Fact or Fiction? Improving Fact Verification with Knowledge Graphs through Simplified Subgraph Retrievals

0

Sign in to get full access
Overview
- This paper proposes a method to improve fact verification using knowledge graphs.
- The key idea is to retrieve simplified subgraphs from knowledge graphs to help verify claims.
- The authors demonstrate that this approach outperforms existing methods on fact verification tasks.
Plain English Explanation
The paper focuses on the challenge of fact verification - determining whether a given claim or statement is true or false. To tackle this problem, the researchers developed a new method that leverages knowledge graphs.
Knowledge graphs are structured databases that store information about entities (like people, places, and things) and the relationships between them. The key insight of this paper is that by retrieving simplified "subgraphs" from a knowledge graph, rather than using the full graph, the fact verification process can be made more efficient and effective.
Specifically, the method first identifies the relevant entities and relationships mentioned in a given claim. It then retrieves a small, focused subgraph from the larger knowledge graph that contains just the information needed to verify that claim. This "simplified subgraph" is then used as the basis for determining whether the claim is true or false.
The researchers show that this approach outperforms existing fact verification methods that rely on the full knowledge graph or other types of textual information. By focusing on the most relevant information, the simplified subgraph approach is able to more accurately assess the veracity of claims.
Technical Explanation
The core of the proposed method is a subgraph retrieval module that identifies and extracts a relevant subgraph from a knowledge graph given an input claim. This subgraph is then fed into a neural network-based fact verification model.
The subgraph retrieval process works as follows:
- Entity Linking: The first step is to identify the key entities mentioned in the claim and link them to their corresponding nodes in the knowledge graph.
- Relation Extraction: Next, the method extracts the relationships between the entities mentioned in the claim.
- Subgraph Extraction: Using the identified entities and relations, the system retrieves a focused subgraph from the larger knowledge graph that contains just the information relevant to verifying the given claim.
This simplified subgraph is then passed to a fact verification model that uses graph neural networks to assess the truthfulness of the claim. The authors demonstrate that this approach outperforms prior methods that use the full knowledge graph or other textual data sources.
Critical Analysis
The key innovation of this work is the use of simplified subgraphs for fact verification, which helps to overcome the scalability issues that can arise when working with large, complex knowledge graphs. By focusing only on the most relevant information, the method is able to make more accurate assessments of claim truthfulness.
However, a potential limitation of this approach is that the subgraph extraction process relies heavily on the quality and coverage of the underlying knowledge graph. If the knowledge graph is incomplete or contains inaccurate information, the simplified subgraphs may not contain all the necessary evidence to properly verify claims.
Additionally, the paper does not explore how this method would perform on more open-ended or ambiguous claims, where the relevant information may be more difficult to extract from the knowledge graph. Further research would be needed to understand the broader applicability of this technique.
Conclusion
This paper presents a novel approach to fact verification that leverages knowledge graphs in a more efficient and targeted way. By retrieving simplified subgraphs rather than using the full knowledge graph, the method is able to achieve stronger performance on fact verification tasks.
While the reliance on knowledge graph quality is a potential limitation, the core idea of optimizing the information retrieval process for fact verification is a promising direction. This work demonstrates the value of carefully designing knowledge-based systems to focus on the most relevant information, which could have broader implications for other knowledge-intensive AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fact or Fiction? Improving Fact Verification with Knowledge Graphs through Simplified Subgraph Retrievals
Tobias A. Opsahl
Despite recent success in natural language processing (NLP), fact verification still remains a difficult task. Due to misinformation spreading increasingly fast, attention has been directed towards automatically verifying the correctness of claims. In the domain of NLP, this is usually done by training supervised machine learning models to verify claims by utilizing evidence from trustworthy corpora. We present efficient methods for verifying claims on a dataset where the evidence is in the form of structured knowledge graphs. We use the FactKG dataset, which is constructed from the DBpedia knowledge graph extracted from Wikipedia. By simplifying the evidence retrieval process, from fine-tuned language models to simple logical retrievals, we are able to construct models that both require less computational resources and achieve better test-set accuracy.
Read more8/15/2024
📈
0
A Knowledge Enhanced Learning and Semantic Composition Model for Multi-Claim Fact Checking
Shuai Wang, Penghui Wei, Qingchao Kong, Wenji Mao
To inhibit the spread of rumorous information and its severe consequences, traditional fact checking aims at retrieving relevant evidence to verify the veracity of a given claim. Fact checking methods typically use knowledge graphs (KGs) as external repositories and develop reasoning mechanism to retrieve evidence for verifying the triple claim. However, existing methods only focus on verifying a single claim. As real-world rumorous information is more complex and a textual statement is often composed of multiple clauses (i.e. represented as multiple claims instead of a single one), multiclaim fact checking is not only necessary but more important for practical applications. Although previous methods for verifying a single triple can be applied repeatedly to verify multiple triples one by one, they ignore the contextual information implied in a multi-claim statement and could not learn the rich semantic information in the statement as a whole. In this paper, we propose an end-to-end knowledge enhanced learning and verification method for multi-claim fact checking. Our method consists of two modules, KG-based learning enhancement and multi-claim semantic composition. To fully utilize the contextual information, the KG-based learning enhancement module learns the dynamic context-specific representations via selectively aggregating relevant attributes of entities. To capture the compositional semantics of multiple triples, the multi-claim semantic composition module constructs the graph structure to model claim-level interactions, and integrates global and salient local semantics with multi-head attention. Experimental results on a real-world dataset and two benchmark datasets show the effectiveness of our method for multi-claim fact checking over KG.
Read more7/30/2024

0
FactGenius: Combining Zero-Shot Prompting and Fuzzy Relation Mining to Improve Fact Verification with Knowledge Graphs
Sushant Gautam
Fact-checking is a crucial natural language processing (NLP) task that verifies the truthfulness of claims by considering reliable evidence. Traditional methods are often limited by labour-intensive data curation and rule-based approaches. In this paper, we present FactGenius, a novel method that enhances fact-checking by combining zero-shot prompting of large language models (LLMs) with fuzzy text matching on knowledge graphs (KGs). Leveraging DBpedia, a structured linked data dataset derived from Wikipedia, FactGenius refines LLM-generated connections using similarity measures to ensure accuracy. The evaluation of FactGenius on the FactKG, a benchmark dataset for fact verification, demonstrates that it significantly outperforms existing baselines, particularly when fine-tuning RoBERTa as a classifier. The two-stage approach of filtering and validating connections proves crucial, achieving superior performance across various reasoning types and establishing FactGenius as a promising tool for robust fact-checking. The code and materials are available at https://github.com/SushantGautam/FactGenius.
Read more6/4/2024
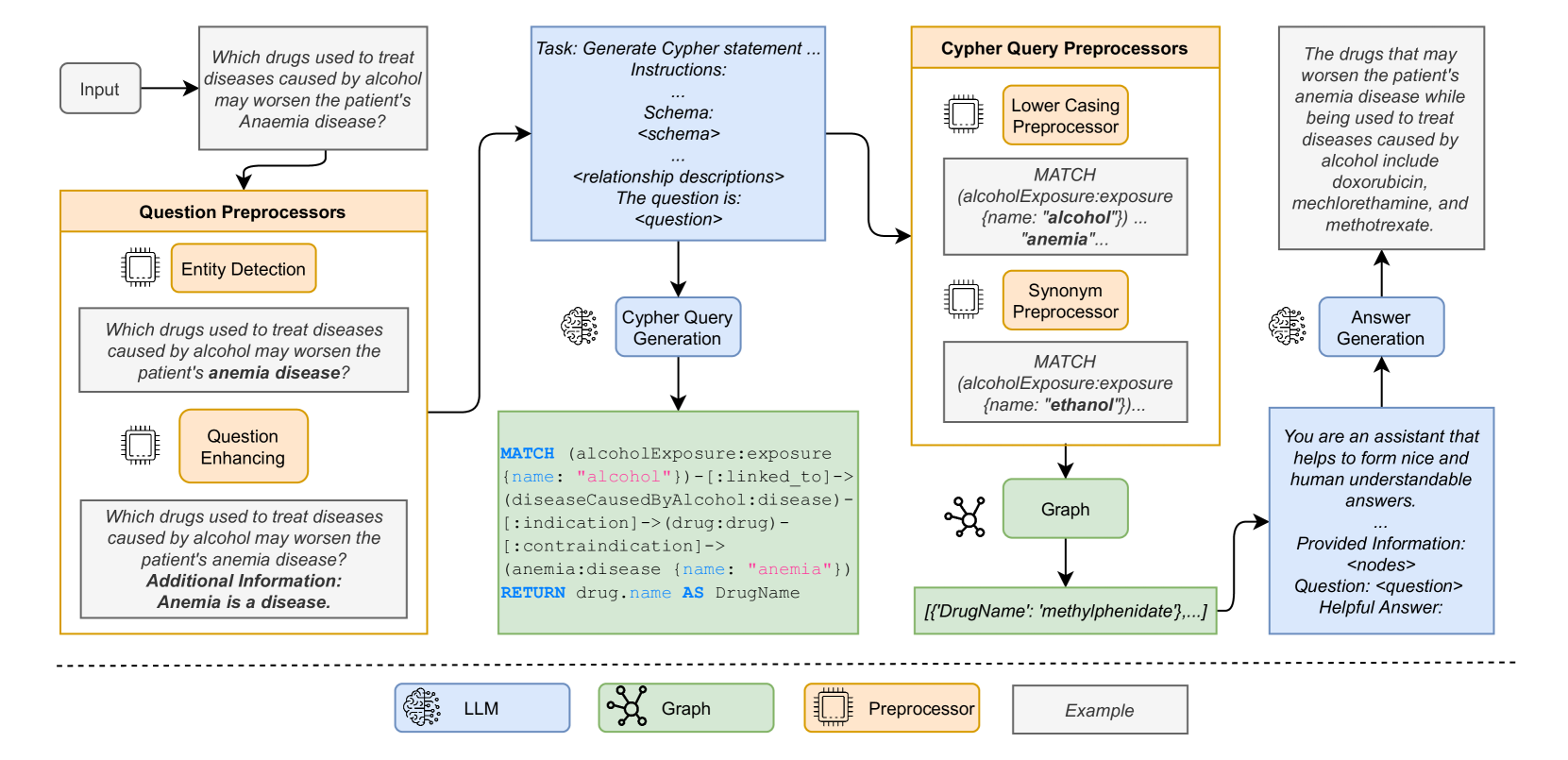
0
Fact Finder -- Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs
Daniel Steinigen, Roman Teucher, Timm Heine Ruland, Max Rudat, Nicolas Flores-Herr, Peter Fischer, Nikola Milosevic, Christopher Schymura, Angelo Ziletti
Recent advancements in Large Language Models (LLMs) have showcased their proficiency in answering natural language queries. However, their effectiveness is hindered by limited domain-specific knowledge, raising concerns about the reliability of their responses. We introduce a hybrid system that augments LLMs with domain-specific knowledge graphs (KGs), thereby aiming to enhance factual correctness using a KG-based retrieval approach. We focus on a medical KG to demonstrate our methodology, which includes (1) pre-processing, (2) Cypher query generation, (3) Cypher query processing, (4) KG retrieval, and (5) LLM-enhanced response generation. We evaluate our system on a curated dataset of 69 samples, achieving a precision of 78% in retrieving correct KG nodes. Our findings indicate that the hybrid system surpasses a standalone LLM in accuracy and completeness, as verified by an LLM-as-a-Judge evaluation method. This positions the system as a promising tool for applications that demand factual correctness and completeness, such as target identification -- a critical process in pinpointing biological entities for disease treatment or crop enhancement. Moreover, its intuitive search interface and ability to provide accurate responses within seconds make it well-suited for time-sensitive, precision-focused research contexts. We publish the source code together with the dataset and the prompt templates used.
Read more8/7/2024