MMFakeBench: A Mixed-Source Multimodal Misinformation Detection Benchmark for LVLMs

0

Sign in to get full access
Overview
• This paper introduces MMFakeBench, a new benchmark for evaluating the performance of large vision-language models (LVLMs) in detecting multimodal misinformation.
• The benchmark includes a diverse dataset of fake images and text from various sources, designed to challenge the capabilities of LVLMs in identifying manipulated media.
• The authors also propose a new method for teaching LVLMs to interpret multimodal information and evaluate its safety on the benchmark.
Plain English Explanation
The paper focuses on the growing problem of misinformation, where false or manipulated media, such as fake images and text, can be used to mislead people. The researchers developed a new dataset called MMFakeBench to test the ability of large language models, which are powerful AI systems capable of processing both text and images, to detect this type of misinformation.
The dataset includes a wide variety of fake images and text from different sources, designed to be challenging for the models to identify. By testing the models on this diverse set of misinformation, the researchers can better understand the strengths and weaknesses of these AI systems in combating the spread of false information.
The paper also presents a new technique for teaching these language models to better interpret the relationship between images and text, which can be crucial for detecting manipulated media. The researchers evaluate the safety of this approach to ensure it doesn't have unintended negative consequences.
Overall, the goal of this research is to develop more robust and reliable AI systems that can help combat the growing problem of misinformation, which can have serious consequences for individuals and society.
Technical Explanation
The paper introduces MMFakeBench, a new benchmark for evaluating the performance of large vision-language models (LVLMs) in detecting multimodal misinformation. The benchmark includes a diverse dataset of fake images and text from various sources, such as FineFake, MM-SafetyBench, and other custom-created examples.
The dataset is designed to challenge the capabilities of LVLMs by including a wide range of manipulated media, such as fake news articles, altered images, and misleading memes. The authors also propose a new method for teaching these models to better interpret the relationship between images and text, which can be crucial for detecting manipulated media.
The paper presents experiments evaluating the performance of various LVLM architectures on the MMFakeBench dataset, including both image-only and multimodal approaches. The results reveal the strengths and weaknesses of these models in identifying different types of misinformation, providing insights into the Achilles' heels of large language models when it comes to detecting fake media.
Critical Analysis
The MMFakeBench dataset and the proposed techniques for teaching LVLMs to interpret multimodal information represent a significant step forward in the field of misinformation detection. However, the paper acknowledges several limitations and areas for further research.
One key limitation is the potential for the dataset to become outdated as new forms of misinformation emerge. The authors suggest that the benchmark should be regularly updated to maintain its relevance and challenge the latest advancements in LVLM technology.
Additionally, the paper does not address the potential for these models to be used to generate or spread misinformation themselves. As large language models become increasingly capable of producing realistic-looking text and images, there is a risk that they could be misused for malicious purposes.
Further research is needed to explore the safety and robustness of these models, ensuring that they can be deployed responsibly to combat misinformation without inadvertently contributing to the problem.
Conclusion
The MMFakeBench benchmark and the associated techniques presented in this paper represent an important contribution to the ongoing battle against misinformation. By developing more reliable and robust LVLMs that can accurately detect manipulated media, the research has the potential to help curb the spread of false information and its harmful effects on individuals and society.
However, the paper also highlights the need for continued vigilance and innovation in this area, as the landscape of misinformation is constantly evolving. Ongoing efforts to update benchmarks, improve model safety, and explore new approaches to multimodal understanding will be crucial in the fight against the growing threat of fake news and manipulated media.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MMFakeBench: A Mixed-Source Multimodal Misinformation Detection Benchmark for LVLMs
Xuannan Liu, Zekun Li, Peipei Li, Shuhan Xia, Xing Cui, Linzhi Huang, Huaibo Huang, Weihong Deng, Zhaofeng He
Current multimodal misinformation detection (MMD) methods often assume a single source and type of forgery for each sample, which is insufficient for real-world scenarios where multiple forgery sources coexist. The lack of a benchmark for mixed-source misinformation has hindered progress in this field. To address this, we introduce MMFakeBench, the first comprehensive benchmark for mixed-source MMD. MMFakeBench includes 3 critical sources: textual veracity distortion, visual veracity distortion, and cross-modal consistency distortion, along with 12 sub-categories of misinformation forgery types. We further conduct an extensive evaluation of 6 prevalent detection methods and 15 large vision-language models (LVLMs) on MMFakeBench under a zero-shot setting. The results indicate that current methods struggle under this challenging and realistic mixed-source MMD setting. Additionally, we propose an innovative unified framework, which integrates rationales, actions, and tool-use capabilities of LVLM agents, significantly enhancing accuracy and generalization. We believe this study will catalyze future research into more realistic mixed-source multimodal misinformation and provide a fair evaluation of misinformation detection methods.
Read more8/22/2024
0
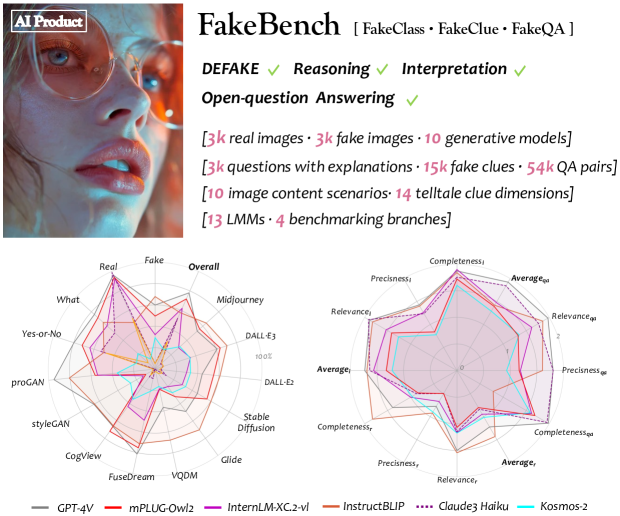
FakeBench: Uncover the Achilles' Heels of Fake Images with Large Multimodal Models
Yixuan Li, Xuelin Liu, Xiaoyang Wang, Bu Sung Lee, Shiqi Wang, Anderson Rocha, Weisi Lin
The ability to distinguish whether an image is generated by artificial intelligence (AI) is a crucial ingredient in human intelligence, usually accompanied by a complex and dialectical forensic and reasoning process. However, current fake image detection models and databases focus on binary classification without understandable explanations for the general populace. This weakens the credibility of authenticity judgment and may conceal potential model biases. Meanwhile, large multimodal models (LMMs) have exhibited immense visual-text capabilities on various tasks, bringing the potential for explainable fake image detection. Therefore, we pioneer the probe of LMMs for explainable fake image detection by presenting a multimodal database encompassing textual authenticity descriptions, the FakeBench. For construction, we first introduce a fine-grained taxonomy of generative visual forgery concerning human perception, based on which we collect forgery descriptions in human natural language with a human-in-the-loop strategy. FakeBench examines LMMs with four evaluation criteria: detection, reasoning, interpretation and fine-grained forgery analysis, to obtain deeper insights into image authenticity-relevant capabilities. Experiments on various LMMs confirm their merits and demerits in different aspects of fake image detection tasks. This research presents a paradigm shift towards transparency for the fake image detection area and reveals the need for greater emphasis on forensic elements in visual-language research and AI risk control. FakeBench will be available at https://github.com/Yixuan423/FakeBench.
Read more9/10/2024

0
MFC-Bench: Benchmarking Multimodal Fact-Checking with Large Vision-Language Models
Shengkang Wang, Hongzhan Lin, Ziyang Luo, Zhen Ye, Guang Chen, Jing Ma
Large vision-language models (LVLMs) have significantly improved multimodal reasoning tasks, such as visual question answering and image captioning. These models embed multimodal facts within their parameters, rather than relying on external knowledge bases to store factual information explicitly. However, the content discerned by LVLMs may deviate from actual facts due to inherent bias or incorrect inference. To address this issue, we introduce MFC-Bench, a rigorous and comprehensive benchmark designed to evaluate the factual accuracy of LVLMs across three tasks: Manipulation, Out-of-Context, and Veracity Classification. Through our evaluation on MFC-Bench, we benchmarked 12 diverse and representative LVLMs, uncovering that current models still fall short in multimodal fact-checking and demonstrate insensitivity to various forms of manipulated content. We hope that MFC-Bench could raise attention to the trustworthy artificial intelligence potentially assisted by LVLMs in the future. The MFC-Bench and accompanying resources are publicly accessible at https://github.com/wskbest/MFC-Bench, contributing to ongoing research in the multimodal fact-checking field.
Read more6/18/2024

0
Multimodal Misinformation Detection using Large Vision-Language Models
Sahar Tahmasebi, Eric Muller-Budack, Ralph Ewerth
The increasing proliferation of misinformation and its alarming impact have motivated both industry and academia to develop approaches for misinformation detection and fact checking. Recent advances on large language models (LLMs) have shown remarkable performance in various tasks, but whether and how LLMs could help with misinformation detection remains relatively underexplored. Most of existing state-of-the-art approaches either do not consider evidence and solely focus on claim related features or assume the evidence to be provided. Few approaches consider evidence retrieval as part of the misinformation detection but rely on fine-tuning models. In this paper, we investigate the potential of LLMs for misinformation detection in a zero-shot setting. We incorporate an evidence retrieval component into the process as it is crucial to gather pertinent information from various sources to detect the veracity of claims. To this end, we propose a novel re-ranking approach for multimodal evidence retrieval using both LLMs and large vision-language models (LVLM). The retrieved evidence samples (images and texts) serve as the input for an LVLM-based approach for multimodal fact verification (LVLM4FV). To enable a fair evaluation, we address the issue of incomplete ground truth for evidence samples in an existing evidence retrieval dataset by annotating a more complete set of evidence samples for both image and text retrieval. Our experimental results on two datasets demonstrate the superiority of the proposed approach in both evidence retrieval and fact verification tasks and also better generalization capability across dataset compared to the supervised baseline.
Read more7/22/2024