Fair Concurrent Training of Multiple Models in Federated Learning
2404.13841
0
0

Abstract
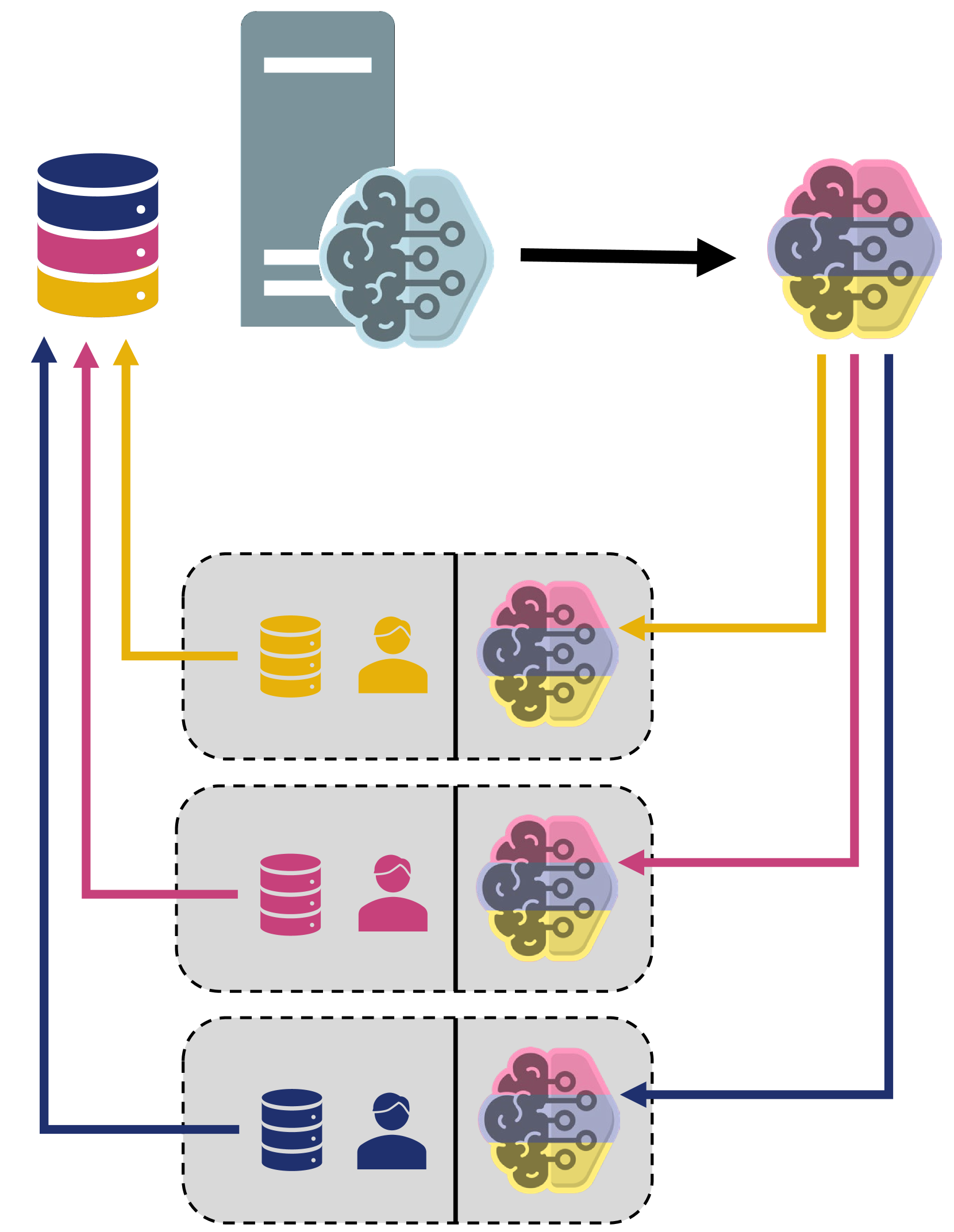
Federated learning (FL) enables collaborative learning across multiple clients. In most FL work, all clients train a single learning task. However, the recent proliferation of FL applications may increasingly require multiple FL tasks to be trained simultaneously, sharing clients' computing and communication resources, which we call Multiple-Model Federated Learning (MMFL). Current MMFL algorithms use naive average-based client-task allocation schemes that can lead to unfair performance when FL tasks have heterogeneous difficulty levels, e.g., tasks with larger models may need more rounds and data to train. Just as naively allocating resources to generic computing jobs with heterogeneous resource needs can lead to unfair outcomes, naive allocation of clients to FL tasks can lead to unfairness, with some tasks having excessively long training times, or lower converged accuracies. Furthermore, in the FL setting, since clients are typically not paid for their training effort, we face a further challenge that some clients may not even be willing to train some tasks, e.g., due to high computational costs, which may exacerbate unfairness in training outcomes across tasks. We address both challenges by firstly designing FedFairMMFL, a difficulty-aware algorithm that dynamically allocates clients to tasks in each training round. We provide guarantees on airness and FedFairMMFL's convergence rate. We then propose a novel auction design that incentivizes clients to train multiple tasks, so as to fairly distribute clients' training efforts across the tasks. We show how our fairness-based learning and incentive mechanisms impact training convergence and finally evaluate our algorithm with multiple sets of learning tasks on real world datasets.
Create account to get full access
Overview
- This paper addresses the challenge of fair concurrent training of multiple machine learning models in a federated learning setup.
- Federated learning allows multiple clients to collaboratively train a shared model without sharing their raw data.
- The paper proposes a fair resource allocation approach to ensure that multiple models are trained concurrently without one model dominating the training process.
- It also introduces an incentive mechanism to motivate clients to participate in the fair training of multiple models.
Plain English Explanation
In a typical machine learning scenario, a single model is trained on data from various sources. However, in some cases, there may be a need to train multiple models simultaneously, each targeting a different task or audience. This is known as multi-model federated learning (MMFL).
The challenge with MMFL is ensuring that the training process is fair and equitable, so that no single model dominates the training. The paper proposes a solution to this problem by introducing a fair resource allocation approach. This means that the available computing resources, such as processing power and memory, are distributed fairly among the different models being trained.
The paper also includes an incentive mechanism to encourage clients (the entities that contribute data for training) to participate in the fair training of multiple models. This is important because clients may have a preference for one model over another, and without the right incentives, they may be less willing to contribute to the training of less favored models.
By addressing these challenges, the paper aims to enable the concurrent and fair training of multiple models in a federated learning setting, which can be beneficial in a wide range of applications, such as personalized healthcare, recommendation systems, and edge computing.
Technical Explanation
The paper proposes a Fair Concurrent Training of Multiple Models in Federated Learning approach to address the research challenges in Multi-Model Federated Learning (MMFL).
The key elements of the proposed approach are:
-
Fair Resource Allocation: The paper introduces a fair resource allocation mechanism to distribute the available computing resources, such as processing power and memory, among the different models being trained. This ensures that no single model dominates the training process.
-
Incentive Mechanism: The paper also proposes an incentive mechanism to motivate clients to participate in the fair training of multiple models. This is crucial, as clients may have a preference for one model over another, and without the right incentives, they may be less willing to contribute to the training of less favored models.
The authors evaluate their approach through extensive experiments, comparing it to federated distillation and multi-modal federated learning techniques. The results demonstrate the effectiveness of the proposed fair resource allocation and incentive mechanisms in ensuring the concurrent and fair training of multiple models in a federated learning setting.
Critical Analysis
The paper presents a valuable contribution to the field of federated learning, addressing the important challenge of fair concurrent training of multiple models. The proposed approach seems well-designed and the experimental results are promising.
However, the paper does not extensively discuss the potential limitations or caveats of the proposed approach. For example, it would be interesting to understand how the fair resource allocation and incentive mechanisms scale as the number of models or clients increases, or how the approach handles heterogeneous client capabilities and data distributions.
Additionally, the paper could benefit from a more in-depth discussion of the potential real-world applications and implications of the proposed techniques, as well as any ethical considerations or potential biases that may arise in a multi-model federated learning setting.
Conclusion
This paper presents a novel approach to address the challenge of fair concurrent training of multiple models in a federated learning setup. The proposed fair resource allocation and incentive mechanisms aim to ensure that multiple models are trained fairly and that clients are motivated to participate in the training of all models, not just their preferred ones.
The technical evaluation demonstrates the effectiveness of the proposed approach, and the insights gained from this research have the potential to advance the field of federated learning and enable a wide range of applications that require the concurrent training of multiple models. As the field of federated learning continues to evolve, addressing challenges like the one tackled in this paper will be crucial for realizing the full potential of this paradigm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

FedAST: Federated Asynchronous Simultaneous Training
Baris Askin, Pranay Sharma, Carlee Joe-Wong, Gauri Joshi
0
0
Federated Learning (FL) enables edge devices or clients to collaboratively train machine learning (ML) models without sharing their private data. Much of the existing work in FL focuses on efficiently learning a model for a single task. In this paper, we study simultaneous training of multiple FL models using a common set of clients. The few existing simultaneous training methods employ synchronous aggregation of client updates, which can cause significant delays because large models and/or slow clients can bottleneck the aggregation. On the other hand, a naive asynchronous aggregation is adversely affected by stale client updates. We propose FedAST, a buffered asynchronous federated simultaneous training algorithm that overcomes bottlenecks from slow models and adaptively allocates client resources across heterogeneous tasks. We provide theoretical convergence guarantees for FedAST for smooth non-convex objective functions. Extensive experiments over multiple real-world datasets demonstrate that our proposed method outperforms existing simultaneous FL approaches, achieving up to 46.0% reduction in time to train multiple tasks to completion.
6/4/2024
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024
📊
Multi-level Personalized Federated Learning on Heterogeneous and Long-Tailed Data
Rongyu Zhang, Yun Chen, Chenrui Wu, Fangxin Wang, Bo Li
0
0
Federated learning (FL) offers a privacy-centric distributed learning framework, enabling model training on individual clients and central aggregation without necessitating data exchange. Nonetheless, FL implementations often suffer from non-i.i.d. and long-tailed class distributions across mobile applications, e.g., autonomous vehicles, which leads models to overfitting as local training may converge to sub-optimal. In our study, we explore the impact of data heterogeneity on model bias and introduce an innovative personalized FL framework, Multi-level Personalized Federated Learning (MuPFL), which leverages the hierarchical architecture of FL to fully harness computational resources at various levels. This framework integrates three pivotal modules: Biased Activation Value Dropout (BAVD) to mitigate overfitting and accelerate training; Adaptive Cluster-based Model Update (ACMU) to refine local models ensuring coherent global aggregation; and Prior Knowledge-assisted Classifier Fine-tuning (PKCF) to bolster classification and personalize models in accord with skewed local data with shared knowledge. Extensive experiments on diverse real-world datasets for image classification and semantic segmentation validate that MuPFL consistently outperforms state-of-the-art baselines, even under extreme non-i.i.d. and long-tail conditions, which enhances accuracy by as much as 7.39% and accelerates training by up to 80% at most, marking significant advancements in both efficiency and effectiveness.
5/13/2024

Fairness-aware Federated Minimax Optimization with Convergence Guarantee
Gerry Windiarto Mohamad Dunda, Shenghui Song
0
0
Federated learning (FL) has garnered considerable attention due to its privacy-preserving feature. Nonetheless, the lack of freedom in managing user data can lead to group fairness issues, where models are biased towards sensitive factors such as race or gender. To tackle this issue, this paper proposes a novel algorithm, fair federated averaging with augmented Lagrangian method (FFALM), designed explicitly to address group fairness issues in FL. Specifically, we impose a fairness constraint on the training objective and solve the minimax reformulation of the constrained optimization problem. Then, we derive the theoretical upper bound for the convergence rate of FFALM. The effectiveness of FFALM in improving fairness is shown empirically on CelebA and UTKFace datasets in the presence of severe statistical heterogeneity.
5/30/2024