Fact-Aware Multimodal Retrieval Augmentation for Accurate Medical Radiology Report Generation

0

Sign in to get full access
Overview
- The research paper explores a method for improving the accuracy of medical radiology report generation using fact-aware multimodal retrieval augmentation.
- The proposed approach aims to enhance the factual correctness and consistency of generated reports by leveraging retrieval-augmented language models.
- The key contribution is the development of a fact-aware multimodal retrieval system that can effectively incorporate relevant factual knowledge into the report generation process.
Plain English Explanation
The research paper discusses a way to make medical radiology reports more accurate and reliable. Radiology reports are written by doctors to describe what they see in medical images like X-rays or MRIs. These reports are important for diagnosing and treating patients, so it's crucial that they are factually correct.
The researchers developed a new system that helps language models, which are AI systems that can generate text, to produce more accurate and consistent reports. The key idea is to have the language model not just generate the report from scratch, but also retrieve relevant factual information from a database to include in the report.
This fact-aware multimodal retrieval system allows the language model to access and incorporate important medical knowledge, like the typical characteristics of different diseases or the expected findings in certain types of scans. By combining this factual information with the language model's text generation capabilities, the researchers were able to create radiology reports that were more accurate and consistent with expert-written reports.
The benefit of this approach is that it helps strengthen the connection between large language models and real-world medical knowledge, making the generated reports more reliable and trustworthy for clinical use.
Technical Explanation
The researchers developed a Fact-Aware Multimodal Retrieval Augmentation (FAMRA) system to improve the accuracy of medical radiology report generation. The key components of their approach include:
-
Multimodal Retrieval Module: This module retrieves relevant factual information from a database of medical knowledge given the input radiology image and text prompts. It uses a dual-encoder architecture to align the visual and textual modalities for effective retrieval.
-
Fact-Aware Report Generation: The retrieved factual information is then fused with the language model's text generation process to produce radiology reports that are more factually consistent and accurate. This is achieved through a knowledge-attention mechanism that selectively incorporates the relevant facts.
-
Joint Training: The entire FAMRA system is jointly trained end-to-end using a combination of retrieval, generation, and factual consistency objectives. This allows the model to learn how to effectively leverage the retrieved facts to improve the quality of the generated reports.
The researchers evaluated their approach on several medical radiology datasets and found that FAMRA outperformed strong baseline models in terms of factual correctness, fluency, and consistency with expert-written reports. The results demonstrate the effectiveness of their fact-aware retrieval augmentation approach for enhancing the accuracy and reliability of medical text generation.
Critical Analysis
The researchers acknowledge several limitations and areas for future work in their paper:
-
Domain Specificity: The current FAMRA system is tailored to the medical radiology domain, and it's unclear how well the approach would generalize to other types of specialized text generation tasks.
-
Scalability of Retrieval: As the size of the factual knowledge base grows, the retrieval process may become computationally expensive, which could limit the practicality of the approach for real-world deployment.
-
Evaluation Metrics: The paper relies heavily on automatic evaluation metrics to assess factual correctness and consistency, but these metrics may not fully capture the nuances of medical report quality as perceived by human experts.
-
Interpretability: The inner workings of the fact-aware generation process are not highly interpretable, which could make it challenging to diagnose and debug the system's failures.
Additionally, one could question whether the proposed approach truly captures the full breadth of medical knowledge and reasoning required for accurate radiology report generation. While the fact-aware retrieval component is a valuable contribution, there may be other aspects of medical expertise, such as causal reasoning and complex decision-making, that are not fully addressed by the current system.
Conclusion
The Fact-Aware Multimodal Retrieval Augmentation (FAMRA) system described in this research paper represents an important step towards improving the accuracy and reliability of medical text generation, specifically in the context of radiology report generation. By incorporating relevant factual knowledge into the report generation process, the researchers have demonstrated the potential to generate more consistent and trustworthy medical reports, which could have significant implications for clinical decision-making and patient care.
While the paper highlights several limitations and areas for future work, the core ideas and insights presented here could inspire further advancements in the field of medical language generation and the broader challenge of aligning large language models with real-world domain knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fact-Aware Multimodal Retrieval Augmentation for Accurate Medical Radiology Report Generation
Liwen Sun, James Zhao, Megan Han, Chenyan Xiong
Multimodal foundation models hold significant potential for automating radiology report generation, thereby assisting clinicians in diagnosing cardiac diseases. However, generated reports often suffer from serious factual inaccuracy. In this paper, we introduce a fact-aware multimodal retrieval-augmented pipeline in generating accurate radiology reports (FactMM-RAG). We first leverage RadGraph to mine factual report pairs, then integrate factual knowledge to train a universal multimodal retriever. Given a radiology image, our retriever can identify high-quality reference reports to augment multimodal foundation models, thus enhancing the factual completeness and correctness of report generation. Experiments on two benchmark datasets show that our multimodal retriever outperforms state-of-the-art retrievers on both language generation and radiology-specific metrics, up to 6.5% and 2% score in F1CheXbert and F1RadGraph. Further analysis indicates that employing our factually-informed training strategy imposes an effective supervision signal, without relying on explicit diagnostic label guidance, and successfully propagates fact-aware capabilities from the multimodal retriever to the multimodal foundation model in radiology report generation.
Read more7/23/2024
🤿
0
A Survey of Deep Learning-based Radiology Report Generation Using Multimodal Data
Xinyi Wang, Grazziela Figueredo, Ruizhe Li, Wei Emma Zhang, Weitong Chen, Xin Chen
Automatic radiology report generation can alleviate the workload for physicians and minimize regional disparities in medical resources, therefore becoming an important topic in the medical image analysis field. It is a challenging task, as the computational model needs to mimic physicians to obtain information from multi-modal input data (i.e., medical images, clinical information, medical knowledge, etc.), and produce comprehensive and accurate reports. Recently, numerous works emerged to address this issue using deep learning-based methods, such as transformers, contrastive learning, and knowledge-base construction. This survey summarizes the key techniques developed in the most recent works and proposes a general workflow for deep learning-based report generation with five main components, including multi-modality data acquisition, data preparation, feature learning, feature fusion/interaction, and report generation. The state-of-the-art methods for each of these components are highlighted. Additionally, training strategies, public datasets, evaluation methods, current challenges, and future directions in this field are summarized. We have also conducted a quantitative comparison between different methods under the same experimental setting. This is the most up-to-date survey that focuses on multi-modality inputs and data fusion for radiology report generation. The aim is to provide comprehensive and rich information for researchers interested in automatic clinical report generation and medical image analysis, especially when using multimodal inputs, and assist them in developing new algorithms to advance the field.
Read more5/22/2024
💬
0
RadioRAG: Factual Large Language Models for Enhanced Diagnostics in Radiology Using Dynamic Retrieval Augmented Generation
Soroosh Tayebi Arasteh, Mahshad Lotfinia, Keno Bressem, Robert Siepmann, Dyke Ferber, Christiane Kuhl, Jakob Nikolas Kather, Sven Nebelung, Daniel Truhn
Large language models (LLMs) have advanced the field of artificial intelligence (AI) in medicine. However LLMs often generate outdated or inaccurate information based on static training datasets. Retrieval augmented generation (RAG) mitigates this by integrating outside data sources. While previous RAG systems used pre-assembled, fixed databases with limited flexibility, we have developed Radiology RAG (RadioRAG) as an end-to-end framework that retrieves data from authoritative radiologic online sources in real-time. RadioRAG is evaluated using a dedicated radiologic question-and-answer dataset (RadioQA). We evaluate the diagnostic accuracy of various LLMs when answering radiology-specific questions with and without access to additional online information via RAG. Using 80 questions from RSNA Case Collection across radiologic subspecialties and 24 additional expert-curated questions, for which the correct gold-standard answers were available, LLMs (GPT-3.5-turbo, GPT-4, Mistral-7B, Mixtral-8x7B, and Llama3 [8B and 70B]) were prompted with and without RadioRAG. RadioRAG retrieved context-specific information from www.radiopaedia.org in real-time and incorporated them into its reply. RadioRAG consistently improved diagnostic accuracy across all LLMs, with relative improvements ranging from 2% to 54%. It matched or exceeded question answering without RAG across radiologic subspecialties, particularly in breast imaging and emergency radiology. However, degree of improvement varied among models; GPT-3.5-turbo and Mixtral-8x7B-instruct-v0.1 saw notable gains, while Mistral-7B-instruct-v0.2 showed no improvement, highlighting variability in its effectiveness. LLMs benefit when provided access to domain-specific data beyond their training data. For radiology, RadioRAG establishes a robust framework that substantially improves diagnostic accuracy and factuality in radiological question answering.
Read more7/23/2024
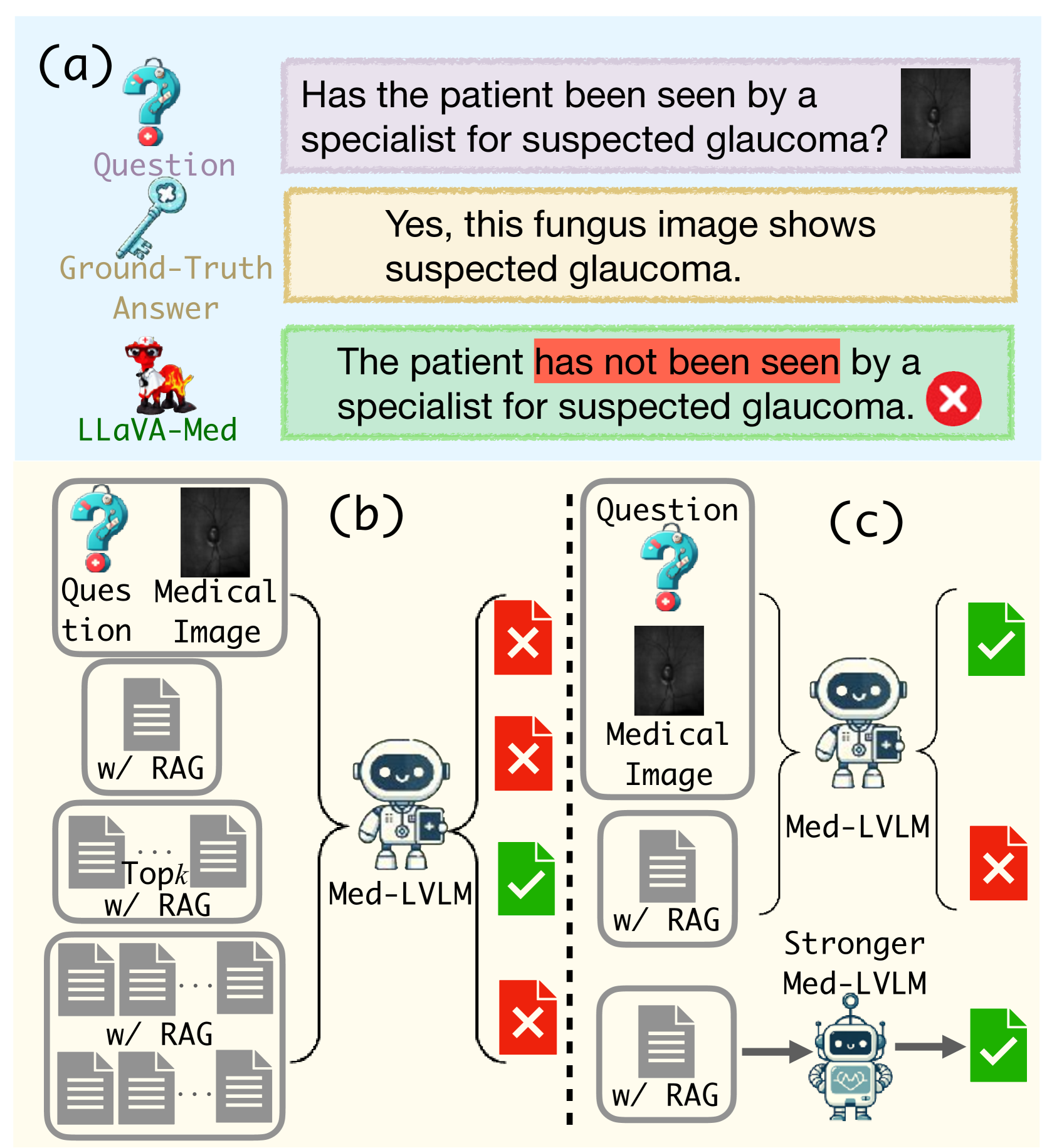
0
RULE: Reliable Multimodal RAG for Factuality in Medical Vision Language Models
Peng Xia, Kangyu Zhu, Haoran Li, Hongtu Zhu, Yun Li, Gang Li, Linjun Zhang, Huaxiu Yao
The recent emergence of Medical Large Vision Language Models (Med-LVLMs) has enhanced medical diagnosis. However, current Med-LVLMs frequently encounter factual issues, often generating responses that do not align with established medical facts. Retrieval-Augmented Generation (RAG), which utilizes external knowledge, can improve the factual accuracy of these models but introduces two major challenges. First, limited retrieved contexts might not cover all necessary information, while excessive retrieval can introduce irrelevant and inaccurate references, interfering with the model's generation. Second, in cases where the model originally responds correctly, applying RAG can lead to an over-reliance on retrieved contexts, resulting in incorrect answers. To address these issues, we propose RULE, which consists of two components. First, we introduce a provably effective strategy for controlling factuality risk through the calibrated selection of the number of retrieved contexts. Second, based on samples where over-reliance on retrieved contexts led to errors, we curate a preference dataset to fine-tune the model, balancing its dependence on inherent knowledge and retrieved contexts for generation. We demonstrate the effectiveness of RULE on three medical VQA datasets, achieving an average improvement of 20.8% in factual accuracy. We publicly release our benchmark and code in https://github.com/richard-peng-xia/RULE.
Read more7/9/2024