RULE: Reliable Multimodal RAG for Factuality in Medical Vision Language Models

0
Sign in to get full access
Overview
- This paper presents a novel model called RULE (Reliable Multimodal RAG for Factuality in Medical Vision Language Models) that aims to improve the factual reliability of medical vision-language models.
- The key innovations include a multimodal Retrieval-Augmented Generation (RAG) architecture and a factuality optimization training objective.
- The authors demonstrate the effectiveness of RULE on several medical datasets, showing improvements in factual reliability and generation quality compared to existing models.
Plain English Explanation
The paper introduces a new deep learning model called RULE that is designed to improve the accuracy and trustworthiness of medical image-text generation tasks. Medical AI systems need to be highly reliable, as mistakes could have serious consequences for patient care.
RULE uses a Retrieval-Augmented Generation (RAG) approach, which means it can not only generate new text, but also retrieve relevant information from a knowledge base to include in the output. This helps ensure the generated text is factually accurate.
The authors also introduced a new training objective that specifically optimizes the model for factual correctness, going beyond just improving the overall language generation quality. This "factuality optimization" step helps RULE avoid hallucinating or making up false information, which is a common problem in large language models.
The researchers tested RULE on several medical datasets, and showed it outperformed existing state-of-the-art models in terms of factual reliability and generation quality. This suggests RULE could be a valuable tool for applications like automating medical report writing or generating educational content about health topics.
Technical Explanation
The core of RULE is a multimodal Retrieval-Augmented Generation (RAG) architecture, which combines a text generation model with a knowledge retrieval module. This allows the model to not only generate fluent text, but also selectively incorporate relevant factual information from a knowledge base into the output.
The knowledge base used in RULE is a large corpus of medical text data, which the model can query to find pertinent information to include in its responses. This is done through an attention-based retrieval mechanism that learns to identify the most salient facts to bring into the generation process.
In addition to the RAG architecture, the authors also introduced a new training objective called "factuality optimization". This loss function explicitly penalizes the model for generating text that is factually inconsistent with the information in the knowledge base. This encourages RULE to be more cautious and conservative in its outputs, preferring to cite verifiable facts over making unsubstantiated claims.
The authors evaluated RULE on several medical vision-language benchmarks, including MedVidQL, MedInfo, and FaVIL. Compared to strong baseline models like UNITER, RULE demonstrated superior performance in terms of factual correctness, generation quality, and overall task performance.
Critical Analysis
The authors acknowledge several limitations of their work. First, while RULE shows promising results, the knowledge base it uses is still relatively small compared to the breadth of medical information that would be needed for real-world applications. Scaling up the knowledge base is an important area for future work.
Additionally, the factuality optimization training objective, while effective, may not capture all nuances of what it means for medical text to be truly "factual". The authors suggest exploring other ways of assessing and incentivizing factual reliability in these models.
Another potential issue is the reliance on human-annotated datasets for evaluation. These datasets may have their own biases and incomplete coverage of the medical domain. Developing more comprehensive and diverse evaluation benchmarks could help provide a clearer picture of RULE's real-world performance.
Overall, the RULE model represents an important step forward in developing more reliable and trustworthy medical language AI systems. However, there are still many challenges to overcome before these technologies can be safely deployed at scale in sensitive healthcare applications.
Conclusion
The RULE model presented in this paper introduces a novel approach to improving the factual reliability of medical vision-language models. By combining a Retrieval-Augmented Generation architecture with a factuality optimization training objective, the authors have demonstrated significant improvements in both generation quality and factual correctness compared to existing state-of-the-art models.
As medical AI systems become more prominent, ensuring their outputs are accurate and trustworthy is crucial. The RULE framework provides a promising direction for addressing this challenge, though further research is needed to scale up the knowledge base, refine the factuality assessment, and develop more comprehensive evaluation benchmarks.
Overall, this work represents an important step forward in the quest to build medical AI systems that can be reliably deployed to assist clinicians and educate patients. The authors' innovations in multimodal reasoning and factuality optimization could have wide-ranging applications beyond the medical domain as well.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RULE: Reliable Multimodal RAG for Factuality in Medical Vision Language Models
Peng Xia, Kangyu Zhu, Haoran Li, Hongtu Zhu, Yun Li, Gang Li, Linjun Zhang, Huaxiu Yao
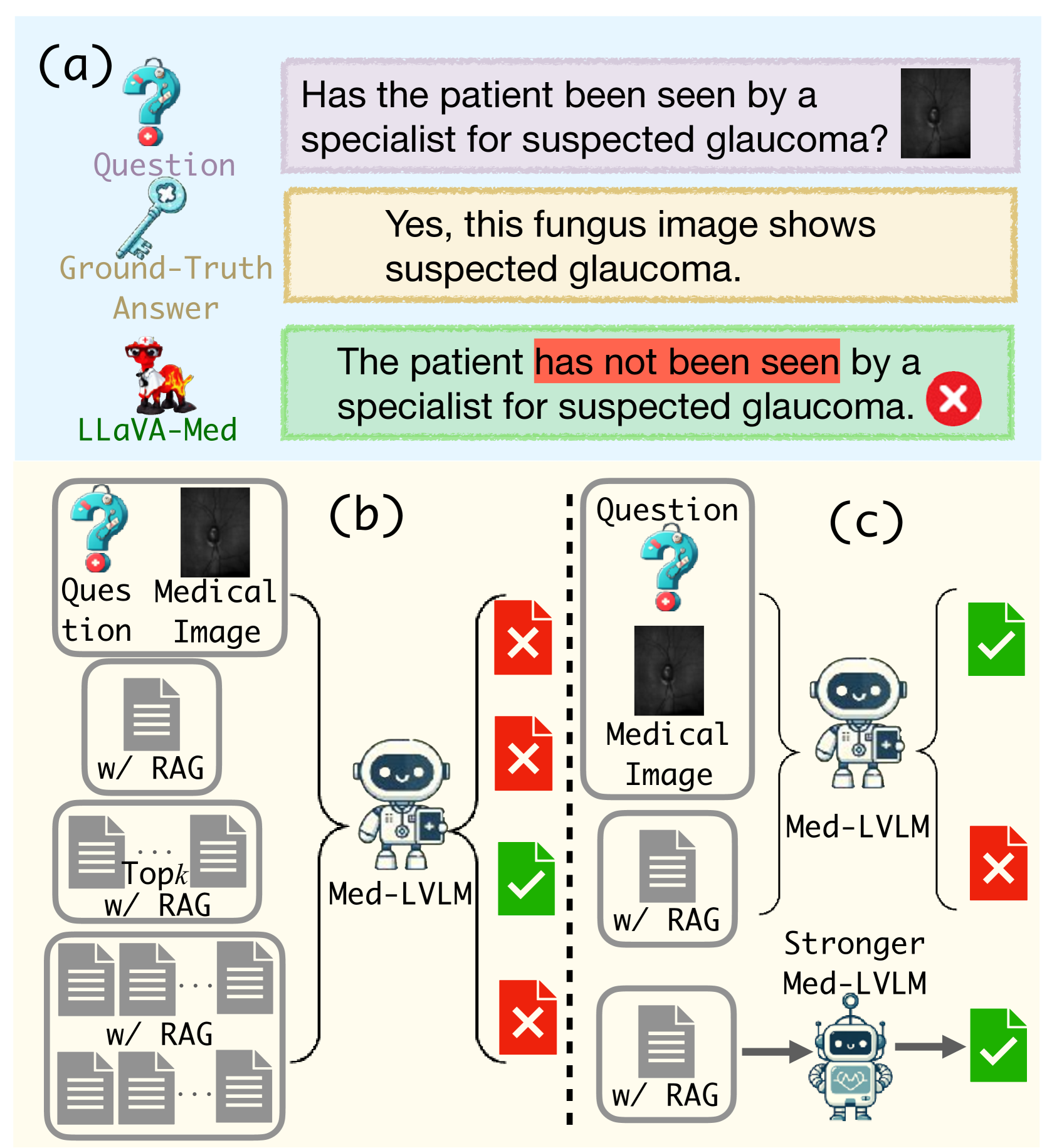
The recent emergence of Medical Large Vision Language Models (Med-LVLMs) has enhanced medical diagnosis. However, current Med-LVLMs frequently encounter factual issues, often generating responses that do not align with established medical facts. Retrieval-Augmented Generation (RAG), which utilizes external knowledge, can improve the factual accuracy of these models but introduces two major challenges. First, limited retrieved contexts might not cover all necessary information, while excessive retrieval can introduce irrelevant and inaccurate references, interfering with the model's generation. Second, in cases where the model originally responds correctly, applying RAG can lead to an over-reliance on retrieved contexts, resulting in incorrect answers. To address these issues, we propose RULE, which consists of two components. First, we introduce a provably effective strategy for controlling factuality risk through the calibrated selection of the number of retrieved contexts. Second, based on samples where over-reliance on retrieved contexts led to errors, we curate a preference dataset to fine-tune the model, balancing its dependence on inherent knowledge and retrieved contexts for generation. We demonstrate the effectiveness of RULE on three medical VQA datasets, achieving an average improvement of 20.8% in factual accuracy. We publicly release our benchmark and code in https://github.com/richard-peng-xia/RULE.
Read more7/9/2024
🛸
0
MKRAG: Medical Knowledge Retrieval Augmented Generation for Medical Question Answering
Yucheng Shi, Shaochen Xu, Tianze Yang, Zhengliang Liu, Tianming Liu, Quanzheng Li, Xiang Li, Ninghao Liu
Large Language Models (LLMs), although powerful in general domains, often perform poorly on domain-specific tasks such as medical question answering (QA). In addition, LLMs tend to function as black-boxes, making it challenging to modify their behavior. To address the problem, our work employs a transparent process of retrieval augmented generation (RAG), aiming to improve LLM responses without the need for fine-tuning or retraining. Specifically, we propose a comprehensive retrieval strategy to extract medical facts from an external knowledge base, and then inject them into the LLM's query prompt. Focusing on medical QA, we evaluate the impact of different retrieval models and the number of facts on LLM performance using the MedQA-SMILE dataset. Notably, our retrieval-augmented Vicuna-7B model exhibited an accuracy improvement from 44.46% to 48.54%. This work underscores the potential of RAG to enhance LLM performance, offering a practical approach to mitigate the challenges posed by black-box LLMs.
Read more8/19/2024
0
Tool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
Zhongzhen Huang, Kui Xue, Yongqi Fan, Linjie Mu, Ruoyu Liu, Tong Ruan, Shaoting Zhang, Xiaofan Zhang
Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new textit{Distill-Retrieve-Read} framework instead of the previous textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.
Read more4/30/2024
💬
0
RadioRAG: Factual Large Language Models for Enhanced Diagnostics in Radiology Using Dynamic Retrieval Augmented Generation
Soroosh Tayebi Arasteh, Mahshad Lotfinia, Keno Bressem, Robert Siepmann, Dyke Ferber, Christiane Kuhl, Jakob Nikolas Kather, Sven Nebelung, Daniel Truhn
Large language models (LLMs) have advanced the field of artificial intelligence (AI) in medicine. However LLMs often generate outdated or inaccurate information based on static training datasets. Retrieval augmented generation (RAG) mitigates this by integrating outside data sources. While previous RAG systems used pre-assembled, fixed databases with limited flexibility, we have developed Radiology RAG (RadioRAG) as an end-to-end framework that retrieves data from authoritative radiologic online sources in real-time. RadioRAG is evaluated using a dedicated radiologic question-and-answer dataset (RadioQA). We evaluate the diagnostic accuracy of various LLMs when answering radiology-specific questions with and without access to additional online information via RAG. Using 80 questions from RSNA Case Collection across radiologic subspecialties and 24 additional expert-curated questions, for which the correct gold-standard answers were available, LLMs (GPT-3.5-turbo, GPT-4, Mistral-7B, Mixtral-8x7B, and Llama3 [8B and 70B]) were prompted with and without RadioRAG. RadioRAG retrieved context-specific information from www.radiopaedia.org in real-time and incorporated them into its reply. RadioRAG consistently improved diagnostic accuracy across all LLMs, with relative improvements ranging from 2% to 54%. It matched or exceeded question answering without RAG across radiologic subspecialties, particularly in breast imaging and emergency radiology. However, degree of improvement varied among models; GPT-3.5-turbo and Mixtral-8x7B-instruct-v0.1 saw notable gains, while Mistral-7B-instruct-v0.2 showed no improvement, highlighting variability in its effectiveness. LLMs benefit when provided access to domain-specific data beyond their training data. For radiology, RadioRAG establishes a robust framework that substantially improves diagnostic accuracy and factuality in radiological question answering.
Read more7/23/2024