Faster Speech-LLaMA Inference with Multi-token Prediction

0

Sign in to get full access
Overview
- This paper proposes a method for faster speech recognition inference using large language models (LLMs) like Speech-LLaMA.
- The key idea is to perform multi-token prediction, where the model predicts multiple tokens at once instead of one token at a time.
- This can significantly speed up the inference process while maintaining high accuracy.
Plain English Explanation
The paper tackles the challenge of making speech recognition systems that use large language models (LLMs) like Speech-LLaMA run more efficiently. Typically, these models predict one word at a time, which can be slow. The researchers' solution is to have the model predict multiple words at once. This "multi-token prediction" approach leads to faster inference while still maintaining high accuracy. By predicting several words together instead of one by one, the system can complete the speech recognition task more quickly.
Technical Explanation
The paper describes a method for improving the inference speed of speech recognition models that use large language models (LLMs) like Speech-LLaMA. Normally, these models predict one token (e.g. a word) at a time, which can be computationally expensive and slow.
The key innovation is to have the model predict multiple tokens simultaneously - a process called "multi-token prediction." By predicting several words or subwords at once, the overall inference time can be significantly reduced without sacrificing accuracy.
The authors evaluate their approach on the LibriSpeech benchmark and show that it can achieve up to a 3.5x speedup in inference time compared to traditional one-token-at-a-time prediction, while maintaining similar word error rates.
Critical Analysis
The paper presents a compelling solution to the challenge of making speech recognition with LLMs more efficient. The multi-token prediction approach seems well-justified and the empirical results demonstrate its effectiveness.
However, the paper does not extensively explore the limitations or potential downsides of this method. For example, it's unclear how the multi-token prediction approach would scale to extremely long sequences or handle rare or out-of-vocabulary words. Additionally, the authors do not discuss potential bias or fairness issues that could arise from this technique.
Further research could investigate the robustness of multi-token prediction under different conditions, as well as explore ways to make the approach even more efficient or accurate. Exploring the trade-offs between speed, accuracy, and model complexity would also be valuable.
Conclusion
This paper introduces a novel technique called "multi-token prediction" that can significantly accelerate the inference time of speech recognition systems built on large language models like Speech-LLaMA, with minimal impact on accuracy. By predicting multiple tokens simultaneously instead of one at a time, the model can complete the speech recognition task much faster.
This work represents an important step towards making high-performance speech recognition more practical and efficient, which could have widespread applications in areas like voice interfaces, real-time transcription, and audio processing. Further research to refine and extend this approach could yield even greater improvements in the speed and usability of LLM-based speech recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Faster Speech-LLaMA Inference with Multi-token Prediction
Desh Raj, Gil Keren, Junteng Jia, Jay Mahadeokar, Ozlem Kalinli
Large language models (LLMs) have become proficient at solving a wide variety of tasks, including those involving multi-modal inputs. In particular, instantiating an LLM (such as LLaMA) with a speech encoder and training it on paired data imparts speech recognition (ASR) abilities to the decoder-only model, hence called Speech-LLaMA. Nevertheless, due to the sequential nature of auto-regressive inference and the relatively large decoder, Speech-LLaMA models require relatively high inference time. In this work, we propose to speed up Speech-LLaMA inference by predicting multiple tokens in the same decoding step. We explore several model architectures that enable this, and investigate their performance using threshold-based and verification-based inference strategies. We also propose a prefix-based beam search decoding method that allows efficient minimum word error rate (MWER) training for such models. We evaluate our models on a variety of public benchmarks, where they reduce the number of decoder calls by ~3.2x while maintaining or improving WER performance.
Read more9/14/2024
0
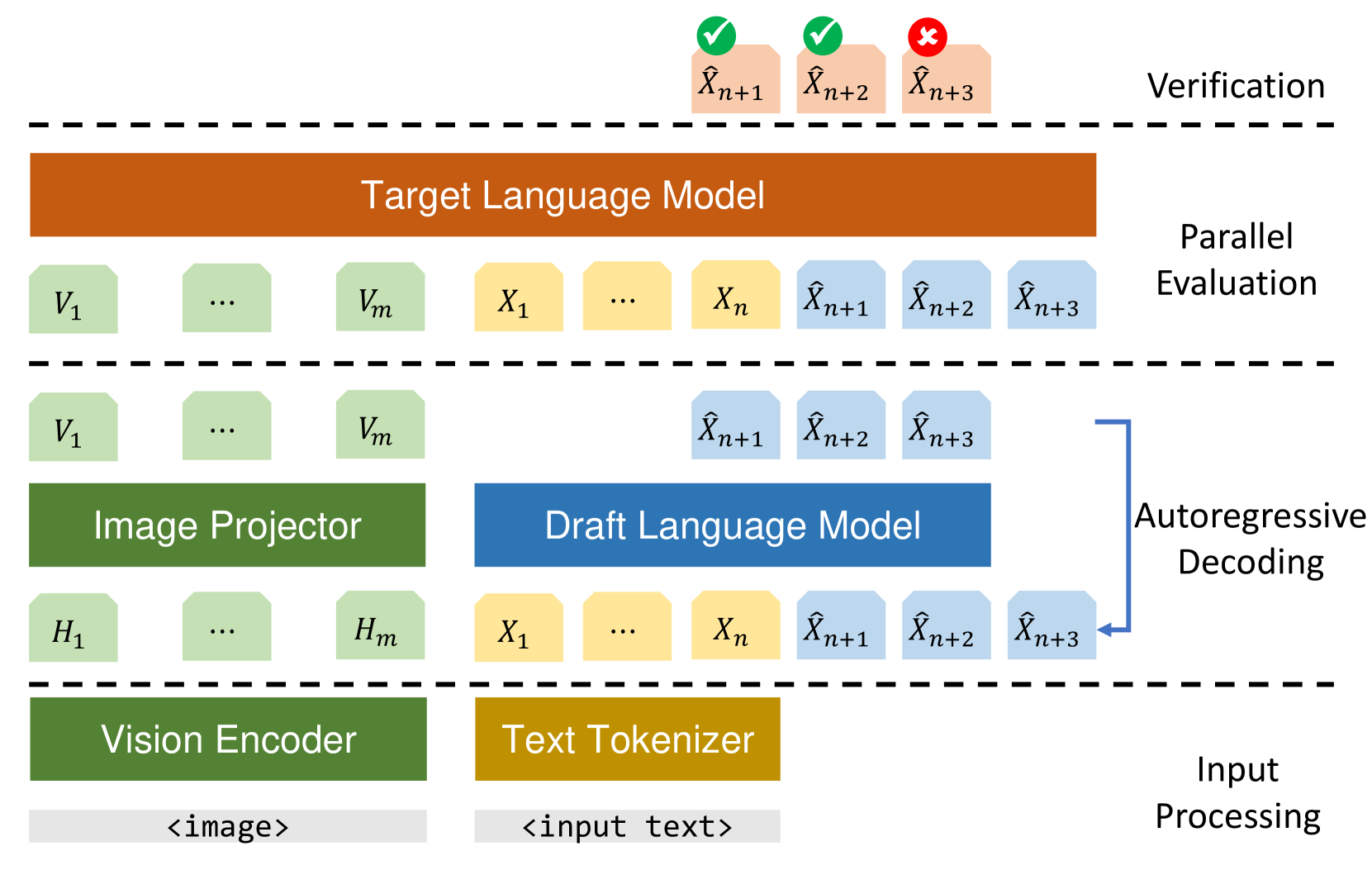
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
Read more4/16/2024
0
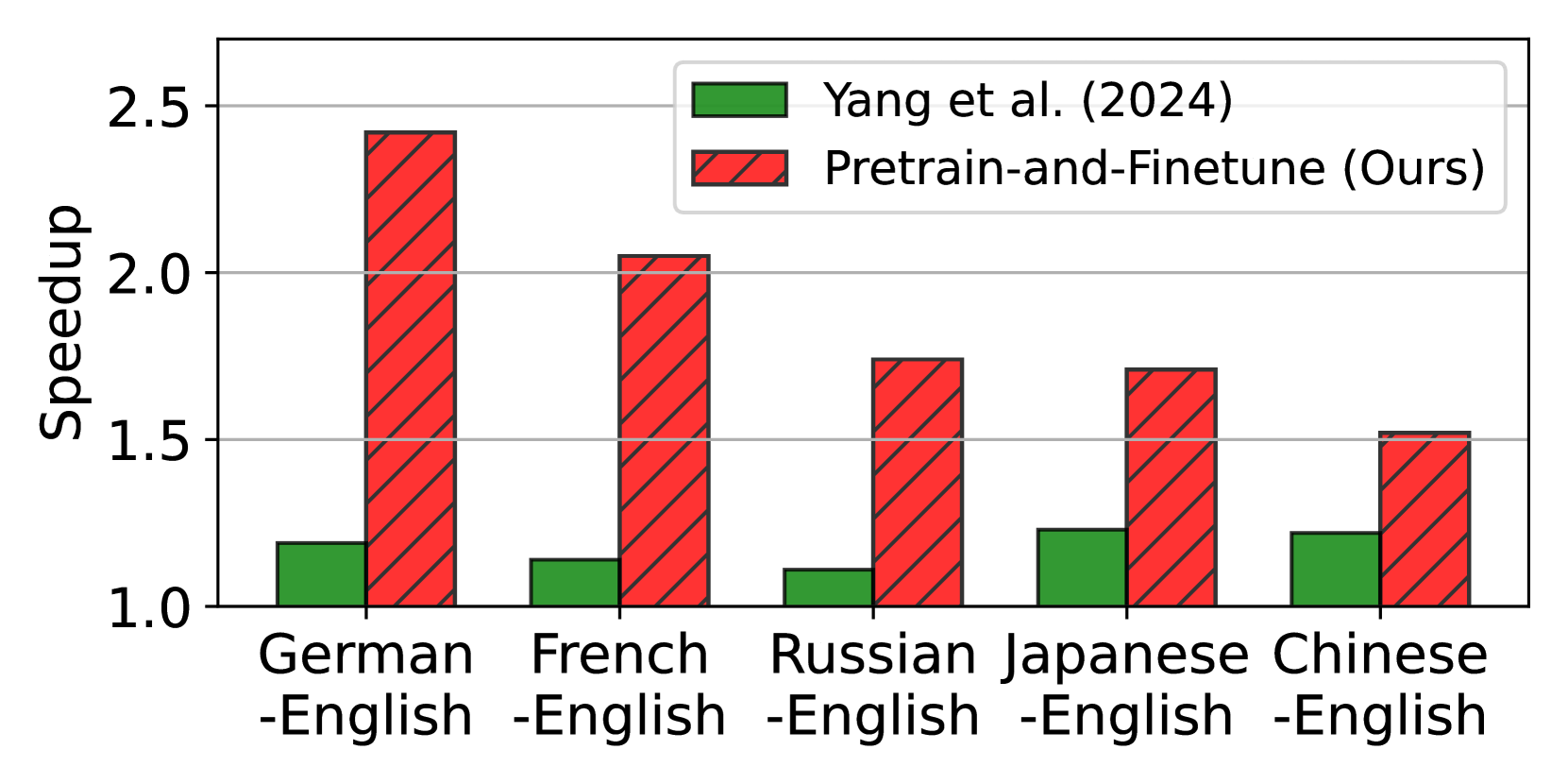
Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
Euiin Yi, Taehyeon Kim, Hongseok Jeung, Du-Seong Chang, Se-Young Yun
Large language models (LLMs) have revolutionized natural language processing and broadened their applicability across diverse commercial applications. However, the deployment of these models is constrained by high inference time in multilingual settings. To mitigate this challenge, this paper explores a training recipe of an assistant model in speculative decoding, which are leveraged to draft and-then its future tokens are verified by the target LLM. We show that language-specific draft models, optimized through a targeted pretrain-and-finetune strategy, substantially brings a speedup of inference time compared to the previous methods. We validate these models across various languages in inference time, out-of-domain speedup, and GPT-4o evaluation.
Read more6/26/2024

0
Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding
Benjamin Bergner, Andrii Skliar, Amelie Royer, Tijmen Blankevoort, Yuki Asano, Babak Ehteshami Bejnordi
Large language models (LLMs) have become ubiquitous in practice and are widely used for generation tasks such as translation, summarization and instruction following. However, their enormous size and reliance on autoregressive decoding increase deployment costs and complicate their use in latency-critical applications. In this work, we propose a hybrid approach that combines language models of different sizes to increase the efficiency of autoregressive decoding while maintaining high performance. Our method utilizes a pretrained frozen LLM that encodes all prompt tokens once in parallel, and uses the resulting representations to condition and guide a small language model (SLM), which then generates the response more efficiently. We investigate the combination of encoder-decoder LLMs with both encoder-decoder and decoder-only SLMs from different model families and only require fine-tuning of the SLM. Experiments with various benchmarks show substantial speedups of up to $4times$, with minor performance penalties of $1-2%$ for translation and summarization tasks compared to the LLM.
Read more7/18/2024