Toward Tiny and High-quality Facial Makeup with Data Amplify Learning

0

Sign in to get full access
Overview
- This paper presents a novel approach for generating high-quality facial makeup images using a tiny model and a data amplification learning technique.
- The proposed method aims to produce natural-looking makeup results while keeping the model size small, making it suitable for deployment on resource-constrained devices.
- The key contributions include a data amplification learning strategy to enhance the model's performance and a compact network architecture that achieves state-of-the-art results in facial makeup generation.
Plain English Explanation
The researchers have developed a new way to create realistic-looking facial makeup images using a small-sized machine learning model. Typically, generating high-quality makeup results requires large and complex models, which can be challenging to deploy on devices with limited resources, such as smartphones.
To address this, the researchers have proposed a data amplification learning technique that helps the model learn more effectively from the available training data. This allows them to build a compact network architecture that can produce state-of-the-art facial makeup results while keeping the model size small.
The small model size makes it suitable for deployment on resource-constrained devices, such as mobile phones, which is an important consideration for real-world applications. By leveraging data amplification and a compact design, the researchers have found a way to generate high-quality facial makeup images without requiring a large and complex model.
Technical Explanation
The paper proposes a novel approach for generating high-quality facial makeup images using a diffusion-based image-to-image translation technique and a data amplification learning strategy.
The key elements of the proposed method include:
- Data Amplification Learning: The researchers introduce a data amplification technique that generates diverse training samples by applying various makeup styles to the input faces. This helps the model learn more effectively from the available data, leading to enhanced performance.
- Compact Network Architecture: The researchers design a compact network architecture that is capable of producing state-of-the-art facial makeup results while maintaining a small model size. This makes the model suitable for deployment on resource-constrained devices.
- Diffusion-based Makeup Generation: The proposed approach uses a diffusion-based image-to-image translation framework to generate the final makeup results. This allows for the production of high-quality, natural-looking makeup images.
The experiments and evaluations conducted in the paper demonstrate the effectiveness of the proposed method in generating realistic and high-quality facial makeup while maintaining a compact model size.
Critical Analysis
The paper presents a promising approach for generating high-quality facial makeup images with a small model size. However, some potential limitations and areas for further research are worth considering:
- Generalization to Diverse Skin Tones: The paper does not explicitly address the model's performance on a wide range of skin tones. Further evaluation and potential adaptations may be needed to ensure the method works well for diverse populations.
- Impact of Data Amplification: While the data amplification technique is reported to enhance the model's performance, the extent of its contribution and potential trade-offs, such as computational overhead, could be explored in more detail.
- Real-world Deployment Considerations: The paper focuses on the technical aspects of the model, but practical deployment challenges, such as integration with existing makeup applications or user preferences, may warrant further investigation.
Overall, the proposed approach represents a valuable contribution to the field of facial makeup generation, demonstrating the potential for developing high-quality models that can be efficiently deployed on resource-constrained devices. Addressing the aforementioned limitations and further exploring the practical implications of this research could lead to even more impactful advancements in this area.
Conclusion
This paper presents a novel method for generating high-quality facial makeup images using a compact model and a data amplification learning strategy. By leveraging a diffusion-based image-to-image translation framework and a compact network architecture, the researchers have developed a solution that can produce natural-looking makeup results while keeping the model size small.
The key innovations, including the data amplification technique and the compact network design, enable the model to achieve state-of-the-art performance in facial makeup generation. This makes the proposed approach suitable for deployment on resource-constrained devices, opening up possibilities for integrating advanced makeup generation capabilities in a wide range of real-world applications, such as mobile apps and augmented reality platforms.
The critical analysis highlights areas for further exploration, such as ensuring generalization to diverse skin tones and addressing practical deployment challenges. Addressing these aspects could lead to even more impactful advancements in the field of facial makeup generation, ultimately benefiting end-users and expanding the potential applications of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Toward Tiny and High-quality Facial Makeup with Data Amplify Learning
Qiaoqiao Jin, Xuanhong Chen, Meiguang Jin, Ying Chen, Rui Shi, Yucheng Zheng, Yupeng Zhu, Bingbing Ni
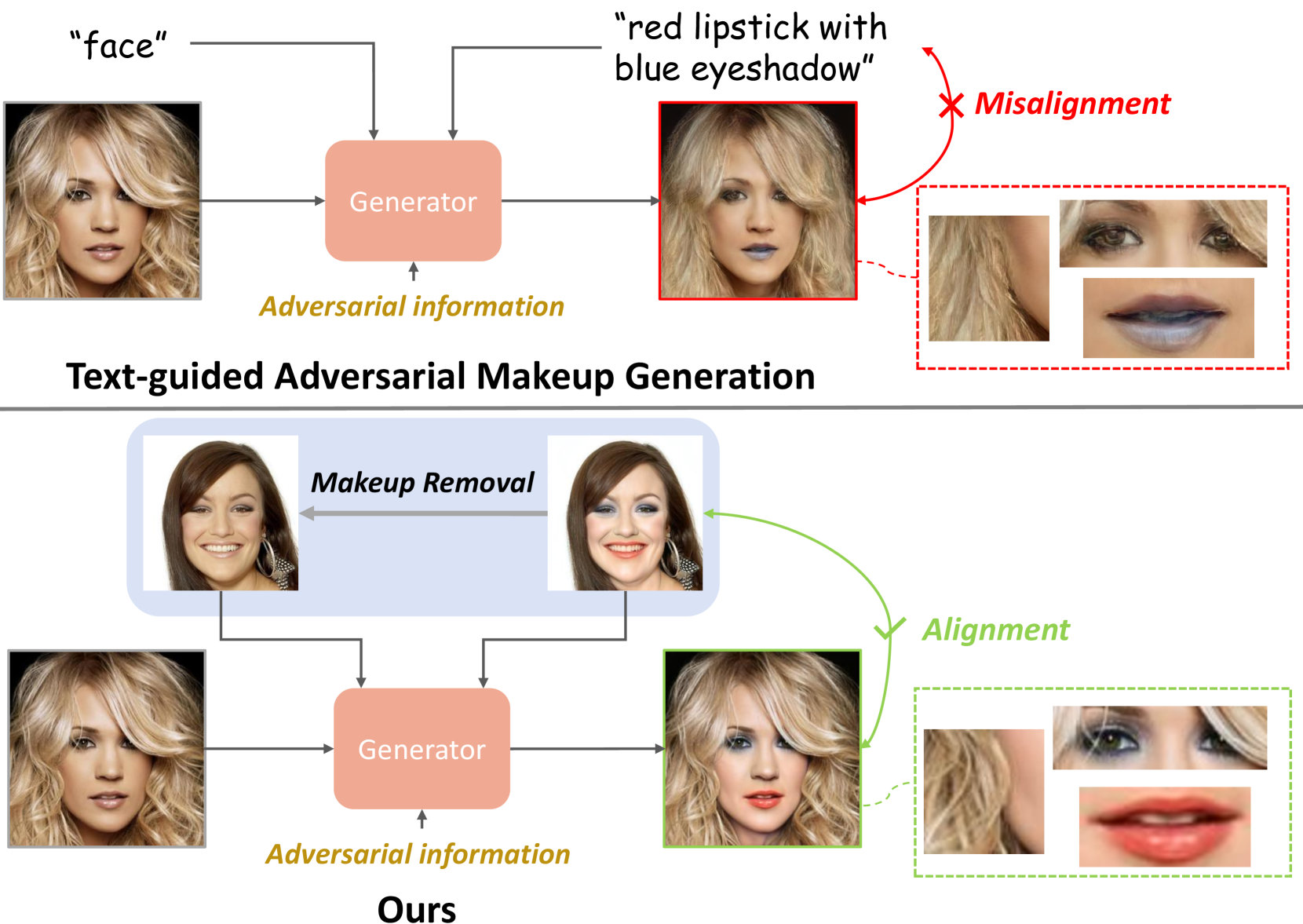
Contemporary makeup approaches primarily hinge on unpaired learning paradigms, yet they grapple with the challenges of inaccurate supervision (e.g., face misalignment) and sophisticated facial prompts (including face parsing, and landmark detection). These challenges prohibit low-cost deployment of facial makeup models, especially on mobile devices. To solve above problems, we propose a brand-new learning paradigm, termed Data Amplify Learning (DAL), alongside a compact makeup model named TinyBeauty. The core idea of DAL lies in employing a Diffusion-based Data Amplifier (DDA) to amplify limited images for the model training, thereby enabling accurate pixel-to-pixel supervision with merely a handful of annotations. Two pivotal innovations in DDA facilitate the above training approach: (1) A Residual Diffusion Model (RDM) is designed to generate high-fidelity detail and circumvent the detail vanishing problem in the vanilla diffusion models; (2) A Fine-Grained Makeup Module (FGMM) is proposed to achieve precise makeup control and combination while retaining face identity. Coupled with DAL, TinyBeauty necessitates merely 80K parameters to achieve a state-of-the-art performance without intricate face prompts. Meanwhile, TinyBeauty achieves a remarkable inference speed of up to 460 fps on the iPhone 13. Extensive experiments show that DAL can produce highly competitive makeup models using only 5 image pairs.
Read more7/17/2024
0
DiffAM: Diffusion-based Adversarial Makeup Transfer for Facial Privacy Protection
Yuhao Sun, Lingyun Yu, Hongtao Xie, Jiaming Li, Yongdong Zhang
With the rapid development of face recognition (FR) systems, the privacy of face images on social media is facing severe challenges due to the abuse of unauthorized FR systems. Some studies utilize adversarial attack techniques to defend against malicious FR systems by generating adversarial examples. However, the generated adversarial examples, i.e., the protected face images, tend to suffer from subpar visual quality and low transferability. In this paper, we propose a novel face protection approach, dubbed DiffAM, which leverages the powerful generative ability of diffusion models to generate high-quality protected face images with adversarial makeup transferred from reference images. To be specific, we first introduce a makeup removal module to generate non-makeup images utilizing a fine-tuned diffusion model with guidance of textual prompts in CLIP space. As the inverse process of makeup transfer, makeup removal can make it easier to establish the deterministic relationship between makeup domain and non-makeup domain regardless of elaborate text prompts. Then, with this relationship, a CLIP-based makeup loss along with an ensemble attack strategy is introduced to jointly guide the direction of adversarial makeup domain, achieving the generation of protected face images with natural-looking makeup and high black-box transferability. Extensive experiments demonstrate that DiffAM achieves higher visual quality and attack success rates with a gain of 12.98% under black-box setting compared with the state of the arts. The code will be available at https://github.com/HansSunY/DiffAM.
Read more5/17/2024
👁️
0
FaceMixup: Enhancing Facial Expression Recognition through Mixed Face Regularization
Fabio A. Faria, Mateus M. Souza, Raoni F. da S. Teixeira, Mauricio P. Segundo
The proliferation of deep learning solutions and the scarcity of large annotated datasets pose significant challenges in real-world applications. Various strategies have been explored to overcome this challenge, with data augmentation (DA) approaches emerging as prominent solutions. DA approaches involve generating additional examples by transforming existing labeled data, thereby enriching the dataset and helping deep learning models achieve improved generalization without succumbing to overfitting. In real applications, where solutions based on deep learning are widely used, there is facial expression recognition (FER), which plays an essential role in human communication, improving a range of knowledge areas (e.g., medicine, security, and marketing). In this paper, we propose a simple and comprehensive face data augmentation approach based on mixed face component regularization that outperforms the classical DA approaches from the literature, including the MixAugment which is a specific approach for the target task in two well-known FER datasets existing in the literature.
Read more5/31/2024

0
Makeup-Guided Facial Privacy Protection via Untrained Neural Network Priors
Fahad Shamshad, Muzammal Naseer, Karthik Nandakumar
Deep learning-based face recognition (FR) systems pose significant privacy risks by tracking users without their consent. While adversarial attacks can protect privacy, they often produce visible artifacts compromising user experience. To mitigate this issue, recent facial privacy protection approaches advocate embedding adversarial noise into the natural looking makeup styles. However, these methods require training on large-scale makeup datasets that are not always readily available. In addition, these approaches also suffer from dataset bias. For instance, training on makeup data that predominantly contains female faces could compromise protection efficacy for male faces. To handle these issues, we propose a test-time optimization approach that solely optimizes an untrained neural network to transfer makeup style from a reference to a source image in an adversarial manner. We introduce two key modules: a correspondence module that aligns regions between reference and source images in latent space, and a decoder with conditional makeup layers. The untrained decoder, optimized via carefully designed structural and makeup consistency losses, generates a protected image that resembles the source but incorporates adversarial makeup to deceive FR models. As our approach does not rely on training with makeup face datasets, it avoids potential male/female dataset biases while providing effective protection. We further extend the proposed approach to videos by leveraging on temporal correlations. Experiments on benchmark datasets demonstrate superior performance in face verification and identification tasks and effectiveness against commercial FR systems. Our code and models will be available at https://github.com/fahadshamshad/deep-facial-privacy-prior
Read more8/23/2024