A-Bench: Are LMMs Masters at Evaluating AI-generated Images?

0

Sign in to get full access
Overview
- This paper explores the ability of large language models (LLMs) to evaluate AI-generated images.
- The researchers developed a benchmark called A-Bench to assess how well LLMs can detect and classify different types of AI-generated images.
- The study compares the performance of LLMs to human evaluators and other image evaluation models.
Plain English Explanation
The paper looks at how well large language models, which are AI systems trained on vast amounts of text data, can evaluate or judge the quality of images generated by other AI systems. The researchers created a special test called A-Bench to see how good these language models are at detecting and classifying different types of AI-generated images, like those created by image generation models like DALL-E or Stable Diffusion.
They compare the performance of the language models to how well humans can detect these AI-generated images, as well as other specialized image evaluation models. The key question is whether these powerful language models, which can understand a lot of information, are actually better than humans and other AI systems at figuring out if an image is real or artificially created.
Technical Explanation
The paper presents a new benchmark called A-Bench that is designed to evaluate the ability of large language models (LLMs) to detect and classify different types of AI-generated images. The benchmark includes a diverse dataset of real and synthetic images, covering a range of generation techniques like GANs, diffusion models, and neural rendering.
The researchers test several state-of-the-art LLMs, including GPT-3, CLIP, and DALL-E, on the A-Bench dataset. They compare the LLM performance to both human evaluators and specialized image forgery detection models like AIGIQA and MMBench. The results show that while LLMs can perform reasonably well on the benchmark, they are not necessarily "masters" at this task and struggle with certain types of AI-generated images.
Critical Analysis
The paper provides a valuable contribution by rigorously evaluating the capabilities of LLMs in an important real-world application - assessing the authenticity of AI-generated images. The A-Bench benchmark appears to be a well-designed test that covers a diverse range of image generation techniques.
However, the authors acknowledge several limitations of their study. The dataset may not fully capture the rapid progress in generative AI, and the performance of LLMs could improve as the technology evolves. Additionally, the paper does not delve into the underlying mechanisms that allow (or prevent) LLMs from effectively detecting AI-generated images.
Further research could explore how the performance of LLMs varies across different architectural choices, training regimes, and fine-tuning strategies. It would also be interesting to understand the types of visual cues and reasoning processes that allow humans to outperform LLMs on certain tasks, and how these insights could be incorporated into more robust image evaluation models.
Conclusion
The A-Bench study demonstrates that while large language models can be useful tools for evaluating AI-generated images, they are not yet the "masters" at this task. The results highlight the continued challenges in developing reliable methods for detecting synthetic media, which has important implications for fields like digital forensics, misinformation detection, and the responsible development of generative AI systems. As the field progresses, further advancements in multimodal understanding and cross-modal reasoning will be crucial for building more comprehensive and trustworthy image evaluation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A-Bench: Are LMMs Masters at Evaluating AI-generated Images?
Zicheng Zhang, Haoning Wu, Chunyi Li, Yingjie Zhou, Wei Sun, Xiongkuo Min, Zijian Chen, Xiaohong Liu, Weisi Lin, Guangtao Zhai
How to accurately and efficiently assess AI-generated images (AIGIs) remains a critical challenge for generative models. Given the high costs and extensive time commitments required for user studies, many researchers have turned towards employing large multi-modal models (LMMs) as AIGI evaluators, the precision and validity of which are still questionable. Furthermore, traditional benchmarks often utilize mostly natural-captured content rather than AIGIs to test the abilities of LMMs, leading to a noticeable gap for AIGIs. Therefore, we introduce A-Bench in this paper, a benchmark designed to diagnose whether LMMs are masters at evaluating AIGIs. Specifically, A-Bench is organized under two key principles: 1) Emphasizing both high-level semantic understanding and low-level visual quality perception to address the intricate demands of AIGIs. 2) Various generative models are utilized for AIGI creation, and various LMMs are employed for evaluation, which ensures a comprehensive validation scope. Ultimately, 2,864 AIGIs from 16 text-to-image models are sampled, each paired with question-answers annotated by human experts, and tested across 18 leading LMMs. We hope that A-Bench will significantly enhance the evaluation process and promote the generation quality for AIGIs. The benchmark is available at https://github.com/Q-Future/A-Bench.
Read more6/6/2024
0
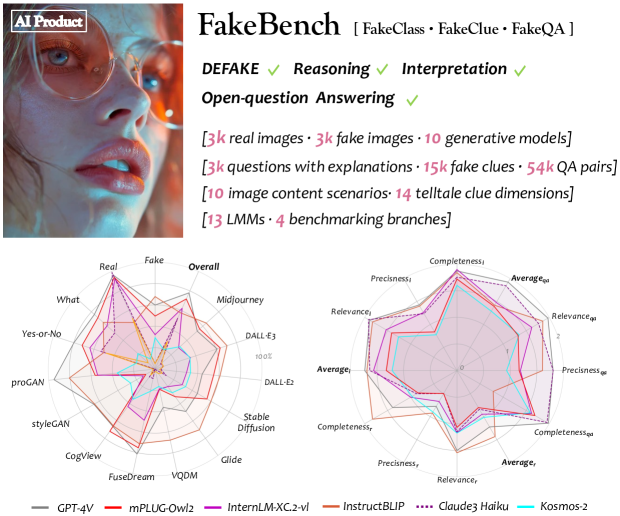
FakeBench: Uncover the Achilles' Heels of Fake Images with Large Multimodal Models
Yixuan Li, Xuelin Liu, Xiaoyang Wang, Bu Sung Lee, Shiqi Wang, Anderson Rocha, Weisi Lin
The ability to distinguish whether an image is generated by artificial intelligence (AI) is a crucial ingredient in human intelligence, usually accompanied by a complex and dialectical forensic and reasoning process. However, current fake image detection models and databases focus on binary classification without understandable explanations for the general populace. This weakens the credibility of authenticity judgment and may conceal potential model biases. Meanwhile, large multimodal models (LMMs) have exhibited immense visual-text capabilities on various tasks, bringing the potential for explainable fake image detection. Therefore, we pioneer the probe of LMMs for explainable fake image detection by presenting a multimodal database encompassing textual authenticity descriptions, the FakeBench. For construction, we first introduce a fine-grained taxonomy of generative visual forgery concerning human perception, based on which we collect forgery descriptions in human natural language with a human-in-the-loop strategy. FakeBench examines LMMs with four evaluation criteria: detection, reasoning, interpretation and fine-grained forgery analysis, to obtain deeper insights into image authenticity-relevant capabilities. Experiments on various LMMs confirm their merits and demerits in different aspects of fake image detection tasks. This research presents a paradigm shift towards transparency for the fake image detection area and reveals the need for greater emphasis on forensic elements in visual-language research and AI risk control. FakeBench will be available at https://github.com/Yixuan423/FakeBench.
Read more9/10/2024

0
GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI
Pengcheng Chen, Jin Ye, Guoan Wang, Yanjun Li, Zhongying Deng, Wei Li, Tianbin Li, Haodong Duan, Ziyan Huang, Yanzhou Su, Benyou Wang, Shaoting Zhang, Bin Fu, Jianfei Cai, Bohan Zhuang, Eric J Seibel, Junjun He, Yu Qiao
Large Vision-Language Models (LVLMs) are capable of handling diverse data types such as imaging, text, and physiological signals, and can be applied in various fields. In the medical field, LVLMs have a high potential to offer substantial assistance for diagnosis and treatment. Before that, it is crucial to develop benchmarks to evaluate LVLMs' effectiveness in various medical applications. Current benchmarks are often built upon specific academic literature, mainly focusing on a single domain, and lacking varying perceptual granularities. Thus, they face specific challenges, including limited clinical relevance, incomplete evaluations, and insufficient guidance for interactive LVLMs. To address these limitations, we developed the GMAI-MMBench, the most comprehensive general medical AI benchmark with well-categorized data structure and multi-perceptual granularity to date. It is constructed from 285 datasets across 39 medical image modalities, 18 clinical-related tasks, 18 departments, and 4 perceptual granularities in a Visual Question Answering (VQA) format. Additionally, we implemented a lexical tree structure that allows users to customize evaluation tasks, accommodating various assessment needs and substantially supporting medical AI research and applications. We evaluated 50 LVLMs, and the results show that even the advanced GPT-4o only achieves an accuracy of 52%, indicating significant room for improvement. Moreover, we identified five key insufficiencies in current cutting-edge LVLMs that need to be addressed to advance the development of better medical applications. We believe that GMAI-MMBench will stimulate the community to build the next generation of LVLMs toward GMAI.
Read more8/12/2024
🖼️
0
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Ziqiang Liu, Feiteng Fang, Xi Feng, Xinrun Du, Chenhao Zhang, Zekun Wang, Yuelin Bai, Qixuan Zhao, Liyang Fan, Chengguang Gan, Hongquan Lin, Jiaming Li, Yuansheng Ni, Haihong Wu, Yaswanth Narsupalli, Zhigang Zheng, Chengming Li, Xiping Hu, Ruifeng Xu, Xiaojun Chen, Min Yang, Jiaheng Liu, Ruibo Liu, Wenhao Huang, Ge Zhang, Shiwen Ni
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
Read more6/12/2024