Fairness-aware Federated Minimax Optimization with Convergence Guarantee
2307.04417
0
0

Abstract
Federated learning (FL) has garnered considerable attention due to its privacy-preserving feature. Nonetheless, the lack of freedom in managing user data can lead to group fairness issues, where models are biased towards sensitive factors such as race or gender. To tackle this issue, this paper proposes a novel algorithm, fair federated averaging with augmented Lagrangian method (FFALM), designed explicitly to address group fairness issues in FL. Specifically, we impose a fairness constraint on the training objective and solve the minimax reformulation of the constrained optimization problem. Then, we derive the theoretical upper bound for the convergence rate of FFALM. The effectiveness of FFALM in improving fairness is shown empirically on CelebA and UTKFace datasets in the presence of severe statistical heterogeneity.
Create account to get full access
Overview
- Federated learning (FL) is a machine learning technique that allows multiple devices to collaboratively train a shared model without sharing their data.
- This paper addresses the challenge of ensuring fairness in FL, where the performance of the shared model may vary across different user groups.
- The authors propose an Augmented Lagrangian Approach to handle group fairness in FL, aiming to improve the model's performance across diverse user groups.
Plain English Explanation
Federated learning is a way of training machine learning models that doesn't require all the data to be in one place. Instead, the data stays on the individual devices (like phones or computers), and the devices work together to train a shared model. This is useful because it can protect people's privacy and allow for more data to be used in training.
One problem with federated learning is that the performance of the shared model may not be equal across different groups of users. For example, the model might work well for younger users but not as well for older users. This is called a fairness issue, and it's important to address it to ensure the model is useful for everyone.
In this paper, the researchers propose a new approach to handle group fairness in federated learning. They use something called the Augmented Lagrangian Approach, which is a mathematical technique that helps balance the performance of the model across different user groups. The goal is to improve the model's performance for all users, not just some.
Technical Explanation
The paper proposes an Augmented Lagrangian Approach to address the challenge of ensuring group fairness in federated learning. The key components of the approach are:
- Group Fairness Constraint: The authors define a group fairness constraint that aims to minimize the performance gap between the best and worst-performing user groups.
- Augmented Lagrangian Optimization: They formulate the group fairness problem as a constrained optimization problem and solve it using the Augmented Lagrangian method, which iteratively updates the model parameters and the Lagrange multipliers.
- Federated Optimization: The federated optimization process coordinates the local model updates from participating devices to optimize the global model while satisfying the group fairness constraint.
The experimental results demonstrate that the proposed approach can achieve better group fairness compared to baseline methods, without significantly compromising the overall model performance.
Critical Analysis
The paper presents a novel approach to address the important issue of group fairness in federated learning. The Augmented Lagrangian Approach is a principled way to incorporate fairness constraints into the federated optimization process.
One potential limitation of the approach is that it requires defining and quantifying the group fairness constraint, which may not be straightforward in all applications. The paper uses a simple metric based on the performance gap between groups, but more sophisticated fairness measures could be explored in future work.
Additionally, the paper focuses on a single global model, but in some federated learning scenarios, it may be preferable to train multiple specialized models for different user groups. Extending the proposed approach to handle multiple models could be an interesting direction for further research.
Conclusion
This paper presents a practical solution to the problem of group fairness in federated learning. By incorporating an Augmented Lagrangian Approach into the federated optimization process, the authors demonstrate how to train a shared model that performs well across diverse user groups.
The proposed method has the potential to make federated learning more inclusive and equitable, ensuring that the benefits of this privacy-preserving machine learning technique are realized by all participants, not just a privileged few. As federated learning continues to gain traction in various applications, addressing fairness concerns will be crucial for its widespread adoption and societal impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Fair Concurrent Training of Multiple Models in Federated Learning
Marie Siew, Haoran Zhang, Jong-Ik Park, Yuezhou Liu, Yichen Ruan, Lili Su, Stratis Ioannidis, Edmund Yeh, Carlee Joe-Wong
0
0
Federated learning (FL) enables collaborative learning across multiple clients. In most FL work, all clients train a single learning task. However, the recent proliferation of FL applications may increasingly require multiple FL tasks to be trained simultaneously, sharing clients' computing and communication resources, which we call Multiple-Model Federated Learning (MMFL). Current MMFL algorithms use naive average-based client-task allocation schemes that can lead to unfair performance when FL tasks have heterogeneous difficulty levels, e.g., tasks with larger models may need more rounds and data to train. Just as naively allocating resources to generic computing jobs with heterogeneous resource needs can lead to unfair outcomes, naive allocation of clients to FL tasks can lead to unfairness, with some tasks having excessively long training times, or lower converged accuracies. Furthermore, in the FL setting, since clients are typically not paid for their training effort, we face a further challenge that some clients may not even be willing to train some tasks, e.g., due to high computational costs, which may exacerbate unfairness in training outcomes across tasks. We address both challenges by firstly designing FedFairMMFL, a difficulty-aware algorithm that dynamically allocates clients to tasks in each training round. We provide guarantees on airness and FedFairMMFL's convergence rate. We then propose a novel auction design that incentivizes clients to train multiple tasks, so as to fairly distribute clients' training efforts across the tasks. We show how our fairness-based learning and incentive mechanisms impact training convergence and finally evaluate our algorithm with multiple sets of learning tasks on real world datasets.
4/23/2024

Pursuing Overall Welfare in Federated Learning through Sequential Decision Making
Seok-Ju Hahn, Gi-Soo Kim, Junghye Lee
0
0
In traditional federated learning, a single global model cannot perform equally well for all clients. Therefore, the need to achieve the client-level fairness in federated system has been emphasized, which can be realized by modifying the static aggregation scheme for updating the global model to an adaptive one, in response to the local signals of the participating clients. Our work reveals that existing fairness-aware aggregation strategies can be unified into an online convex optimization framework, in other words, a central server's sequential decision making process. To enhance the decision making capability, we propose simple and intuitive improvements for suboptimal designs within existing methods, presenting AAggFF. Considering practical requirements, we further subdivide our method tailored for the cross-device and the cross-silo settings, respectively. Theoretical analyses guarantee sublinear regret upper bounds for both settings: $mathcal{O}(sqrt{T log{K}})$ for the cross-device setting, and $mathcal{O}(K log{T})$ for the cross-silo setting, with $K$ clients and $T$ federation rounds. Extensive experiments demonstrate that the federated system equipped with AAggFF achieves better degree of client-level fairness than existing methods in both practical settings. Code is available at https://github.com/vaseline555/AAggFF
6/3/2024

Fair Federated Learning under Domain Skew with Local Consistency and Domain Diversity
Yuhang Chen, Wenke Huang, Mang Ye
0
0
Federated learning (FL) has emerged as a new paradigm for privacy-preserving collaborative training. Under domain skew, the current FL approaches are biased and face two fairness problems. 1) Parameter Update Conflict: data disparity among clients leads to varying parameter importance and inconsistent update directions. These two disparities cause important parameters to potentially be overwhelmed by unimportant ones of dominant updates. It consequently results in significant performance decreases for lower-performing clients. 2) Model Aggregation Bias: existing FL approaches introduce unfair weight allocation and neglect domain diversity. It leads to biased model convergence objective and distinct performance among domains. We discover a pronounced directional update consistency in Federated Learning and propose a novel framework to tackle above issues. First, leveraging the discovered characteristic, we selectively discard unimportant parameter updates to prevent updates from clients with lower performance overwhelmed by unimportant parameters, resulting in fairer generalization performance. Second, we propose a fair aggregation objective to prevent global model bias towards some domains, ensuring that the global model continuously aligns with an unbiased model. The proposed method is generic and can be combined with other existing FL methods to enhance fairness. Comprehensive experiments on Digits and Office-Caltech demonstrate the high fairness and performance of our method.
5/28/2024
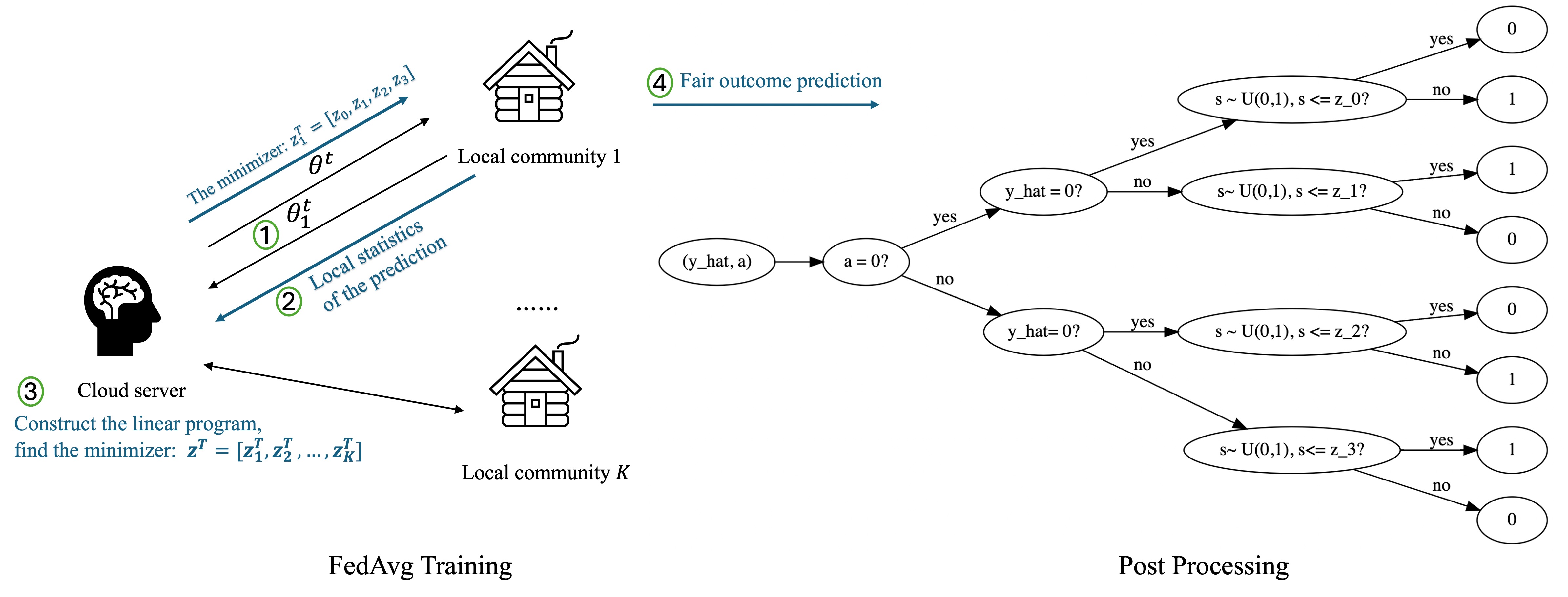
Post-Fair Federated Learning: Achieving Group and Community Fairness in Federated Learning via Post-processing
Yuying Duan, Yijun Tian, Nitesh Chawla, Michael Lemmon
0
0
Federated Learning (FL) is a distributed machine learning framework in which a set of local communities collaboratively learn a shared global model while retaining all training data locally within each community. Two notions of fairness have recently emerged as important issues for federated learning: group fairness and community fairness. Group fairness requires that a model's decisions do not favor any particular group based on a set of legally protected attributes such as race or gender. Community fairness requires that global models exhibit similar levels of performance (accuracy) across all collaborating communities. Both fairness concepts can coexist within an FL framework, but the existing literature has focused on either one concept or the other. This paper proposes and analyzes a post-processing fair federated learning (FFL) framework called post-FFL. Post-FFL uses a linear program to simultaneously enforce group and community fairness while maximizing the utility of the global model. Because Post-FFL is a post-processing approach, it can be used with existing FL training pipelines whose convergence properties are well understood. This paper uses post-FFL on real-world datasets to mimic how hospital networks, for example, use federated learning to deliver community health care. Theoretical results bound the accuracy lost when post-FFL enforces both notion of fairness. Experimental results illustrate that post-FFL simultaneously improves both group and community fairness in FL. Moreover, post-FFL outperforms the existing in-processing fair federated learning in terms of improving both notions of fairness, communication efficiency and computation cost.
5/29/2024