Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding

0

Sign in to get full access
Overview
- This paper proposes a novel approach called "LLM-to-SLM" that enables large language models (LLMs) to quickly generate text using a smaller, specialized language model (SLM).
- The key idea is to leverage the rich knowledge and capabilities of an LLM to initialize and guide the faster, more efficient SLM during autoregressive decoding.
- The authors demonstrate that this LLM-to-SLM approach can significantly accelerate text generation while maintaining high quality, outperforming existing methods for model compression and acceleration.
Plain English Explanation
The paper tackles the challenge of making large language models (LLMs) faster at generating text. LLMs, like GPT-3, are powerful at tasks like writing and translation, but they can be slow and computationally intensive.
The researchers developed a new technique called "LLM-to-SLM" that uses a two-stage approach. First, they train a large, powerful LLM to have rich knowledge and capabilities. Then, they use that LLM to initialize and guide a smaller, more efficient specialized language model (SLM) during the actual text generation process.
The key insight is that the LLM can provide the SLM with high-quality starting points and helpful direction, allowing the SLM to generate text much faster than the original LLM. This LLM-to-SLM approach was shown to significantly speed up text generation while preserving the quality, outperforming other techniques for compressing and accelerating language models.
By combining the strengths of large and small language models, this method offers a way to have the best of both worlds - the rich capabilities of an LLM and the fast, efficient text generation of an SLM.
Technical Explanation
The paper presents a novel approach called "LLM-to-SLM" that aims to leverage the capabilities of large language models (LLMs) to enable faster autoregressive decoding with smaller, specialized language models (SLMs).
The key idea is to first train a powerful LLM, such as GPT-3, to acquire rich knowledge and broad capabilities. Then, instead of directly using the LLM for text generation, the authors propose initializing and guiding an SLM with the LLM's representations and parameters.
This two-stage approach allows the SLM to benefit from the LLM's learned knowledge and generation skills, while the SLM's more efficient architecture can enable much faster autoregressive decoding compared to the original LLM.
The authors evaluate their LLM-to-SLM method on various text generation tasks and show that it can significantly accelerate decoding speed without sacrificing quality. Compared to prior work on model compression and acceleration, such as draft-verify-lossless-large-language-model-acceleration and slmrec-empowering-small-language-models-sequential-recommendation, the LLM-to-SLM approach demonstrates superior performance.
The authors also investigate the behavior of the SLM during the decoding process, shedding light on how it leverages the LLM's knowledge and guidance to generate high-quality text efficiently.
Critical Analysis
The LLM-to-SLM approach presented in this paper addresses an important challenge in language modeling - how to achieve fast, efficient text generation while maintaining the rich capabilities of large language models.
One key strength of the proposed method is its ability to bridge the gap between the high-quality generation of LLMs and the faster decoding speed of smaller models. By transferring knowledge from the LLM to the SLM, the authors overcome limitations of previous model compression and acceleration techniques, as highlighted by the comparisons to related work.
However, the paper could have delved deeper into potential limitations or caveats of the LLM-to-SLM approach. For example, it's unclear how the method would scale to extremely large LLMs or how sensitive the performance is to the specific architectures and training configurations of the LLM and SLM.
Additionally, the paper does not extensively explore the generalization capabilities of the SLM beyond the tasks and datasets used in the experiments. Investigating the SLM's robustness and ability to handle diverse text generation scenarios would further strengthen the claims about the approach's practical utility.
Despite these minor shortcomings, the LLM-to-SLM technique represents a promising step towards balancing the competing objectives of model capability and inference efficiency in the field of natural language processing. The authors have made a valuable contribution by demonstrating the effectiveness of this novel approach.
Conclusion
The paper introduces a novel "LLM-to-SLM" method that leverages the capabilities of large language models (LLMs) to enable faster and more efficient text generation using smaller, specialized language models (SLMs).
By initializing and guiding the SLM with the knowledge and representations learned by a powerful LLM, the researchers have shown that the SLM can achieve significant acceleration in autoregressive decoding while maintaining high-quality text generation.
This work addresses an important challenge in language modeling and offers a compelling approach to bridge the gap between the capabilities of large, complex models and the inference efficiency of smaller, more specialized models. The LLM-to-SLM technique holds promise for a wide range of practical applications that require fast and high-quality text generation, such as when-linear-attention-meets-autoregressive-decoding-towards, cllms-consistency-large-language-models, and investigating-decoder-only-large-language-models-speech.
As language models continue to grow in size and capability, approaches like LLM-to-SLM will become increasingly important for balancing performance and efficiency, paving the way for more practical and accessible language AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding
Benjamin Bergner, Andrii Skliar, Amelie Royer, Tijmen Blankevoort, Yuki Asano, Babak Ehteshami Bejnordi
Large language models (LLMs) have become ubiquitous in practice and are widely used for generation tasks such as translation, summarization and instruction following. However, their enormous size and reliance on autoregressive decoding increase deployment costs and complicate their use in latency-critical applications. In this work, we propose a hybrid approach that combines language models of different sizes to increase the efficiency of autoregressive decoding while maintaining high performance. Our method utilizes a pretrained frozen LLM that encodes all prompt tokens once in parallel, and uses the resulting representations to condition and guide a small language model (SLM), which then generates the response more efficiently. We investigate the combination of encoder-decoder LLMs with both encoder-decoder and decoder-only SLMs from different model families and only require fine-tuning of the SLM. Experiments with various benchmarks show substantial speedups of up to $4times$, with minor performance penalties of $1-2%$ for translation and summarization tasks compared to the LLM.
Read more7/18/2024

0
When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models
Haoran You, Yichao Fu, Zheng Wang, Amir Yazdanbakhsh, Yingyan Celine Lin
Autoregressive Large Language Models (LLMs) have achieved impressive performance in language tasks but face two significant bottlenecks: (1) quadratic complexity in the attention module as the number of tokens increases, and (2) limited efficiency due to the sequential processing nature of autoregressive LLMs during generation. While linear attention and speculative decoding offer potential solutions, their applicability and synergistic potential for enhancing autoregressive LLMs remain uncertain. We conduct the first comprehensive study on the efficacy of existing linear attention methods for autoregressive LLMs, integrating them with speculative decoding. We introduce an augmentation technique for linear attention that ensures compatibility with speculative decoding, enabling more efficient training and serving of LLMs. Extensive experiments and ablation studies involving seven existing linear attention models and five encoder/decoder-based LLMs consistently validate the effectiveness of our augmented linearized LLMs. Notably, our approach achieves up to a 6.67 reduction in perplexity on the LLaMA model and up to a 2$times$ speedup during generation compared to prior linear attention methods. Codes and models are available at https://github.com/GATECH-EIC/Linearized-LLM.
Read more7/26/2024

0
CLLMs: Consistency Large Language Models
Siqi Kou, Lanxiang Hu, Zhezhi He, Zhijie Deng, Hao Zhang
Parallel decoding methods such as Jacobi decoding show promise for more efficient LLM inference as it breaks the sequential nature of the LLM decoding process and transforms it into parallelizable computation. However, in practice, it achieves little speedup compared to traditional autoregressive (AR) decoding, primarily because Jacobi decoding seldom accurately predicts more than one token in a single fixed-point iteration step. To address this, we develop a new approach aimed at realizing fast convergence from any state to the fixed point on a Jacobi trajectory. This is accomplished by refining the target LLM to consistently predict the fixed point given any state as input. Extensive experiments demonstrate the effectiveness of our method, showing 2.4$times$ to 3.4$times$ improvements in generation speed while preserving generation quality across both domain-specific and open-domain benchmarks.
Read more6/14/2024
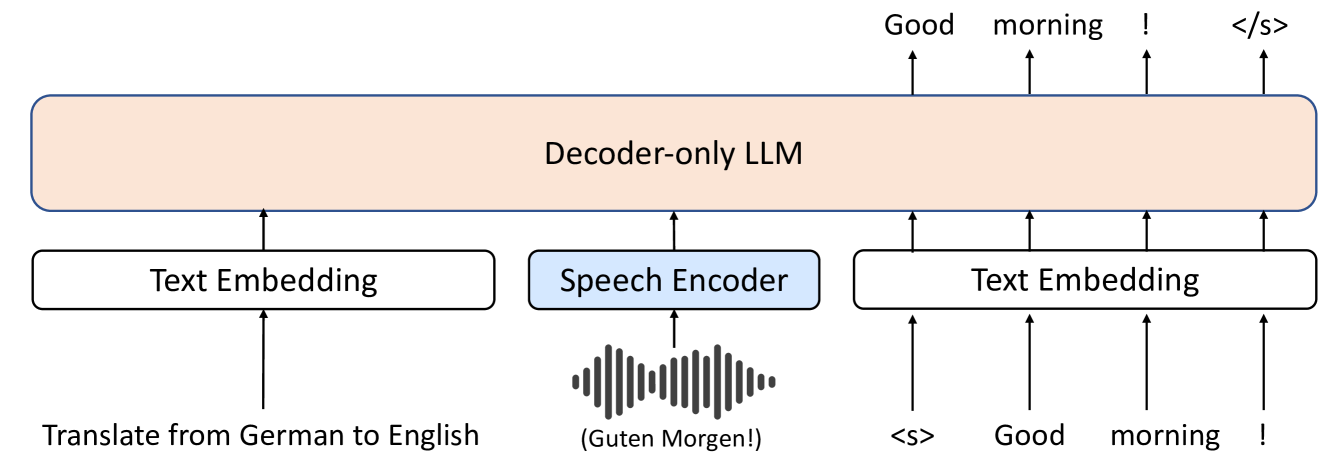
0
Investigating Decoder-only Large Language Models for Speech-to-text Translation
Chao-Wei Huang, Hui Lu, Hongyu Gong, Hirofumi Inaguma, Ilia Kulikov, Ruslan Mavlyutov, Sravya Popuri
Large language models (LLMs), known for their exceptional reasoning capabilities, generalizability, and fluency across diverse domains, present a promising avenue for enhancing speech-related tasks. In this paper, we focus on integrating decoder-only LLMs to the task of speech-to-text translation (S2TT). We propose a decoder-only architecture that enables the LLM to directly consume the encoded speech representation and generate the text translation. Additionally, we investigate the effects of different parameter-efficient fine-tuning techniques and task formulation. Our model achieves state-of-the-art performance on CoVoST 2 and FLEURS among models trained without proprietary data. We also conduct analyses to validate the design choices of our proposed model and bring insights to the integration of LLMs to S2TT.
Read more7/4/2024