FastTalker: Jointly Generating Speech and Conversational Gestures from Text

0
Sign in to get full access
Overview
- The paper presents a novel system called FastTalker that can jointly generate speech and conversational gestures from text.
- FastTalker aims to create more natural and engaging human-computer interactions by synthesizing both verbal and nonverbal communication.
- The system utilizes deep learning models to learn the patterns between text, speech, and gestures from large datasets of human interactions.
Plain English Explanation
The researchers developed a system called FastTalker that can take a piece of text as input and automatically generate both the speech audio and the accompanying hand/body movements (gestures) that a person would use when speaking that text out loud. This allows for the creation of more lifelike and engaging virtual assistants or characters that don't just speak, but also move and gesture in a natural way.
The key innovation is that FastTalker learns how to coordinate the speech and gestures jointly, rather than generating them separately. This helps ensure the movements and speech are well-synchronized and flow together naturally, like how a real person would speak and gesture. The system was trained on large datasets of transcribed human conversations, allowing it to pick up on the common patterns and relationships between the words people say and the accompanying hand/body movements.
By generating both speech and gestures together, FastTalker aims to create more engaging and human-like virtual presenters, assistants, or characters that can communicate in a more natural and expressive way. This could have applications in fields like video game development, animation, virtual reality, and human-computer interaction.
Technical Explanation
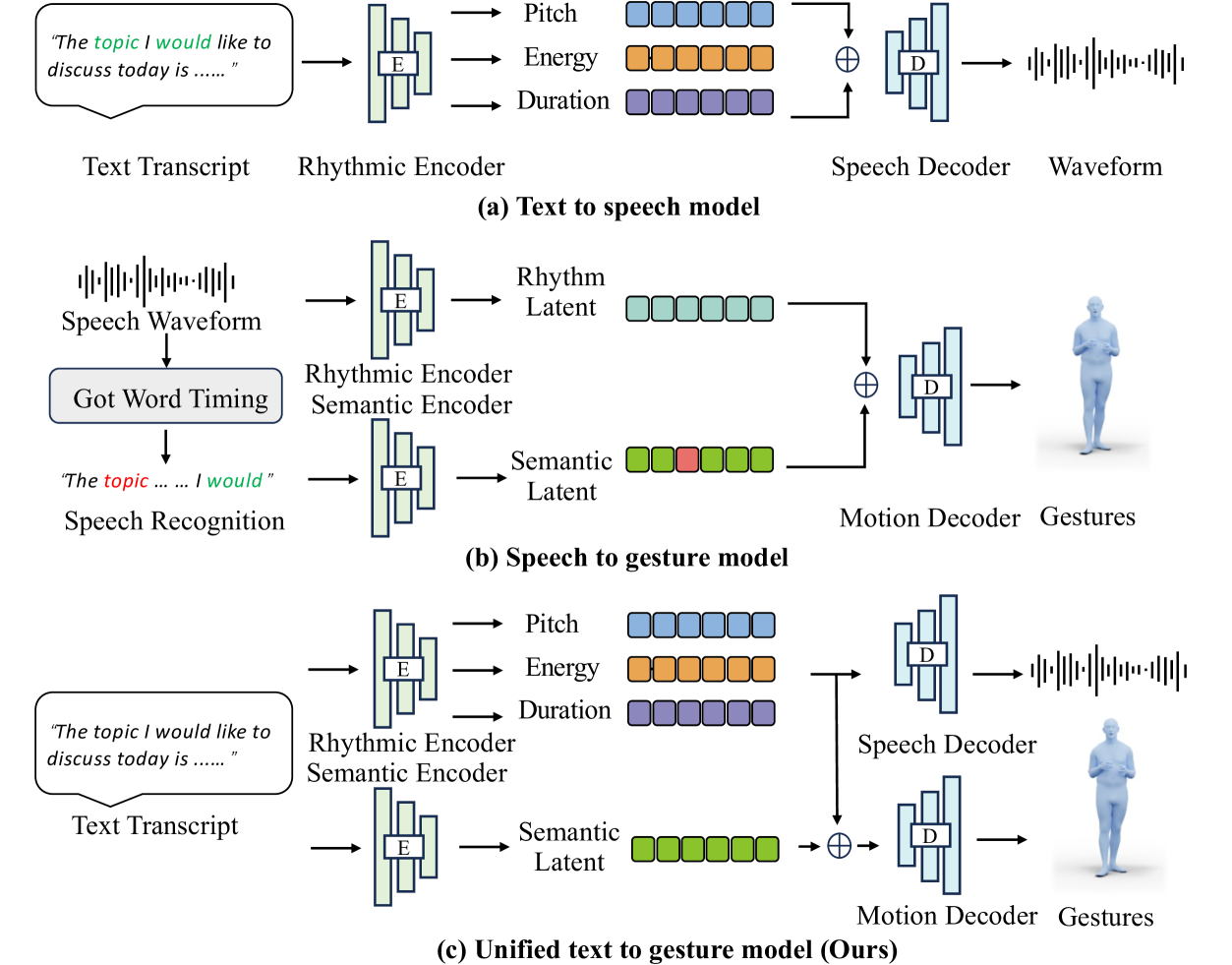
The FastTalker system uses a deep learning architecture to jointly generate speech audio and 3D hand/body gestures from input text. The model consists of an encoder that processes the text input, and two separate decoders - one that generates the speech audio, and another that generates the gesture sequences.
The key innovation is that the speech and gesture decoders are trained jointly, with the gesture decoder also receiving information from the speech decoder to help it coordinate the movements with the audio. This allows the system to learn the natural relationships between the language and the accompanying nonverbal behaviors.
The model was trained and evaluated on large datasets of human conversations, where the text, audio, and 3D motion capture data of the speakers' gestures were recorded. Experiments showed that FastTalker was able to generate speech and gestures that were more natural and synchronous compared to previous approaches that generated them independently.
Critical Analysis
One limitation of the FastTalker system is that it can only generate gestures and speech for a single person - it does not model the back-and-forth dynamics of a real conversation between multiple people. Extending the system to handle multi-party interactions could be an area for future research.
Additionally, the paper does not provide much insight into the specific types of gestures that the model learns to generate. A deeper analysis of the gesture repertoire and how it relates to the semantic content of the speech could yield interesting insights.
Overall, the FastTalker system represents an important step forward in the quest to create more natural and engaging virtual communicators. However, continued advances in areas like multi-party interaction, gesture diversity, and real-time performance will be needed to fully realize the potential of these technologies.
Conclusion
The FastTalker system demonstrates the feasibility of jointly generating speech audio and conversational gestures from text inputs using deep learning. By training the speech and gesture generation components together, the model is able to produce more synchronized and natural-looking virtual presenters or characters.
This work has implications for more engaging and human-like interactions in applications ranging from virtual assistants to video game characters. While the current system has some limitations, the key principles of jointly modeling verbal and nonverbal communication could help pave the way for increasingly realistic and expressive virtual beings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FastTalker: Jointly Generating Speech and Conversational Gestures from Text
Zixin Guo, Jian Zhang
Generating 3D human gestures and speech from a text script is critical for creating realistic talking avatars. One solution is to leverage separate pipelines for text-to-speech (TTS) and speech-to-gesture (STG), but this approach suffers from poor alignment of speech and gestures and slow inference times. In this paper, we introduce FastTalker, an efficient and effective framework that simultaneously generates high-quality speech audio and 3D human gestures at high inference speeds. Our key insight is reusing the intermediate features from speech synthesis for gesture generation, as these features contain more precise rhythmic information than features re-extracted from generated speech. Specifically, 1) we propose an end-to-end framework that concurrently generates speech waveforms and full-body gestures, using intermediate speech features such as pitch, onset, energy, and duration directly for gesture decoding; 2) we redesign the causal network architecture to eliminate dependencies on future inputs for real applications; 3) we employ Reinforcement Learning-based Neural Architecture Search (NAS) to enhance both performance and inference speed by optimizing our network architecture. Experimental results on the BEAT2 dataset demonstrate that FastTalker achieves state-of-the-art performance in both speech synthesis and gesture generation, processing speech and gestures in 0.17 seconds per second on an NVIDIA 3090.
Read more9/26/2024
0
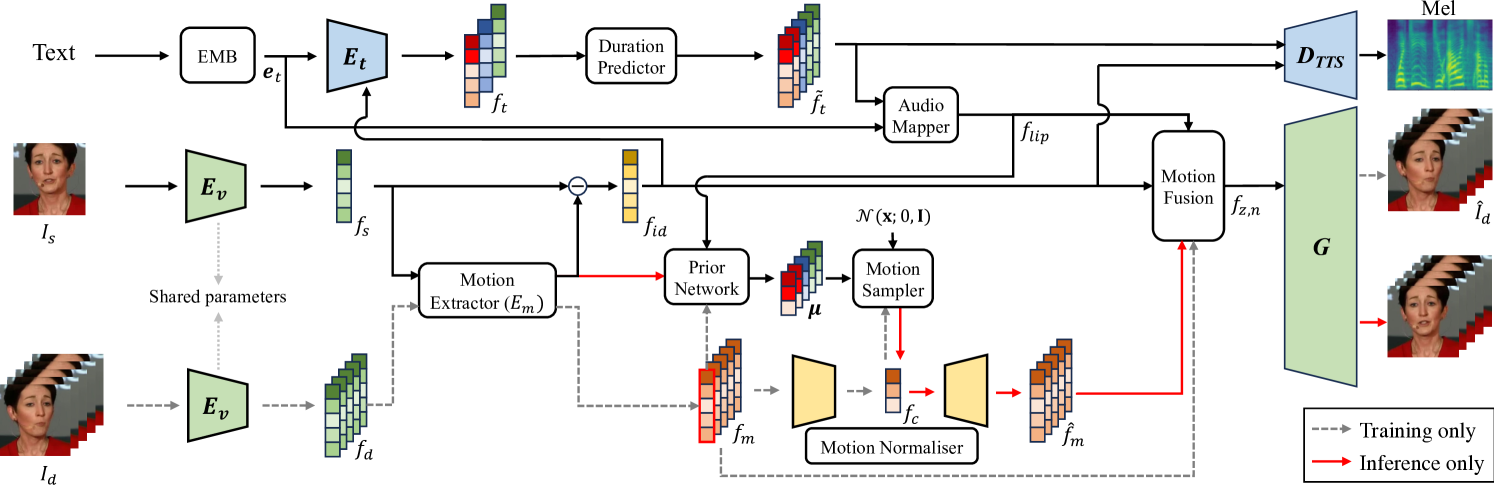
Faces that Speak: Jointly Synthesising Talking Face and Speech from Text
Youngjoon Jang, Ji-Hoon Kim, Junseok Ahn, Doyeop Kwak, Hong-Sun Yang, Yoon-Cheol Ju, Il-Hwan Kim, Byeong-Yeol Kim, Joon Son Chung
The goal of this work is to simultaneously generate natural talking faces and speech outputs from text. We achieve this by integrating Talking Face Generation (TFG) and Text-to-Speech (TTS) systems into a unified framework. We address the main challenges of each task: (1) generating a range of head poses representative of real-world scenarios, and (2) ensuring voice consistency despite variations in facial motion for the same identity. To tackle these issues, we introduce a motion sampler based on conditional flow matching, which is capable of high-quality motion code generation in an efficient way. Moreover, we introduce a novel conditioning method for the TTS system, which utilises motion-removed features from the TFG model to yield uniform speech outputs. Our extensive experiments demonstrate that our method effectively creates natural-looking talking faces and speech that accurately match the input text. To our knowledge, this is the first effort to build a multimodal synthesis system that can generalise to unseen identities.
Read more5/17/2024
🗣️
0
GesGPT: Speech Gesture Synthesis With Text Parsing from GPT
Nan Gao, Zeyu Zhao, Zhi Zeng, Shuwu Zhang, Dongdong Weng, Yihua Bao
Gesture synthesis has gained significant attention as a critical research field, aiming to produce contextually appropriate and natural gestures corresponding to speech or textual input. Although deep learning-based approaches have achieved remarkable progress, they often overlook the rich semantic information present in the text, leading to less expressive and meaningful gestures. In this letter, we propose GesGPT, a novel approach to gesture generation that leverages the semantic analysis capabilities of large language models , such as ChatGPT. By capitalizing on the strengths of LLMs for text analysis, we adopt a controlled approach to generate and integrate professional gestures and base gestures through a text parsing script, resulting in diverse and meaningful gestures. Firstly, our approach involves the development of prompt principles that transform gesture generation into an intention classification problem using ChatGPT. We also conduct further analysis on emphasis words and semantic words to aid in gesture generation. Subsequently, we construct a specialized gesture lexicon with multiple semantic annotations, decoupling the synthesis of gestures into professional gestures and base gestures. Finally, we merge the professional gestures with base gestures. Experimental results demonstrate that GesGPT effectively generates contextually appropriate and expressive gestures.
Read more5/29/2024
0
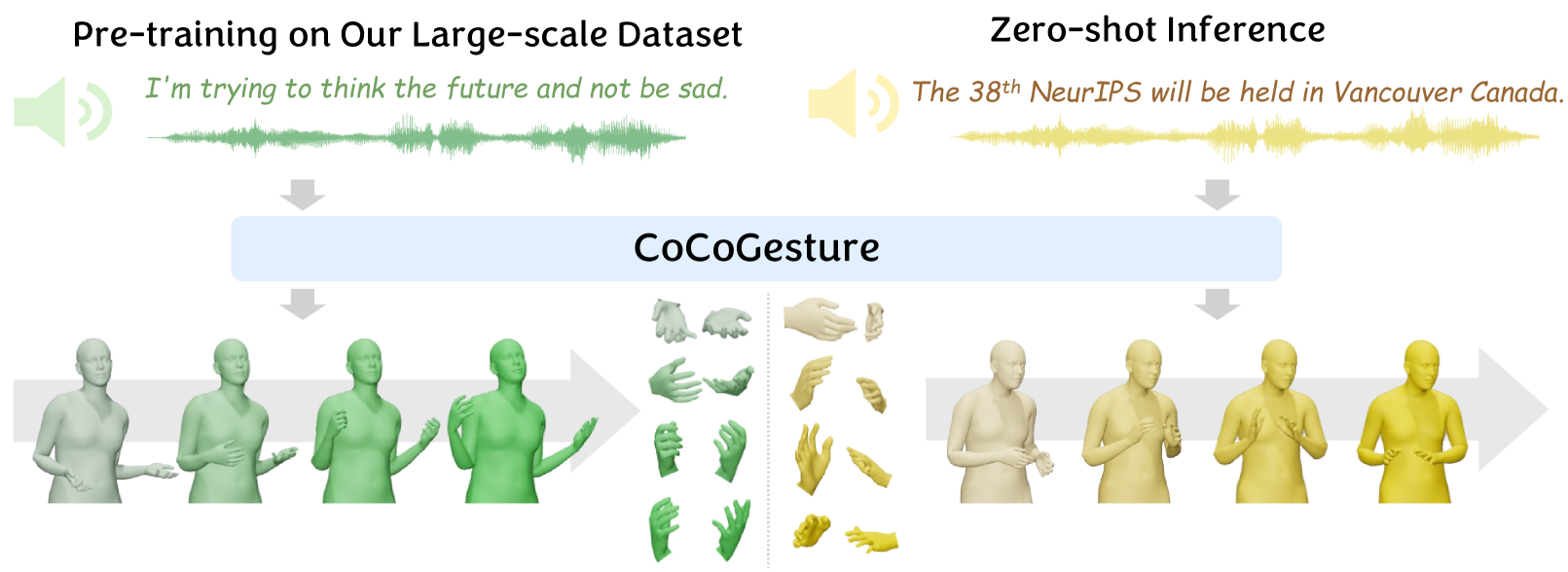
CoCoGesture: Toward Coherent Co-speech 3D Gesture Generation in the Wild
Xingqun Qi, Hengyuan Zhang, Yatian Wang, Jiahao Pan, Chen Liu, Peng Li, Xiaowei Chi, Mengfei Li, Qixun Zhang, Wei Xue, Shanghang Zhang, Wenhan Luo, Qifeng Liu, Yike Guo
Deriving co-speech 3D gestures has seen tremendous progress in virtual avatar animation. Yet, the existing methods often produce stiff and unreasonable gestures with unseen human speech inputs due to the limited 3D speech-gesture data. In this paper, we propose CoCoGesture, a novel framework enabling vivid and diverse gesture synthesis from unseen human speech prompts. Our key insight is built upon the custom-designed pretrain-fintune training paradigm. At the pretraining stage, we aim to formulate a large generalizable gesture diffusion model by learning the abundant postures manifold. Therefore, to alleviate the scarcity of 3D data, we first construct a large-scale co-speech 3D gesture dataset containing more than 40M meshed posture instances across 4.3K speakers, dubbed GES-X. Then, we scale up the large unconditional diffusion model to 1B parameters and pre-train it to be our gesture experts. At the finetune stage, we present the audio ControlNet that incorporates the human voice as condition prompts to guide the gesture generation. Here, we construct the audio ControlNet through a trainable copy of our pre-trained diffusion model. Moreover, we design a novel Mixture-of-Gesture-Experts (MoGE) block to adaptively fuse the audio embedding from the human speech and the gesture features from the pre-trained gesture experts with a routing mechanism. Such an effective manner ensures audio embedding is temporal coordinated with motion features while preserving the vivid and diverse gesture generation. Extensive experiments demonstrate that our proposed CoCoGesture outperforms the state-of-the-art methods on the zero-shot speech-to-gesture generation. The dataset will be publicly available at: https://mattie-e.github.io/GES-X/
Read more5/28/2024