Fast Training Dataset Attribution via In-Context Learning

0

Sign in to get full access
Overview
- The paper presents a method for quickly attributing the training dataset used to create a language model.
- This is done by using in-context learning, where the language model is prompted with a few examples and asked to generate relevant training data.
- The key insight is that the model's behavior when prompted in this way can reveal information about its training data.
Plain English Explanation
When a powerful language model like GPT-3 is trained on a huge amount of text data, it can be difficult to know exactly what information that model has learned and where it came from. Fast Training Dataset Attribution via In-Context Learning introduces a technique to quickly determine the source of the training data used to create such a model.
The idea is to prompt the language model with a few examples relevant to a particular topic, and then have the model generate additional text that it thinks should be part of the training data. By analyzing the model's output, the researchers can get a sense of the kind of information the model was trained on. This "in-context learning" approach allows them to quickly probe the model's knowledge and attribute it to the original training dataset.
Technical Explanation
The Fast Training Dataset Attribution via In-Context Learning paper describes an efficient method for determining the source of a language model's training data. The key insight is that a model's behavior when prompted with a few examples can reveal information about its underlying training dataset.
The proposed approach works as follows:
- Select a set of "probe" examples relevant to a particular topic or domain.
- Prompt the target language model with these examples and have it generate additional text.
- Analyze the model's output to identify patterns and characteristics that can be attributed to the original training data.
By repeatedly probing the model in this way, the researchers were able to quickly gather information about the sources and distribution of the training data used to create the model. This technique allows for faster and more efficient dataset attribution compared to previous approaches that required more extensive analysis.
The paper presents experiments demonstrating the effectiveness of this in-context learning method across different language models and datasets. The results show that it can accurately identify the key components of the training data used to create a given model.
Critical Analysis
The Fast Training Dataset Attribution via In-Context Learning paper presents a promising approach for quickly understanding the training data behind a language model. However, it's important to note some potential limitations and areas for further research:
- The method relies on the language model behaving in a predictable way when prompted with specific examples. More research is needed to understand the extent to which this holds true, especially for larger and more complex models.
- The paper focuses on relatively simple language modeling tasks. It's unclear how well the technique would scale to more sophisticated applications like question answering or text generation.
- The analysis is based on a limited set of "probe" examples. In real-world scenarios, the relevant training data may be more diverse and harder to capture with a few examples.
Overall, the in-context learning approach introduced in this paper represents an interesting step forward in understanding the inner workings of large language models. However, more research is needed to fully assess its capabilities and limitations across a wider range of applications and model architectures.
Conclusion
Fast Training Dataset Attribution via In-Context Learning presents a novel technique for quickly attributing the training data used to create a language model. By prompting the model with a few examples and analyzing its output, the researchers were able to gather insights about the sources and distribution of the underlying training data.
This approach could have important implications for understanding and interpreting the behavior of large, complex language models. Being able to quickly probe a model's knowledge and trace it back to the original training data could aid in model debugging, transparency, and responsible development of these powerful AI systems.
While the paper demonstrates the effectiveness of this in-context learning method, there are also some open questions and areas for further exploration. Nonetheless, the core ideas introduced in this work represent a valuable contribution to the ongoing efforts to make AI systems more interpretable and accountable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fast Training Dataset Attribution via In-Context Learning
Milad Fotouhi, Mohammad Taha Bahadori, Oluwaseyi Feyisetan, Payman Arabshahi, David Heckerman
We investigate the use of in-context learning and prompt engineering to estimate the contributions of training data in the outputs of instruction-tuned large language models (LLMs). We propose two novel approaches: (1) a similarity-based approach that measures the difference between LLM outputs with and without provided context, and (2) a mixture distribution model approach that frames the problem of identifying contribution scores as a matrix factorization task. Our empirical comparison demonstrates that the mixture model approach is more robust to retrieval noise in in-context learning, providing a more reliable estimation of data contributions.
Read more8/23/2024

0
In-Context Probing Approximates Influence Function for Data Valuation
Cathy Jiao, Gary Gao, Chenyan Xiong
Data valuation quantifies the value of training data, and is used for data attribution (i.e., determining the contribution of training data towards model predictions), and data selection; both of which are important for curating high-quality datasets to train large language models. In our paper, we show that data valuation through in-context probing (i.e., prompting a LLM) approximates influence functions for selecting training data. We provide a theoretical sketch on this connection based on transformer models performing implicit gradient descent on its in-context inputs. Our empirical findings show that in-context probing and gradient-based influence frameworks are similar in how they rank training data. Furthermore, fine-tuning experiments on data selected by either method reveal similar model performance.
Read more7/18/2024

0
Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
Read more4/12/2024
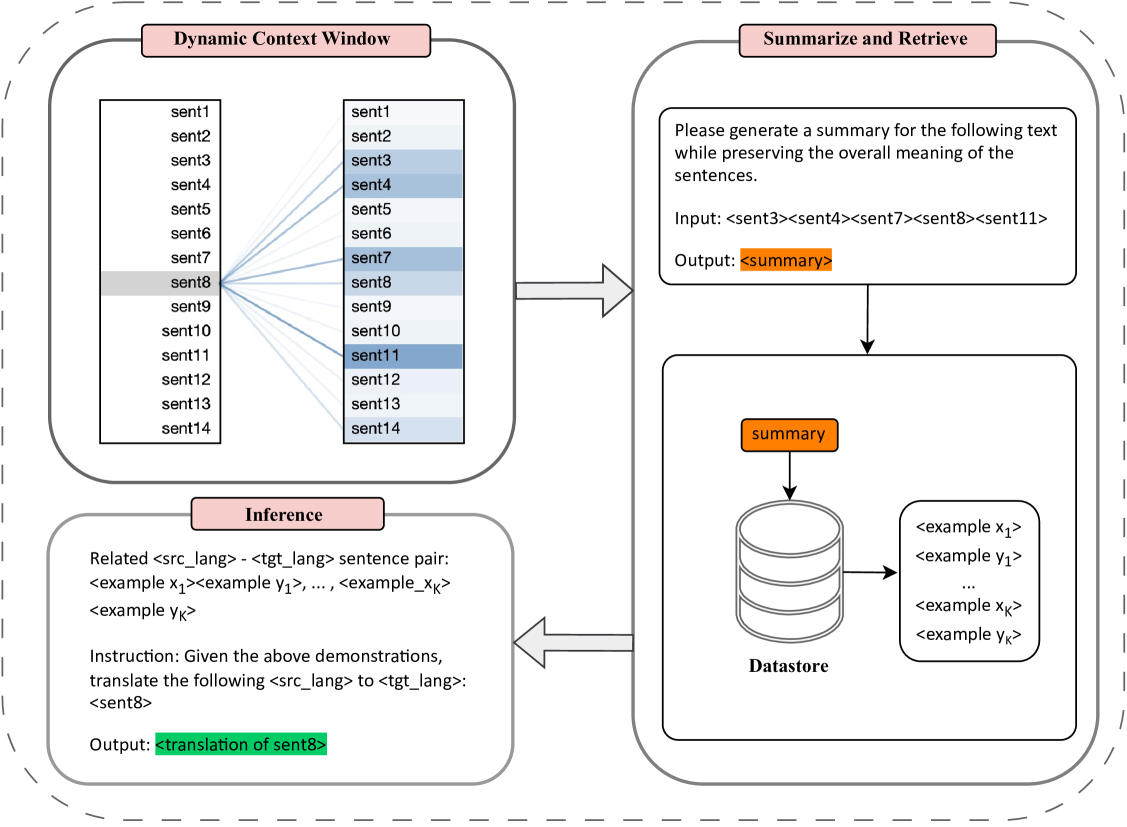
0
Efficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning
Menglong Cui, Jiangcun Du, Shaolin Zhu, Deyi Xiong
Large language models (LLMs) exhibit outstanding performance in machine translation via in-context learning. In contrast to sentence-level translation, document-level translation (DOCMT) by LLMs based on in-context learning faces two major challenges: firstly, document translations generated by LLMs are often incoherent; secondly, the length of demonstration for in-context learning is usually limited. To address these issues, we propose a Context-Aware Prompting method (CAP), which enables LLMs to generate more accurate, cohesive, and coherent translations via in-context learning. CAP takes into account multi-level attention, selects the most relevant sentences to the current one as context, and then generates a summary from these collected sentences. Subsequently, sentences most similar to the summary are retrieved from the datastore as demonstrations, which effectively guide LLMs in generating cohesive and coherent translations. We conduct extensive experiments across various DOCMT tasks, and the results demonstrate the effectiveness of our approach, particularly in zero pronoun translation (ZPT) and literary translation tasks.
Read more6/12/2024