Uncovering Limitations of Large Language Models in Information Seeking from Tables
2406.04113
0
0

Abstract
Tables are recognized for their high information density and widespread usage, serving as essential sources of information. Seeking information from tables (TIS) is a crucial capability for Large Language Models (LLMs), serving as the foundation of knowledge-based Q&A systems. However, this field presently suffers from an absence of thorough and reliable evaluation. This paper introduces a more reliable benchmark for Table Information Seeking (TabIS). To avoid the unreliable evaluation caused by text similarity-based metrics, TabIS adopts a single-choice question format (with two options per question) instead of a text generation format. We establish an effective pipeline for generating options, ensuring their difficulty and quality. Experiments conducted on 12 LLMs reveal that while the performance of GPT-4-turbo is marginally satisfactory, both other proprietary and open-source models perform inadequately. Further analysis shows that LLMs exhibit a poor understanding of table structures, and struggle to balance between TIS performance and robustness against pseudo-relevant tables (common in retrieval-augmented systems). These findings uncover the limitations and potential challenges of LLMs in seeking information from tables. We release our data and code to facilitate further research in this field.
Create account to get full access
Overview
- This paper explores the limitations of large language models (LLMs) in information seeking from tabular data.
- The authors introduce the TabIS benchmark, a dataset designed to evaluate the ability of LLMs to extract and reason about information in tables.
- The paper presents experiments comparing the performance of LLMs on the TabIS benchmark to that of specialized table-based models.
Plain English Explanation
The researchers in this paper wanted to understand how well large language models, like those used in chatbots and digital assistants, can handle information that is presented in tables. Tables are a common way to organize and display data, but they have a structured format that is different from the freeform text that language models are usually trained on.
To test the language models' abilities, the researchers created a new benchmark called TabIS. This benchmark includes a variety of tables on different topics, along with questions that require extracting specific information from the tables or reasoning about the data. By having language models attempt to answer these questions, the researchers could see where the models succeeded and where they struggled.
The experiments showed that while language models can sometimes answer questions about tables, they often perform worse than specialized table-reasoning models that are designed to work directly with tabular data. This suggests that language models have limitations when it comes to understanding and working with information presented in a structured format like a table.
Technical Explanation
The paper introduces the TabIS (Table Information Seeking) benchmark, which is designed to evaluate the ability of large language models (LLMs) to extract and reason about information in tables. The benchmark consists of a diverse set of tables covering topics such as geography, sports, and finance, along with associated questions that require understanding the table contents.
The authors conduct experiments comparing the performance of several LLMs, including GPT-3, T5, and BART, on the TabIS benchmark. They also compare the LLM results to those of specialized table-based models, such as TabSQLify and OpenTAB, which are designed to reason directly with tabular data.
The results show that while LLMs can achieve reasonable performance on the TabIS benchmark, they are generally outperformed by the specialized table-based models. The authors attribute this to the inherent challenges LLMs face in understanding and reasoning about the structured format of tables, which differs from the freeform text they are typically trained on.
Critical Analysis
The paper provides valuable insights into the limitations of large language models when it comes to information seeking from tables. The authors acknowledge that while LLMs have shown impressive capabilities in various natural language processing tasks, their performance on tabular data tasks lags behind that of specialized models.
One potential limitation of the research is the scope of the TabIS benchmark. While the dataset covers a range of topics, it may not capture the full complexity and diversity of real-world tabular data that language models would need to handle. Additionally, the paper does not explore the potential reasons why LLMs struggle with tables, such as their inability to effectively leverage the structural and relational information inherent in tabular data.
Further research could investigate ways to enhance the reasoning capabilities of LLMs when it comes to tables, potentially by incorporating table-specific training or architectural modifications. Exploring the potential of LLMs for predictive analytics on tabular data could also be a fruitful area of study.
Conclusion
This paper uncovers significant limitations in the ability of large language models to effectively extract and reason about information presented in tables. The introduction of the TabIS benchmark and the comparative evaluation of LLMs and specialized table-based models provide important insights into the challenges faced by LLMs in working with structured data formats.
The findings suggest that while LLMs have made remarkable advancements in various natural language processing tasks, they still face limitations when it comes to conducting advanced text analytics on tabular data. Addressing these limitations could be crucial for expanding the capabilities of LLMs and advancing them as open-ended problem solvers in real-world applications that involve structured data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey
Xi Fang, Weijie Xu, Fiona Anting Tan, Jiani Zhang, Ziqing Hu, Yanjun Qi, Scott Nickleach, Diego Socolinsky, Srinivasan Sengamedu, Christos Faloutsos
0
0
Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques, metrics, datasets, models, and optimization approaches in this research domain. This survey aims to address this gap by consolidating recent progress in these areas, offering a thorough survey and taxonomy of the datasets, metrics, and methodologies utilized. It identifies strengths, limitations, unexplored territories, and gaps in the existing literature, while providing some insights for future research directions in this vital and rapidly evolving field. It also provides relevant code and datasets references. Through this comprehensive review, we hope to provide interested readers with pertinent references and insightful perspectives, empowering them with the necessary tools and knowledge to effectively navigate and address the prevailing challenges in the field.
6/26/2024
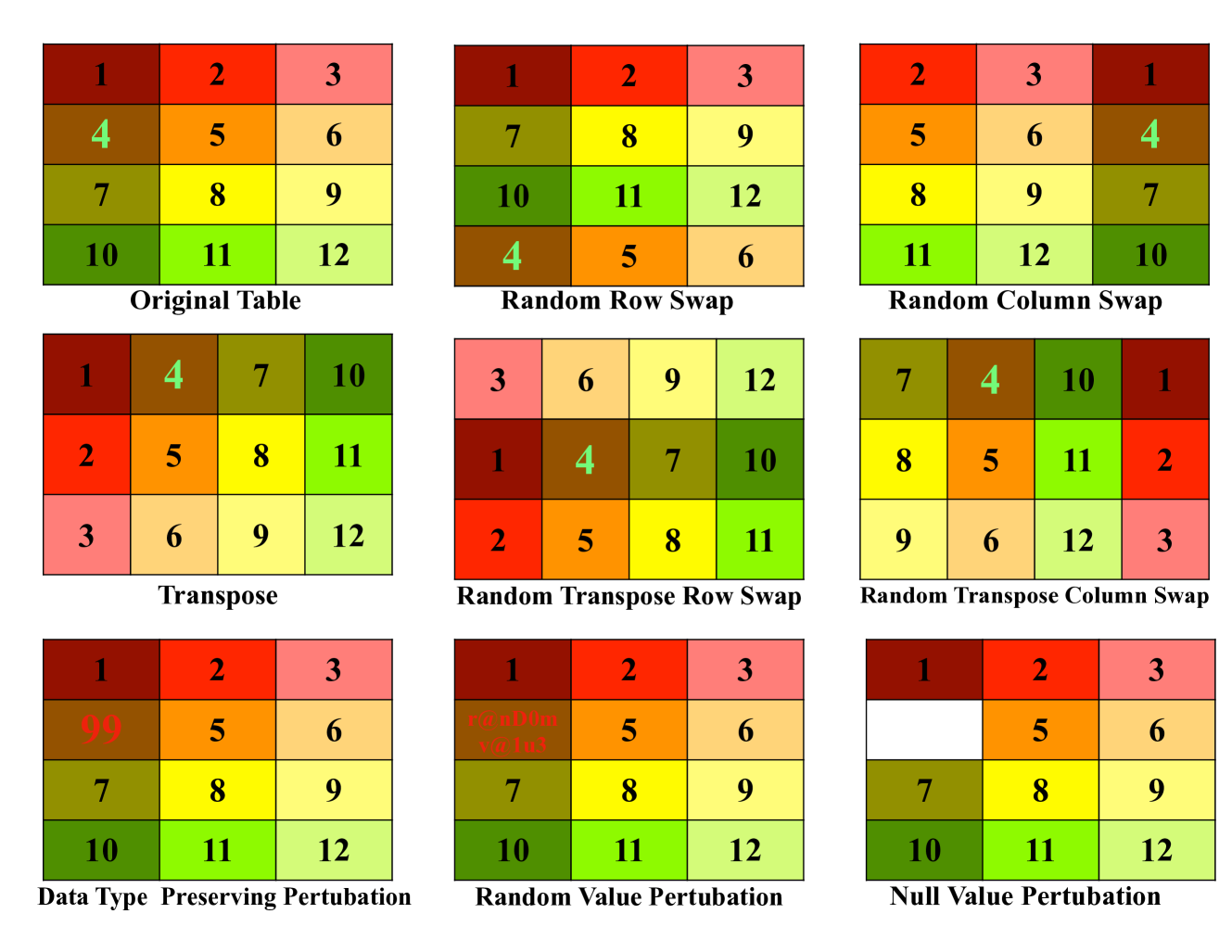
On the Robustness of Language Models for Tabular Question Answering
Kushal Raj Bhandari, Sixue Xing, Soham Dan, Jianxi Gao
0
0
Large Language Models (LLMs), originally shown to ace various text comprehension tasks have also remarkably been shown to tackle table comprehension tasks without specific training. While previous research has explored LLM capabilities with tabular dataset tasks, our study assesses the influence of $textit{in-context learning}$,$ textit{model scale}$, $textit{instruction tuning}$, and $textit{domain biases}$ on Tabular Question Answering (TQA). We evaluate the robustness of LLMs on Wikipedia-based $textbf{WTQ}$ and financial report-based $textbf{TAT-QA}$ TQA datasets, focusing on their ability to robustly interpret tabular data under various augmentations and perturbations. Our findings indicate that instructions significantly enhance performance, with recent models like Llama3 exhibiting greater robustness over earlier versions. However, data contamination and practical reliability issues persist, especially with WTQ. We highlight the need for improved methodologies, including structure-aware self-attention mechanisms and better handling of domain-specific tabular data, to develop more reliable LLMs for table comprehension.
6/19/2024
TabSQLify: Enhancing Reasoning Capabilities of LLMs Through Table Decomposition
Md Mahadi Hasan Nahid, Davood Rafiei
0
0
Table reasoning is a challenging task that requires understanding both natural language questions and structured tabular data. Large language models (LLMs) have shown impressive capabilities in natural language understanding and generation, but they often struggle with large tables due to their limited input length. In this paper, we propose TabSQLify, a novel method that leverages text-to-SQL generation to decompose tables into smaller and relevant sub-tables, containing only essential information for answering questions or verifying statements, before performing the reasoning task. In our comprehensive evaluation on four challenging datasets, our approach demonstrates comparable or superior performance compared to prevailing methods reliant on full tables as input. Moreover, our method can reduce the input context length significantly, making it more scalable and efficient for large-scale table reasoning applications. Our method performs remarkably well on the WikiTQ benchmark, achieving an accuracy of 64.7%. Additionally, on the TabFact benchmark, it achieves a high accuracy of 79.5%. These results surpass other LLM-based baseline models on gpt-3.5-turbo (chatgpt). TabSQLify can reduce the table size significantly alleviating the computational load on LLMs when handling large tables without compromising performance.
4/17/2024
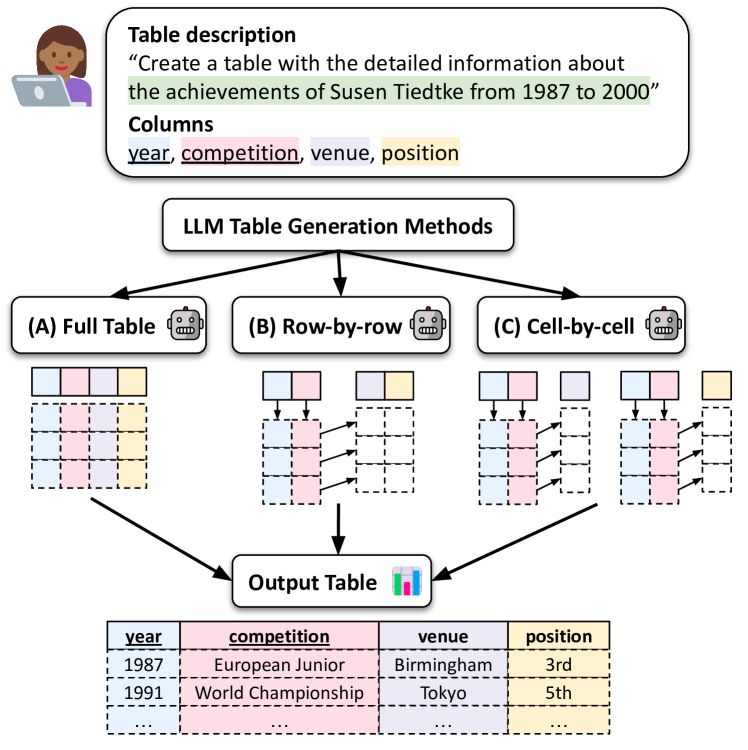
Generating Tables from the Parametric Knowledge of Language Models
Yevgeni Berkovitch, Oren Glickman, Amit Somech, Tomer Wolfson
0
0
We explore generating factual and accurate tables from the parametric knowledge of large language models (LLMs). While LLMs have demonstrated impressive capabilities in recreating knowledge bases and generating free-form text, we focus on generating structured tabular data, which is crucial in domains like finance and healthcare. We examine the table generation abilities of four state-of-the-art LLMs: GPT-3.5, GPT-4, Llama2-13B, and Llama2-70B, using three prompting methods for table generation: (a) full-table, (b) row-by-row; (c) cell-by-cell. For evaluation, we introduce a novel benchmark, WikiTabGen which contains 100 curated Wikipedia tables. Tables are further processed to ensure their factual correctness and manually annotated with short natural language descriptions. Our findings reveal that table generation remains a challenge, with GPT-4 reaching the highest accuracy at 19.6%. Our detailed analysis sheds light on how various table properties, such as size, table popularity, and numerical content, influence generation performance. This work highlights the unique challenges in LLM-based table generation and provides a solid evaluation framework for future research. Our code, prompts and data are all publicly available: https://github.com/analysis-bots/WikiTabGen
6/18/2024