores ways to generate high-quality facial makeup data, which can be challenging to obtain. This is important because makeup can significantly affect facial features and expressions, so models need to be trained on diverse data to perform well in the real world.
Overall, the research aims to make facial expression recognition systems more robust and effective, especially in complex, dynamic environments where people may be showing a variety of emotional expressions simultaneously.
Technical Explanation
The paper presents several novel techniques for adapting unimodal machine learning models to handle multimodal data, with a focus on facial expression recognition (FER).
MMA-DFER is a method for dynamically fusing unimodal FER models with additional data sources, such as body pose or audio information. The approach uses a gating mechanism to selectively incorporate the most relevant modalities at each step, allowing the model to adapt to changing conditions.
MixCUTA is a data augmentation technique for FER that combines multiple facial expressions to create new, more diverse training examples. By mixing different emotions, the method generates samples that better represent the complexity of real-world facial expressions.
The EMoTIC model uses a masked autoencoder and attention-based fusion to integrate information from multiple modalities, including visual, audio, and body pose data. The autoencoder learns a compact, multimodal representation, while the attention mechanism determines the relative importance of each input at different stages of the recognition process.
Additionally, the paper explores methods for generating high-quality facial makeup data, which can be challenging to obtain. Diverse makeup data is crucial for training robust FER models that can handle the variations in facial appearance caused by cosmetics.
The authors evaluate their proposed techniques on several FER benchmarks, demonstrating significant performance improvements over existing unimodal and multimodal approaches, especially in dynamic scenarios. The research aims to enhance the reliability and real-world applicability of facial expression recognition systems.
Critical Analysis
The paper makes valuable contributions to the field of facial expression recognition by proposing novel techniques for adapting unimodal models to handle multimodal data effectively. The authors acknowledge the limitations of their work, noting that the performance gains may be dataset-dependent and that further research is needed to fully understand the cross-dataset generalization capabilities of their methods.
One potential concern is the reliance on specific data modalities, such as body pose and audio information, which may not always be available in real-world scenarios. The authors could explore the robustness of their approaches to missing or noisy data from certain modalities.
Additionally, the paper does not provide a comprehensive comparison to state-of-the-art multimodal FER models, which could help contextualize the significance of the proposed methods. Incorporating such a comparison would strengthen the paper's claims and provide a clearer understanding of the advancements made.
Overall, the research presented in the paper represents a valuable step forward in improving the adaptability and robustness of facial expression recognition systems. The authors' willingness to acknowledge limitations and suggest future research directions is commendable and encourages further exploration in this important field.
Conclusion
This paper introduces several innovative techniques for enhancing the performance and versatility of facial expression recognition models by adapting unimodal approaches to handle multimodal data. The proposed methods, including MMA-DFER, MixCUTA, EMoTIC, and techniques for generating high-quality facial makeup data, demonstrate significant improvements in FER performance, especially in dynamic, real-world scenarios.
The researchers' focus on improving the adaptability and robustness of FER systems is particularly relevant as these technologies become more prevalent in various applications, from human-computer interaction to mental health monitoring. By expanding the capabilities of unimodal models to handle complex, multimodal data, the proposed methods have the potential to enhance the reliability and real-world applicability of facial expression recognition, ultimately benefiting both the research community and end-users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
FaceMixup: Enhancing Facial Expression Recognition through Mixed Face Regularization
Fabio A. Faria, Mateus M. Souza, Raoni F. da S. Teixeira, Mauricio P. Segundo
The proliferation of deep learning solutions and the scarcity of large annotated datasets pose significant challenges in real-world applications. Various strategies have been explored to overcome this challenge, with data augmentation (DA) approaches emerging as prominent solutions. DA approaches involve generating additional examples by transforming existing labeled data, thereby enriching the dataset and helping deep learning models achieve improved generalization without succumbing to overfitting. In real applications, where solutions based on deep learning are widely used, there is facial expression recognition (FER), which plays an essential role in human communication, improving a range of knowledge areas (e.g., medicine, security, and marketing). In this paper, we propose a simple and comprehensive face data augmentation approach based on mixed face component regularization that outperforms the classical DA approaches from the literature, including the MixAugment which is a specific approach for the target task in two well-known FER datasets existing in the literature.
Read more5/31/2024
0
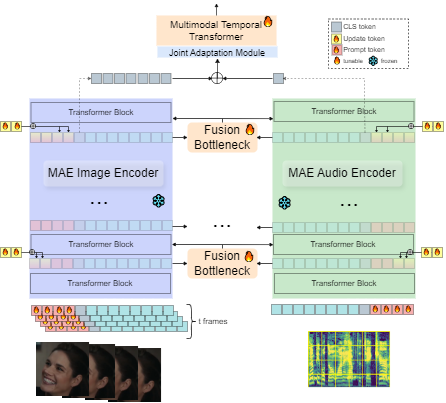
MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild
Kateryna Chumachenko, Alexandros Iosifidis, Moncef Gabbouj
Dynamic Facial Expression Recognition (DFER) has received significant interest in the recent years dictated by its pivotal role in enabling empathic and human-compatible technologies. Achieving robustness towards in-the-wild data in DFER is particularly important for real-world applications. One of the directions aimed at improving such models is multimodal emotion recognition based on audio and video data. Multimodal learning in DFER increases the model capabilities by leveraging richer, complementary data representations. Within the field of multimodal DFER, recent methods have focused on exploiting advances of self-supervised learning (SSL) for pre-training of strong multimodal encoders. Another line of research has focused on adapting pre-trained static models for DFER. In this work, we propose a different perspective on the problem and investigate the advancement of multimodal DFER performance by adapting SSL-pre-trained disjoint unimodal encoders. We identify main challenges associated with this task, namely, intra-modality adaptation, cross-modal alignment, and temporal adaptation, and propose solutions to each of them. As a result, we demonstrate improvement over current state-of-the-art on two popular DFER benchmarks, namely DFEW and MFAW.
Read more4/16/2024
0
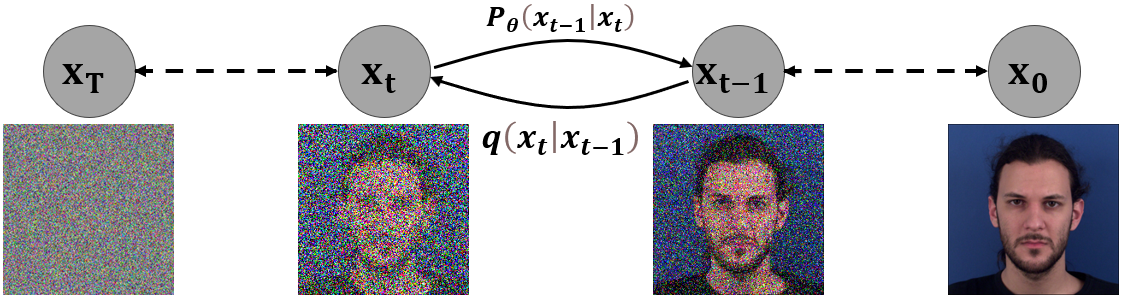
FacEnhance: Facial Expression Enhancing with Recurrent DDPMs
Hamza Bouzid, Lahoucine Ballihi
Facial expressions, vital in non-verbal human communication, have found applications in various computer vision fields like virtual reality, gaming, and emotional AI assistants. Despite advancements, many facial expression generation models encounter challenges such as low resolution (e.g., 32x32 or 64x64 pixels), poor quality, and the absence of background details. In this paper, we introduce FacEnhance, a novel diffusion-based approach addressing constraints in existing low-resolution facial expression generation models. FacEnhance enhances low-resolution facial expression videos (64x64 pixels) to higher resolutions (192x192 pixels), incorporating background details and improving overall quality. Leveraging conditional denoising within a diffusion framework, guided by a background-free low-resolution video and a single neutral expression high-resolution image, FacEnhance generates a video incorporating the facial expression from the low-resolution video performed by the individual with background from the neutral image. By complementing lightweight low-resolution models, FacEnhance strikes a balance between computational efficiency and desirable image resolution and quality. Extensive experiments on the MUG facial expression database demonstrate the efficacy of FacEnhance in enhancing low-resolution model outputs to state-of-the-art quality while preserving content and identity consistency. FacEnhance represents significant progress towards resource-efficient, high-fidelity facial expression generation, Renewing outdated low-resolution methods to up-to-date standards.
Read more6/14/2024

0
MixCut:A Data Augmentation Method for Facial Expression Recognition
Jiaxiang Yu, Yiyang Liu, Ruiyang Fan, Guobing Sun
In the facial expression recognition task, researchers always get low accuracy of expression classification due to a small amount of training samples. In order to solve this kind of problem, we proposes a new data augmentation method named MixCut. In this method, we firstly interpolate the two original training samples at the pixel level in a random ratio to generate new samples. Then, pixel removal is performed in random square regions on the new samples to generate the final training samples. We evaluated the MixCut method on Fer2013Plus and RAF-DB. With MixCut, we achieved 85.63% accuracy in eight-label classification on Fer2013Plus and 87.88% accuracy in seven-label classification on RAF-DB, effectively improving the classification accuracy of facial expression image recognition. Meanwhile, on Fer2013Plus, MixCut achieved performance improvements of +0.59%, +0.36%, and +0.39% compared to the other three data augmentation methods: CutOut, Mixup, and CutMix, respectively. MixCut improves classification accuracy on RAF-DB by +0.22%, +0.65%, and +0.5% over these three data augmentation methods.
Read more5/20/2024