Faster Gradient-Free Algorithms for Nonsmooth Nonconvex Stochastic Optimization
2301.06428
0
0
🛠️
Abstract
We consider the optimization problem of the form $min_{x in mathbb{R}^d} f(x) triangleq mathbb{E}
Create account to get full access
Overview
- This paper proposes a more efficient algorithm for solving a specific optimization problem, where the objective function is the expected value of a component function that is L-mean-squared Lipschitz, but potentially nonconvex and nonsmooth.
- The previously proposed gradient-free method required a high complexity to find a (δ,ε)-Goldstein stationary point of the objective function.
- The new algorithm uses stochastic recursive gradient estimators to improve the complexity compared to the previous method.
Plain English Explanation
The paper is about solving an optimization problem, which means finding the best solution to a mathematical equation. The equation has two parts: 1) a function f(x) that needs to be minimized, and 2) a set of variables x that can be adjusted to find the minimum value of f(x).
The specific problem the paper addresses is where the function f(x) is the average (or expected value) of another function F(x; ξ), which depends on both the variables x and some random input ξ. The function F(x; ξ) has some properties that make it challenging to optimize, such as being nonconvex and nonsmooth.
The paper proposes a new algorithm that uses a technique called "stochastic recursive gradient estimators" to find the minimum of f(x) more efficiently than the previously proposed gradient-free method. This means the new algorithm can find a good solution with fewer calculations or "oracle queries" compared to the older method.
Technical Explanation
The optimization problem considered in the paper is of the form:
$\min_{x \in \mathbb{R}^d} f(x) \triangleq \mathbb{E}_{\xi} [F(x; \xi)]$
where the component function $F(x; \xi)$ is L-mean-squared Lipschitz, but potentially nonconvex and nonsmooth.
The previously proposed gradient-free method required at most $\mathcal{O}(L^4 d^{3/2} \epsilon^{-4} + \Delta L^3 d^{3/2} \delta^{-1} \epsilon^{-4})$ stochastic zeroth-order oracle complexity to find a $(\delta, \epsilon)$-Goldstein stationary point of the objective function, where $\Delta = f(x_0) - \inf_{x \in \mathbb{R}^d} f(x)$ and $x_0$ is the initial point.
This paper proposes a more efficient algorithm using stochastic recursive gradient estimators, which improves the complexity to $\mathcal{O}(L^3 d^{3/2} \epsilon^{-3} + \Delta L^2 d^{3/2} \delta^{-1} \epsilon^{-3})$.
Critical Analysis
The paper provides a thorough analysis of the proposed algorithm and its theoretical guarantees. However, the authors do not discuss any potential limitations or practical considerations for implementing the algorithm in real-world scenarios.
Additionally, the paper does not compare the performance of the proposed algorithm to other state-of-the-art methods for nonconvex, nonsmooth optimization problems. It would be helpful to see how the algorithm performs on a diverse set of benchmark problems to better understand its strengths and weaknesses.
Further research could also explore the applicability of the stochastic recursive gradient estimators to other types of optimization problems, such as constrained optimization or decentralized optimization, to expand the scope and impact of the proposed technique.
Conclusion
This paper presents a new algorithm that uses stochastic recursive gradient estimators to efficiently solve a class of nonconvex, nonsmooth optimization problems. The proposed method improves upon the complexity of the previously proposed gradient-free approach, requiring fewer calculations to find a good solution.
The technical contributions of the paper are significant, as the ability to effectively optimize nonconvex, nonsmooth functions has important applications in fields like machine learning, signal processing, and control systems. The new algorithm represents a valuable addition to the toolbox of optimization techniques for these types of problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
An Algorithm with Optimal Dimension-Dependence for Zero-Order Nonsmooth Nonconvex Stochastic Optimization
Guy Kornowski, Ohad Shamir
0
0
We study the complexity of producing $(delta,epsilon)$-stationary points of Lipschitz objectives which are possibly neither smooth nor convex, using only noisy function evaluations. Recent works proposed several stochastic zero-order algorithms that solve this task, all of which suffer from a dimension-dependence of $Omega(d^{3/2})$ where $d$ is the dimension of the problem, which was conjectured to be optimal. We refute this conjecture by providing a faster algorithm that has complexity $O(ddelta^{-1}epsilon^{-3})$, which is optimal (up to numerical constants) with respect to $d$ and also optimal with respect to the accuracy parameters $delta,epsilon$, thus solving an open question due to Lin et al. (NeurIPS'22). Moreover, the convergence rate achieved by our algorithm is also optimal for smooth objectives, proving that in the nonconvex stochastic zero-order setting, nonsmooth optimization is as easy as smooth optimization. We provide algorithms that achieve the aforementioned convergence rate in expectation as well as with high probability. Our analysis is based on a simple yet powerful lemma regarding the Goldstein-subdifferential set, which allows utilizing recent advancements in first-order nonsmooth nonconvex optimization.
4/16/2024

Online Optimization Perspective on First-Order and Zero-Order Decentralized Nonsmooth Nonconvex Stochastic Optimization
Emre Sahinoglu, Shahin Shahrampour
0
0
We investigate the finite-time analysis of finding ($delta,epsilon$)-stationary points for nonsmooth nonconvex objectives in decentralized stochastic optimization. A set of agents aim at minimizing a global function using only their local information by interacting over a network. We present a novel algorithm, called Multi Epoch Decentralized Online Learning (ME-DOL), for which we establish the sample complexity in various settings. First, using a recently proposed online-to-nonconvex technique, we show that our algorithm recovers the optimal convergence rate of smooth nonconvex objectives. We then extend our analysis to the nonsmooth setting, building on properties of randomized smoothing and Goldstein-subdifferential sets. We establish the sample complexity of $O(delta^{-1}epsilon^{-3})$, which to the best of our knowledge is the first finite-time guarantee for decentralized nonsmooth nonconvex stochastic optimization in the first-order setting (without weak-convexity), matching its optimal centralized counterpart. We further prove the same rate for the zero-order oracle setting without using variance reduction.
6/4/2024
🔍
An Efficient Stochastic Algorithm for Decentralized Nonconvex-Strongly-Concave Minimax Optimization
Lesi Chen, Haishan Ye, Luo Luo
0
0
This paper studies the stochastic nonconvex-strongly-concave minimax optimization over a multi-agent network. We propose an efficient algorithm, called Decentralized Recursive gradient descEnt Ascent Method (DREAM), which achieves the best-known theoretical guarantee for finding the $epsilon$-stationary points. Concretely, it requires $mathcal{O}(min (kappa^3epsilon^{-3},kappa^2 sqrt{N} epsilon^{-2} ))$ stochastic first-order oracle (SFO) calls and $tilde{mathcal{O}}(kappa^2 epsilon^{-2})$ communication rounds, where $kappa$ is the condition number and $N$ is the total number of individual functions. Our numerical experiments also validate the superiority of DREAM over previous methods.
5/15/2024
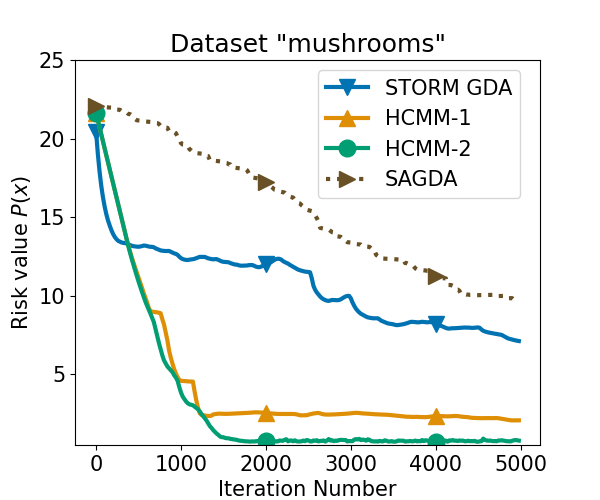
Accelerated Stochastic Min-Max Optimization Based on Bias-corrected Momentum
Haoyuan Cai, Sulaiman A. Alghunaim, Ali H. Sayed
0
0
Lower-bound analyses for nonconvex strongly-concave minimax optimization problems have shown that stochastic first-order algorithms require at least $mathcal{O}(varepsilon^{-4})$ oracle complexity to find an $varepsilon$-stationary point. Some works indicate that this complexity can be improved to $mathcal{O}(varepsilon^{-3})$ when the loss gradient is Lipschitz continuous. The question of achieving enhanced convergence rates under distinct conditions, remains unresolved. In this work, we address this question for optimization problems that are nonconvex in the minimization variable and strongly concave or Polyak-Lojasiewicz (PL) in the maximization variable. We introduce novel bias-corrected momentum algorithms utilizing efficient Hessian-vector products. We establish convergence conditions and demonstrate a lower iteration complexity of $mathcal{O}(varepsilon^{-3})$ for the proposed algorithms. The effectiveness of the method is validated through applications to robust logistic regression using real-world datasets.
6/21/2024