Identifying Factual Inconsistencies in Summaries: Grounding Model Inference via Task Taxonomy
2402.12821
0
0

Abstract
Factual inconsistencies pose a significant hurdle for the faithful summarization by generative models. While a major direction to enhance inconsistency detection is to derive stronger Natural Language Inference (NLI) models, we propose an orthogonal aspect that underscores the importance of incorporating task-specific taxonomy into the inference. To this end, we consolidate key error types of inconsistent facts in summaries, and incorporate them to facilitate both the zero-shot and supervised paradigms of LLMs. Extensive experiments on ten datasets of five distinct domains suggest that, zero-shot LLM inference could benefit from the explicit solution space depicted by the error type taxonomy, and achieves state-of-the-art performance overall, surpassing specialized non-LLM baselines, as well as recent LLM baselines. We further distill models that fuse the taxonomy into parameters through our designed prompt completions and supervised training strategies, efficiently substituting state-of-the-art zero-shot inference with much larger LLMs.
Create account to get full access
Overview
• This paper focuses on the problem of identifying factual inconsistencies in language model-generated summaries.
• The researchers propose a novel approach to detect and mitigate factual inconsistencies in summarization models, particularly those powered by large language models (LLMs).
• The goal is to enable more effective and reliable utilization of LLMs for summarization tasks, which have become increasingly important in the era of information overload.
Plain English Explanation
The paper addresses a critical challenge in the field of natural language processing: ensuring the factual accuracy and consistency of summaries generated by powerful language models. As these models become more advanced, they are increasingly used to automatically summarize large amounts of text, such as news articles or research papers. However, there is a risk that these summaries may contain factual errors or contradictions, which could be misleading or even harmful if relied upon.
To address this, the researchers have developed a new method to identify and correct factual inconsistencies in language model-generated summaries. The key idea is to leverage the language model's own knowledge and capabilities to detect when the summary contains information that is contradictory or unsupported by the original text. By doing so, they aim to improve the reliability and trustworthiness of these summaries, making them more useful for a wide range of applications, from FIZZ: Factual Inconsistency Detection by Zoom Summary to Analyzing LLM Behavior in Dialogue Summarization: Unveiling Circumstantial and Factual Inconsistencies.
Technical Explanation
The paper presents a novel approach to detecting and mitigating factual inconsistencies in language model-generated summaries. The key components of their method include:
-
Factual Consistency Scorer: The researchers developed a factual consistency scorer that can assess the degree of inconsistency between a summary and the original text. This scorer leverages the language model's own knowledge to identify contradictions or unsupported claims in the summary.
-
Iterative Refinement: By repeatedly applying the factual consistency scorer and making targeted edits to the summary, the researchers were able to gradually improve the summary's factual consistency while preserving its informative content.
-
Evaluation on Benchmark Datasets: The researchers evaluated their approach on several benchmark datasets for summarization, including Learning to Generate Answers, Citations, and Entities via Factual Entailment and Reasoning about Concepts in LLMs: Inconsistencies Abound. The results demonstrate the effectiveness of their method in improving the factual consistency of language model-generated summaries.
Critical Analysis
The researchers acknowledge several limitations and areas for future work:
- The current approach relies on the language model's own knowledge, which may be biased or incomplete. Exploring ways to incorporate external knowledge sources could further improve factual consistency.
- The iterative refinement process can be computationally expensive, particularly for longer input texts. Developing more efficient algorithms or leveraging Towards Logically Consistent Language Models via Probabilistic techniques could make the method more scalable.
- The evaluation focused on factual consistency, but other aspects of summary quality, such as coherence and relevance, were not explicitly addressed. Incorporating a more holistic assessment of summary quality would be a valuable direction for future research.
Conclusion
This paper presents a significant step forward in ensuring the factual reliability of language model-generated summaries. By developing a novel approach to detect and mitigate factual inconsistencies, the researchers have made an important contribution to the field of natural language processing. Their work has the potential to enable more effective and trustworthy utilization of large language models, which will be increasingly crucial as these models become more pervasive in summarization and other high-stakes applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Factual Dialogue Summarization via Learning from Large Language Models
Rongxin Zhu, Jey Han Lau, Jianzhong Qi
0
0
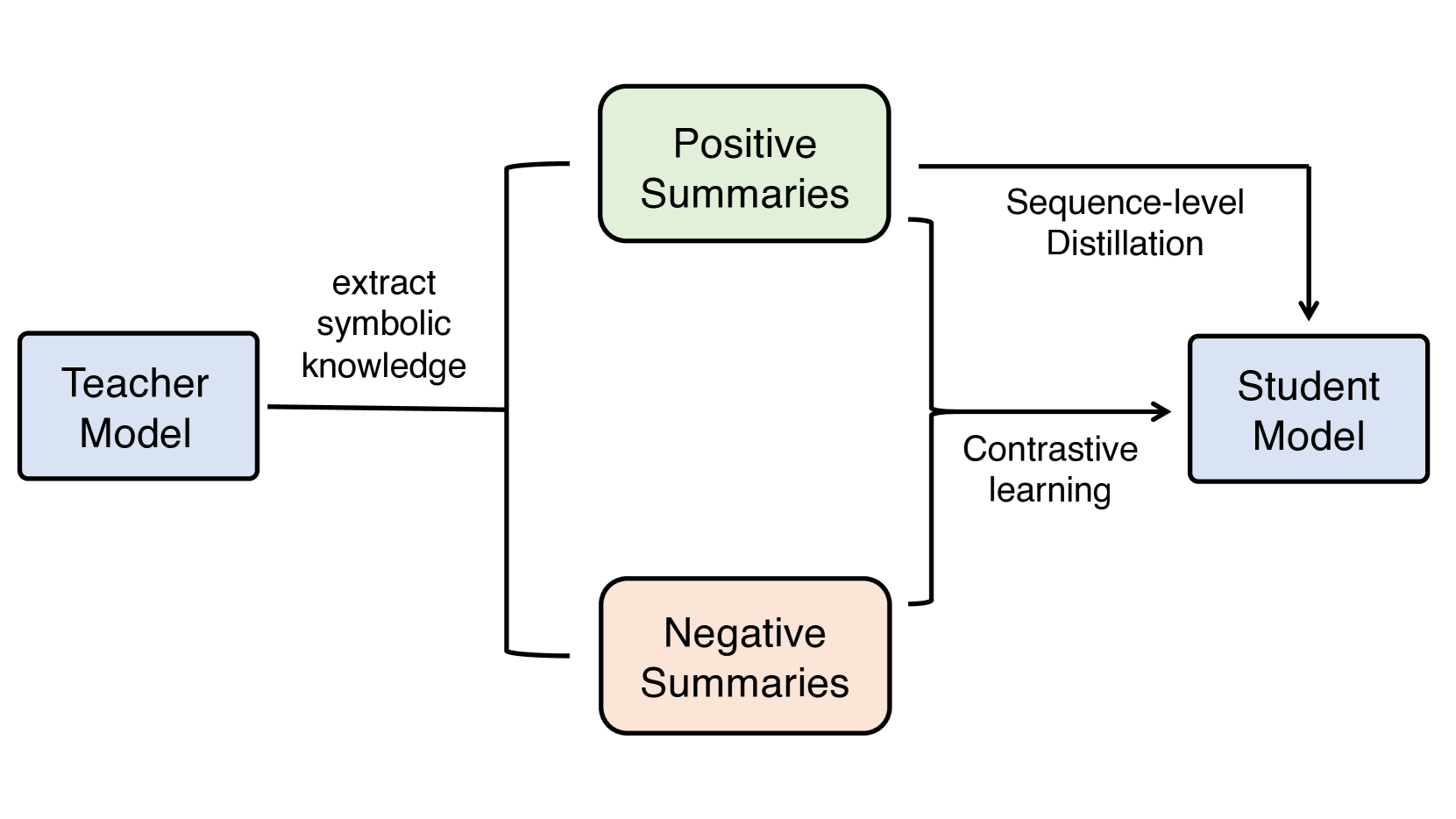
Factual consistency is an important quality in dialogue summarization. Large language model (LLM)-based automatic text summarization models generate more factually consistent summaries compared to those by smaller pretrained language models, but they face deployment challenges in real-world applications due to privacy or resource constraints. In this paper, we investigate the use of symbolic knowledge distillation to improve the factual consistency of smaller pretrained models for dialogue summarization. We employ zero-shot learning to extract symbolic knowledge from LLMs, generating both factually consistent (positive) and inconsistent (negative) summaries. We then apply two contrastive learning objectives on these summaries to enhance smaller summarization models. Experiments with BART, PEGASUS, and Flan-T5 indicate that our approach surpasses strong baselines that rely on complex data augmentation strategies. Our approach achieves better factual consistency while maintaining coherence, fluency, and relevance, as confirmed by various automatic evaluation metrics. We also provide access to the data and code to facilitate future research.
6/24/2024

Learning to Generate Answers with Citations via Factual Consistency Models
Rami Aly, Zhiqiang Tang, Samson Tan, George Karypis
0
0
Large Language Models (LLMs) frequently hallucinate, impeding their reliability in mission-critical situations. One approach to address this issue is to provide citations to relevant sources alongside generated content, enhancing the verifiability of generations. However, citing passages accurately in answers remains a substantial challenge. This paper proposes a weakly-supervised fine-tuning method leveraging factual consistency models (FCMs). Our approach alternates between generating texts with citations and supervised fine-tuning with FCM-filtered citation data. Focused learning is integrated into the objective, directing the fine-tuning process to emphasise the factual unit tokens, as measured by an FCM. Results on the ALCE few-shot citation benchmark with various instruction-tuned LLMs demonstrate superior performance compared to in-context learning, vanilla supervised fine-tuning, and state-of-the-art methods, with an average improvement of $34.1$, $15.5$, and $10.5$ citation F$_1$ points, respectively. Moreover, in a domain transfer setting we show that the obtained citation generation ability robustly transfers to unseen datasets. Notably, our citation improvements contribute to the lowest factual error rate across baselines.
6/21/2024

FIZZ: Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document
Joonho Yang, Seunghyun Yoon, Byeongjeong Kim, Hwanhee Lee
0
0
Through the advent of pre-trained language models, there have been notable advancements in abstractive summarization systems. Simultaneously, a considerable number of novel methods for evaluating factual consistency in abstractive summarization systems has been developed. But these evaluation approaches incorporate substantial limitations, especially on refinement and interpretability. In this work, we propose highly effective and interpretable factual inconsistency detection method metric Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document for abstractive summarization systems that is based on fine-grained atomic facts decomposition. Moreover, we align atomic facts decomposed from the summary with the source document through adaptive granularity expansion. These atomic facts represent a more fine-grained unit of information, facilitating detailed understanding and interpretability of the summary's factual inconsistency. Experimental results demonstrate that our proposed factual consistency checking system significantly outperforms existing systems.
4/19/2024

Analyzing LLM Behavior in Dialogue Summarization: Unveiling Circumstantial Hallucination Trends
Sanjana Ramprasad, Elisa Ferracane, Zachary C. Lipton
0
0
Recent advancements in large language models (LLMs) have considerably advanced the capabilities of summarization systems. However, they continue to face concerns about hallucinations. While prior work has evaluated LLMs extensively in news domains, most evaluation of dialogue summarization has focused on BART-based models, leaving a gap in our understanding of their faithfulness. Our work benchmarks the faithfulness of LLMs for dialogue summarization, using human annotations and focusing on identifying and categorizing span-level inconsistencies. Specifically, we focus on two prominent LLMs: GPT-4 and Alpaca-13B. Our evaluation reveals subtleties as to what constitutes a hallucination: LLMs often generate plausible inferences, supported by circumstantial evidence in the conversation, that lack direct evidence, a pattern that is less prevalent in older models. We propose a refined taxonomy of errors, coining the category of Circumstantial Inference to bucket these LLM behaviors and release the dataset. Using our taxonomy, we compare the behavioral differences between LLMs and older fine-tuned models. Additionally, we systematically assess the efficacy of automatic error detection methods on LLM summaries and find that they struggle to detect these nuanced errors. To address this, we introduce two prompt-based approaches for fine-grained error detection that outperform existing metrics, particularly for identifying Circumstantial Inference.
6/6/2024